



在对上一节的文本数据(即README.md文件的数据)进行初步的ETL操作之后,就可以开始进行数据统计、挖掘等操作了,这里主要介绍数据的一些统计操作,以及为了加快统计效率而使用的持久化操作。
1.使用count方法统计textFile的元素个数,即文件行数,执行结果如下:
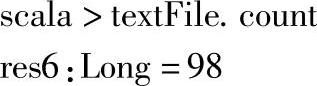
可以看到文件的行数为98。
2.获取单词个数最多的行的单词个数。
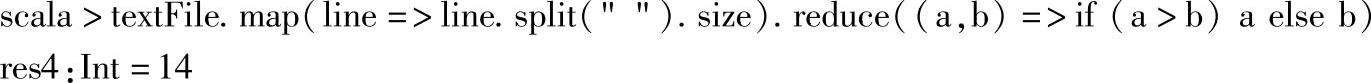
其中:
1)map方法是针对RDD的每个元素执行map函数,并返回处理后的新RDD。map(line=>line.split("").size)操作是对每个元素按空格进行split后,再获取split得到的数组的长度,其结果就是将RDD的元素转换为元素包含的单词的个数。
2)reduce是先对RDD每个分区的数据进行归并操作,最终对每个分区数据的归并结果再次进行归并。reduce((a,b)=>if(a>b)a else b)是获取map后RDD元素的最大值。这里是比较每行包含的单词个数。
查看map后每行数据的单词个数,单词个数最多的为14,执行结果如下所示:

改用Math方法获取最大值,执行结果如下所示:
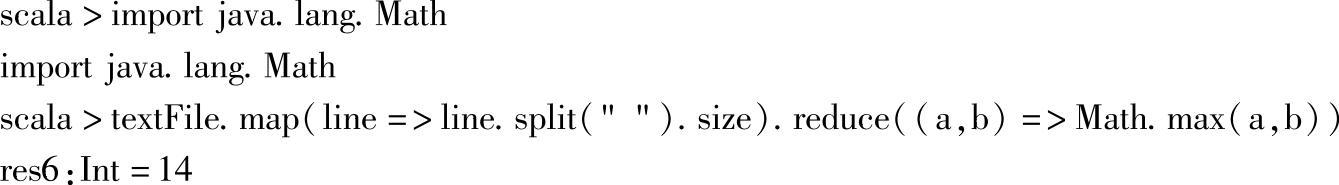
Scala编译后也是.class文件,在JVM中运行,因此可以调用同样编译成.class文件的java类,即可以使用已有的java类库,这里使用了java.lang.Math中的Math.max方法。
3.实现WordCounts(单词统计),并获取统计结果,输入命令,查看命令结果:
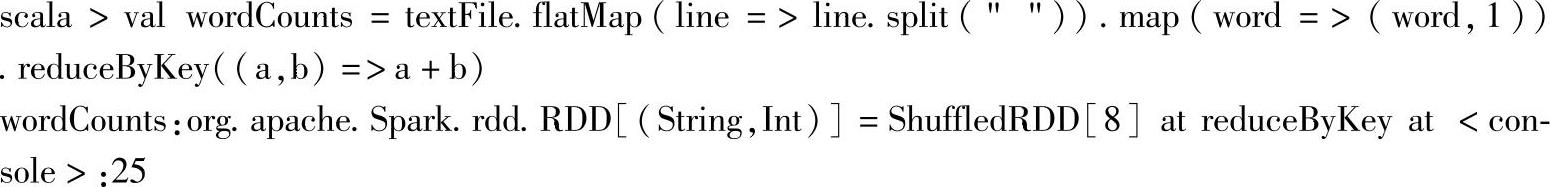
其中:
1)flatMap(line=>line.split("")),flatMap操作,相当于先将元素map一个数据集,然后把数据集flap,即扁平化处理。案例中,是将textFile的元素,即输入文件的每一行,按空格("")进行拆分,得到单词数组,最后将数组进行扁平化后textFile的元素变为单词字符串。
2)map方法在这里是将RDD的每个元素转换为一个二元组,二元组包含一个单词和初始统计值1。(https://www.xing528.com)
3)reduceByKey方法和reduce方法一样,只是针对相同Key值的value进行归并操作。在这里针对相同元素,即相同单词进行归并(即求和),最后得出单词的个数统计值。
通过collect方法查看wordCounts的内容,执行结果如下:

4.对每行单词个数求top,执行结果如下:
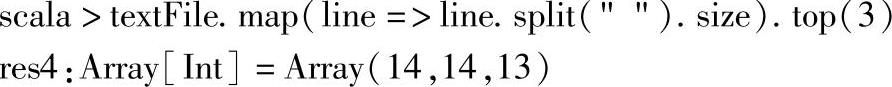
这里将textFile的每条记录,即文件的每一行,map为单词个数,然后求出单词个数排前三的个数值。
5.测试textFile的缓存。为了测试缓存时间的变化,修改日志等级进行调试,语句如下:
测试过程:先执行textFile.count统计元素个数,然后缓存textFile,并用collect触发,触发后再次执行textFile.count命令,比对缓存前后,元素个数统计所消耗的时间。依次输入命令:

其中:
1)cache方法:将RDD缓存到内存中,即persist(StorageLevel.MEMORY_ONLY)的缩写,是一个lazy操作(一旦存储等级被改变,必须先调用unpersist去除后才能重新设置新的存储等级)。
2)collect方法:这是一个Action操作。会获取RDD的全部元素,并转换为Scala Array返回给Driver Program,collect方法中还可以添加一个偏函数对返回的数据进行预处理,处理得到的类型可以和RDD的元素类型不同。通常情况下,在RDD数据量大时应避免使用该方法,避免在Driver Program中内存不足以装载全部元素而导致的内存溢出问题。
如图2.12所示,缓存前,统计时间为0.085439s,缓存后的统计时间为0.047926s。

图2.12 RDD缓存及其触发过程的日志截图
对RDD进行缓存后,可以极大提高RDD的统计效率,减少多次对RDD统计时重新计算RDD的开销。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。