



Spark SQL提供了两种方式从各种数据源加载数据以构建DataFrame,可以使用特定的方法或通用的方法以默认的数据源来直接加载数据源,也可以通过指定具体数据源的方法,用通用的方法来加载数据。
同时Spark SQL也提供DataFrame的持久化操作。
这部分内容介绍了如何加载和持久化DataFrame。为了方便查看反馈信息,以交互式方式启动Spark。
一、加载/保存数据源的最简单的方式
加载、保存DataFrame的最简单的方式是使用默认的数据源来进行所有操作。默认的数据源是内置的“parquet”数据源,可以通过修改配置sparkSpark.sql.sources.default将其他数据源作为默认值。
1.使用针对特定数据源的方法
下边介绍SQLContext提供的针对特定数据源加载文件的方法,包括加载方法和保存方法。
1)加载数据源,代码如下所示:
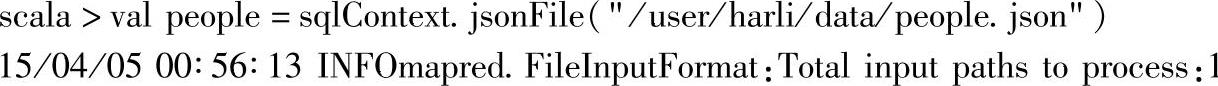

这里使用了两种方法,jsonFile和parquetFile,分别加载“json”和“parquet”的数据源。
2)保存DataFrame实例到数据源,代码如下所示:
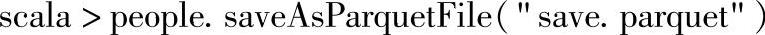
查看Web Interface界面,如图3.13所示。

图3.13 Hadoop文件系统在saveAsParquetFile后的界面
当前没有指定具体路径,在使用HDFS作为存储系统时,默认会放在HDFS文件系统中当前用户的目录下,即/user/harli目录,在指定的路径目录下,可以看到文件已经保存成功。
注意:如果目录以/开头,则对应的是HDFS的根目录(对应core-site.xml中的fs.defaultFS配置属性),而非当前用户所在目录下。比如/tmp,对应为hdfs∶//namenode∶port/tmp。其中namenode为启动Na-meNode进程的节点,当前环境下的节点地址为192.168.70.214。
2.使用默认数据源的方法
1)确认默认的数据源是否已经设置。可以通过查询当前的默认配置,确保是默认的“parquet”数据源,命令行输入如下:
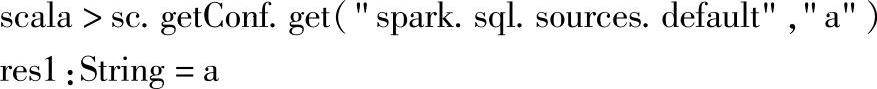
可以看到,当前没有设置默认的数据源,此时如果使用默认数据源去加载(或者保存)的话会报错。
通过spark-shell的-conf选项以Key=Value的形式来设置默认数据源参数,重新启动spark-shell:
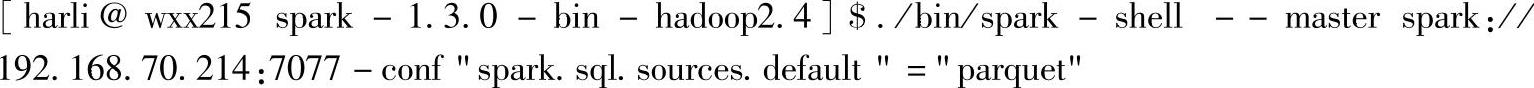
这里使用-conf选项将配置属性spark.sql.sources.default设置为parquet,进入交互式界面后,重新查询该属性值,语句如下:
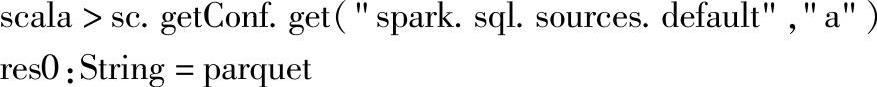
默认数据源已经成功设置。
2)加载数据源。以默认的数据源“parquet”加载文件:

可以继续从加载后的people中选取某些列,然后保存到默认数据源上,如:

这里从df中选取了“name”,“age”两列信息,然后保存到HDFS文件系统中当前用户的目录下的“namesAndAges.parquet”目录中。
通过Web Interface(http∶//namenode∶50070)界面查看文件信息,如图3.14所示。
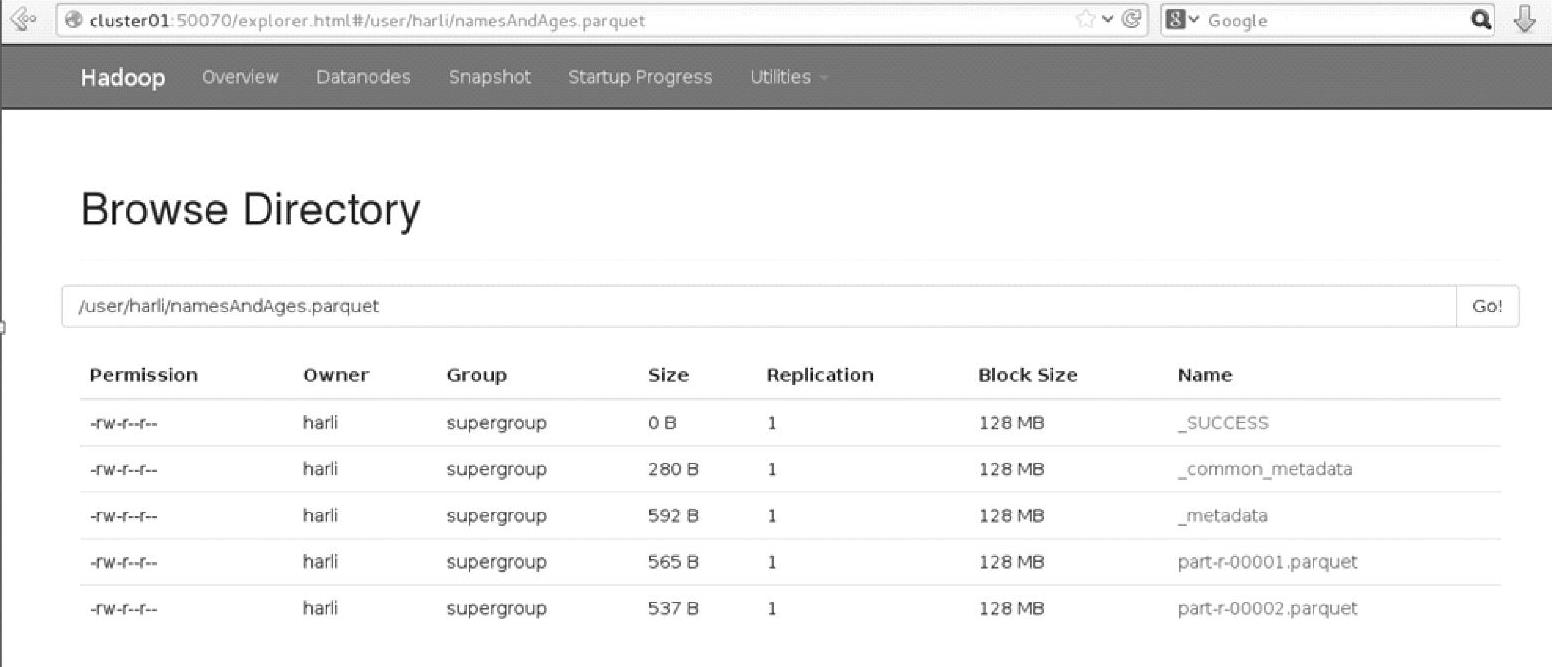
图3.14 hadoop文件系统在save后的界面(https://www.xing528.com)
然后将整个people保存为parquet格式,目录为people.parquet:

这里可以看到,输入文件的类型为FileInputFormat,通过hadoop.ParquetFileReader读取,读取后的并行度(parallelism)为5。
二、指定数据源的方式
1.指定数据源加载文件
这里使用load方法,加载文件people.json,对应数据源为“json”。

这里使用load方法,加载文件people.parquet,对应数据源为“parquet”。

2.指定数据源保存文件
将加载后的people保存到HDFS文件系统当前用户的目录下的“save.json”目录中,保存为json文件:
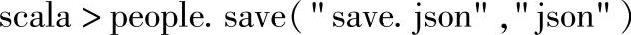
通过Web Interface(http∶//namenode∶50070)界面查看文件信息,如图3.15所示。
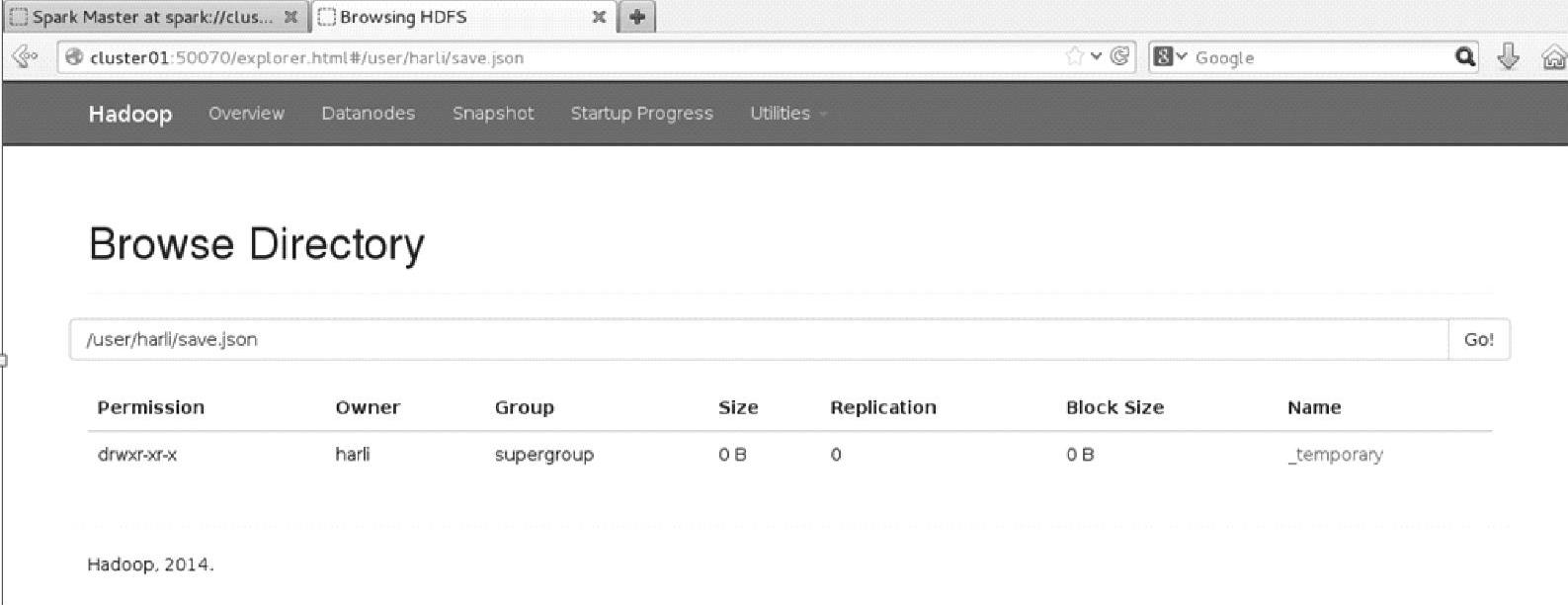
图3.15 Hadoop文件系统在save后的界面
三、保存模式(SaveModes)
保存操作时可选择保存模式方式,来指定如果现有数据已经存在的话该如何处理。重要的是要意识到这些保存模式不使用任何锁操作,而且也不具备原子性。因此,当尝试对同一位置进行多个写操作时,写操作是不安全的。另外,当执行一个覆盖操作(SaveMode.Overwrite)时,在写新数据之前会先删除原有数据。具体的保存模型参考表3.2的内容。
表3.2 保存模式及其含义
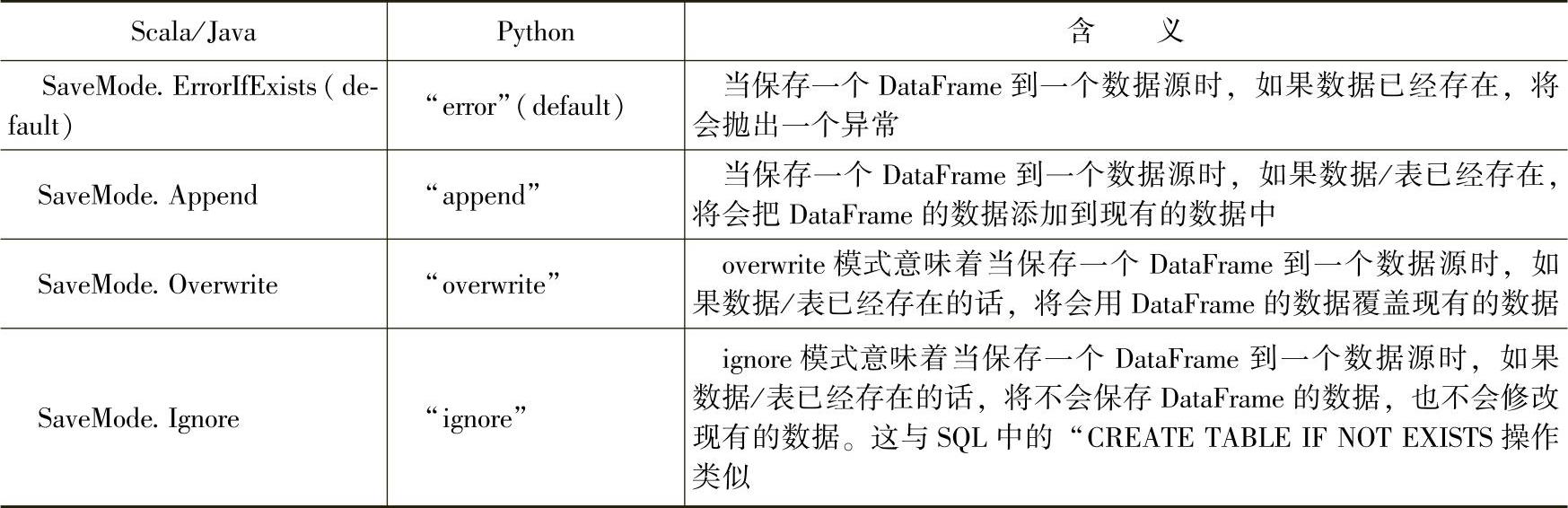
在实际保存操作中,需要注意各种数据源对保存模式使用的限制,比如“parquet”类型的数据源当前只支持overwrite的保存模式,当使用其他保存模式时会报不支持的错误。
四、保存到持久化的表中
先加载文件到people中:

使用saveAsTable方法,将people保存到表people中:

持久化到表中和注册为临时表是不一样的,临时表在应用退出后会自动销毁,而持久化到表中是持久化到存储系统上,应用退出后不会销毁。
保存后的Web Interface界面,如图3.16所示。
如图所示,保存后自动创建了目录hive及其子目录warehouse,并在该子目录下生成了保存表people的目录。
五、应用场景
1.Spark SQL应用程序可以集成各种类型的数据源,包含不同数据源之间的存储转换、格式转换等,比如,将json文件格式转换为parquet格式,将HDFS上的json文件存储到jdbc中等。
2.基于“one stack to rule them all”的思想,Spark中的各个子框架和库之间可以实现无缝的数据共享和操作,而基于Spark SQL对各种数据源的支持,同时就是为其他各个子框架,Spark Streaming、MLlib、GraphX提供了各种数据源的支持。因此,在其他子框架需要时,可以使用Spark SQL来加载或持久化数据。
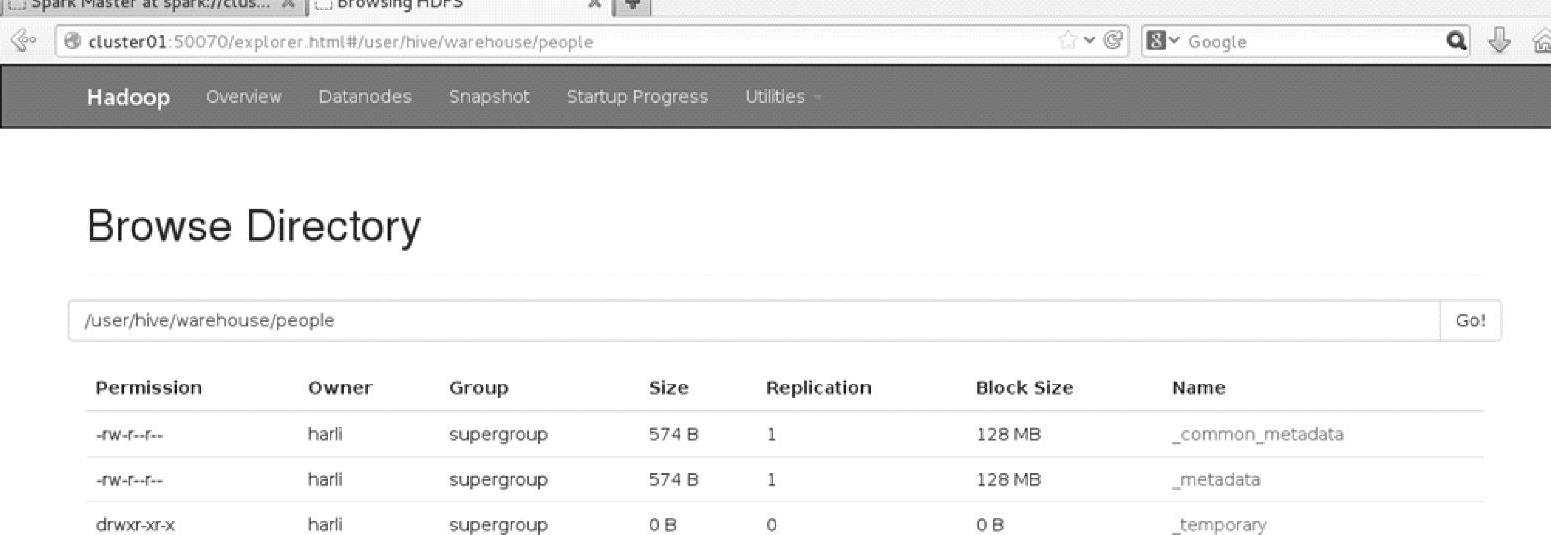
图3.16 Hadoop文件系统在持久化到表后的界面
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。