



Spark在运行中通过算子对RDD进行计算,算子是RDD中定义的函数,可以对RDD中的数据进行转换和操作,如图1-4所示。
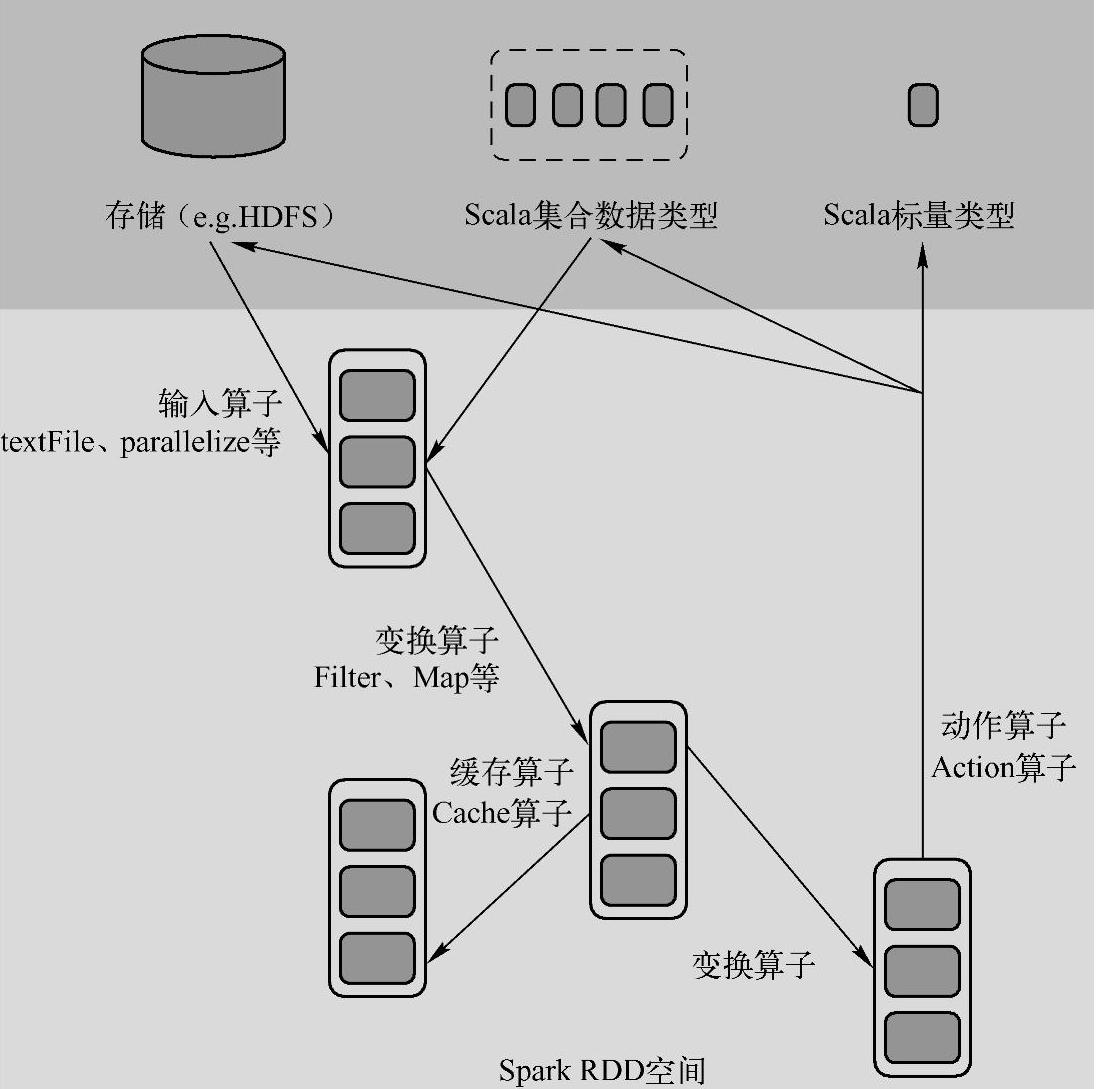
图1-4 RDD中的算子运算流程图
1.输入
在Spark程序运行中,数据从外部数据空间(如分布式存储:textFile读取HDFS等,parallelize方法输入Scala集合或数据)输入Spark,数据进入Spark运行时数据空间,转换为Spark中的数据块,通过BlockManager进行管理。
2.运行
在Spark数据输入形成RDD后,可以通过变换算子(Transformation算子),如filter等,对数据进行操作,并将RDD转化为新的RDD,通过Action算子,触发Spark提交作业。如果数据需要复用,可以通过Cache算子将数据缓存到内存中。
3.输出
程序运行结束后数据会输出Spark运行时的空间,存储到分布式存储中(如saveAsText-File输出到HDFS),或Scala类型的数据或集合中(collect输出到Scala集合,count返回Scala int型数据)。
Spark中生成的不同RDD中,有的和用户逻辑显示的对应,如map操作生成MapParti-tionsRDD,而有的RDD则是Spark框架帮助用户隐式生成的,如reduceByKey操作时的Shuf-fleRDD等。Spark的核心数据模型是RDD,但RDD是一个抽象类,具体由各子类实现,如MappedRDD、ShuffledRDD等子类。在Spark的reduceByKey操作时会触发Shuffle的过程,在Shuffle之前,会有本地的聚合过程产生MapPartitionsRDD,接着具体Shuffle会产生Shuf-fledRDD,之后做全局的聚合生成结果MapPartitionsRDD。Spark将常用的大数据操作都转化成RDD的子类,如图1-5所示。(https://www.xing528.com)
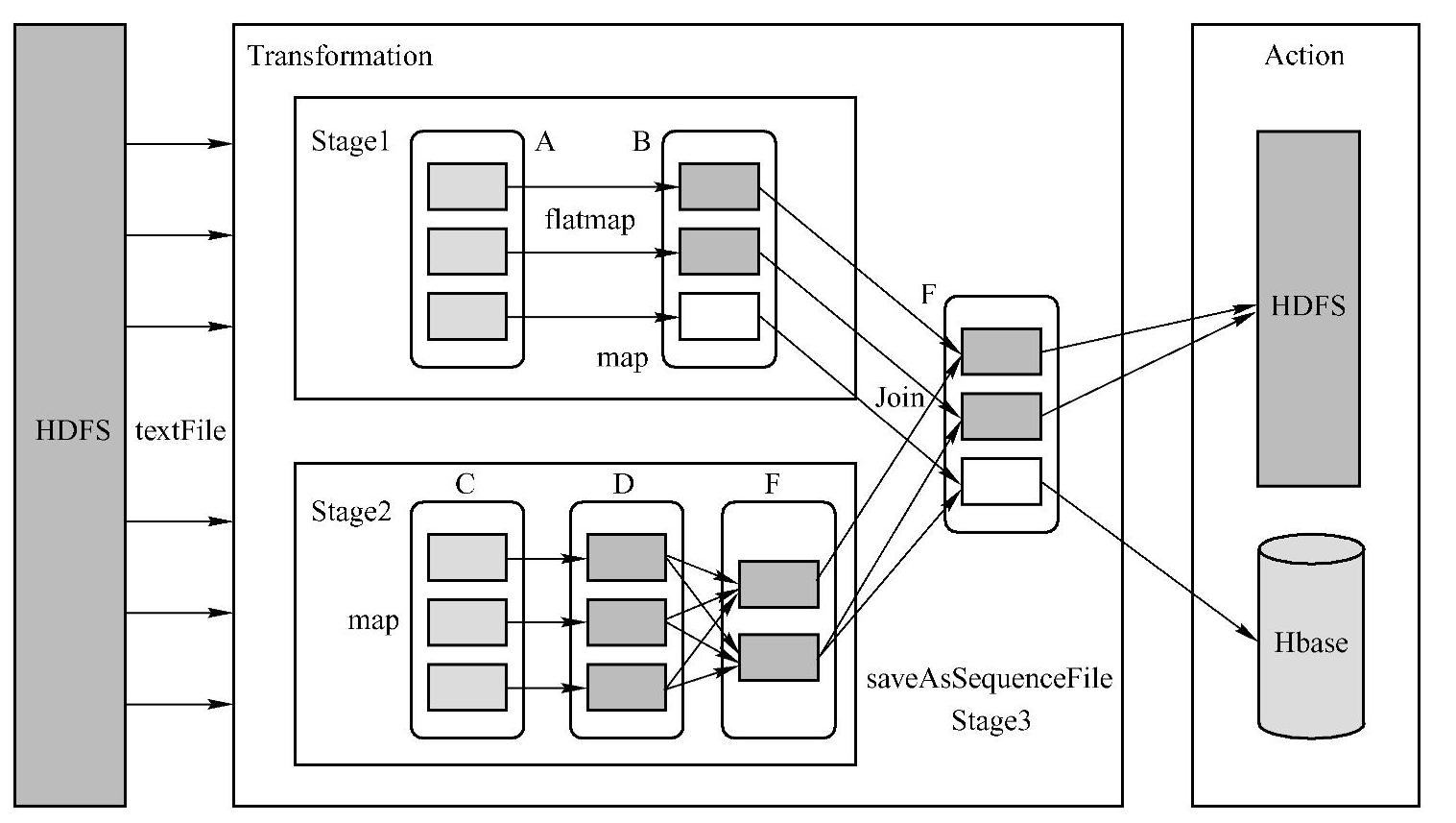
图1-5 Spark操作数据模型图
SparkRDD中的算子大致可分为下列三大类。
1)Value数据类型的Transformation算子,这种变换并不触发提交作业,针对处理的数据项是Value型的数据。
2)Key-Value数据类型的Transfromation算子,这种变换并不触发提交作业,针对处理的数据项是Key-Value型的数据对。
3)Action算子,这类算子会触发SparkContext提交Job作业,一个Job包含多个Stage(至少一个Stage),Stage内部由一组完全相同的Task构成,这些Task只是处理的数据不同;一个Stage的开始就是从外部存储或者Shuffle结果中读取数据,一个Stage的结束是由于要发送Shuffle或者生成最终的计算结果。
对于Spark中的Join操作,如果每个Partition仅仅和特定的Partition进行Join,那么就是窄依赖;对于需要parent RDD所有的partition进行Join的操作,即需要Shuffle,此时就是宽依赖。RDD的saveAsTextFile方法会首先生成一个MapPartitionsRDD,该RDD通过调用PairRDDFunctions的saveAsHadoopDataset方法向HDFS等输出RDD数据的内容,并在最后调用SparkContext的runJob来真正向Spark集群提交计算任务。
默认情况下,每一个Transformaton过的RDD会在每次Action时重新计算一次,然而,可以使用Persist(或Cache)持久化一个RDD到内存中,可进行复用。根据Action算子的输出空间将Action算子进行分类:无输出、HDFS、Scala集合和数据类型,RDD模型适合粗粒度的全局数据并行计算,不支持细粒度的异步更新操作和增量迭代计算。
基于RDD的整个计算过程都是发生在Worker中的Executor中的。RDD支持3种类型的操作:Transformation、Action,以及以Persist和CheckPoint为代表的控制类型的操作。RDD一般会从外部数据源读取数据,经过多次RDD的Transformation(中间为了容错和提高效率,有可能使用Persist和CheckPoint),最终通过Action类型的操作一般会把结果写回外部存储系统。Spark Checkpoint通过将RDD写入磁盘做检查点,是Spark Lineage容错机制的辅助,Lineage过长会造成容错成本过高,此时在中间阶段做检查点容错,如果之后有结点出现问题而丢失分区,从检查点的RDD开始重做Lineage就会减少开销。Checkpoint主要适用于以下两种情况:①DAG中的Lineage过长,若重算开销会太大,如在PageRank、ALS等;②尤其适合于在宽依赖上做Checkpoint,这个时候就可以避免为Lineage重新计算而带来的冗余计算。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。