



虽然Spark是基于内存进行计算,但RDD的数据集不仅可以存储在内存中,还可以使用RDD类的persist方法和cache方法将RDD的数据集缓存到内存、磁盘或者Tachyon文件系统中。下面我们看一下persist方法和cache方法的源代码,对其特点做一下分析。

由persist方法的注释我们知道,当RDD第一次被计算时,persist方法会根据参数Stor-ageLevel的设置采取特定的缓存策略。它只适合于原本StorageLevel的变量为None或者新传递进来的StorageLevel值与原来的StorageLevel值相等的情况。persist操作是control操作的一种,它只是改变了原RDD的元数据信息,并没有生成新的RDD。
对于cache方法而言,它只是persist方法的一个特例,即persist方法的参数为MEMORY_ONLY的情况。我们可以看下cache的源码。

根据useDisk(使用磁盘)、useMemory(使用内存)、useOffHeap(使用Tachyon文件系统),deserialized(反序列化)、replication(文件副本数)五个参数的组合,Spark提供了12种存储级别的缓存策略,这可以使我们能将RDD持久化到内存、磁盘,或者是以序列化的方式持久化到内存中,甚至可以在集群的不同结点之间存储多份复制。这些缓存策略都被包含在类org.apache.spark.storage.StorageLevel中。
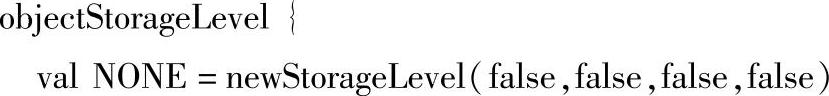

可选用的存储级别如表5-1所示。
表5-1 存储级别(https://www.xing528.com)

存储级别选择原则如下:
Spark的不同存储级别,旨在满足内存使用和CPU效率权衡上的不同需求。建议通过以下步骤来进行选择:
(1)如果RDD可以很好的与默认的存储级别MEMORY_ONLY契合,就不需要做任何调整,这已经是CPU使用效率最高的选项,它使得RDD的操作尽可能的快。
(2)如果RDD无法与默认的存储级别MEMORY_ONLY契合,试着使用MEMORY_ON-LY_SER,并且选择一个快速序列化的库使得对象在比较高的空间使用率下,依然可以较快的被访问。
(3)RDD尽可能的不要存储在硬盘中,除非计算数据集的函数计算量特别大,或者这些函数过滤了大量的数据,否则重新计算一个分区的速度和从与硬盘中读取基本差不多快。
(4)Spark默认存储策略为MEMORY_ONLY:只缓存到内存并且以原生方式存(反序列化)一个副本。
(5)MEMORY_AND_DISK存储级别在内存够用时直接保存到内存中,只有当内存不足时,才会存储到磁盘中。
(6)如果想确保高效的容错,除了依靠RDD的血统重新计算丢失的分区,还可以采用replication大于1(也即多份复制,这个replication的实际值可以通过设置StorageLevel类的成员_replication来实现),到时可以直接从其他结点获取数据。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。