



尽管可以使用IDEA直接导入Spark源码和构建项目,但在实际编译过程中,会出现许多异常和错误,解决步骤也比较烦琐,因此建议读者先在命令行下使用Maven或者SBT编译整个项目,再在IDEA中导入编译好的项目文件。对直接使用集成开发环境(Integrated Development Environment,IDE)编译源码感兴趣的读者也可以参考官方提供文档(http://spark.apache.org/docs/latest/building-spark.html)中的Building Spark with IntelliJ IDEA or Eclipse小节。
1.下载Spark源码
访问Spark下载页,这次不选择预编译的二进制包,而是选择下载Source Code[Can build several Hadoop versions],如图2-24所示。执行命令“tar-zxvf spark-1.4.1.tgz”解压缩下载好的源码包。
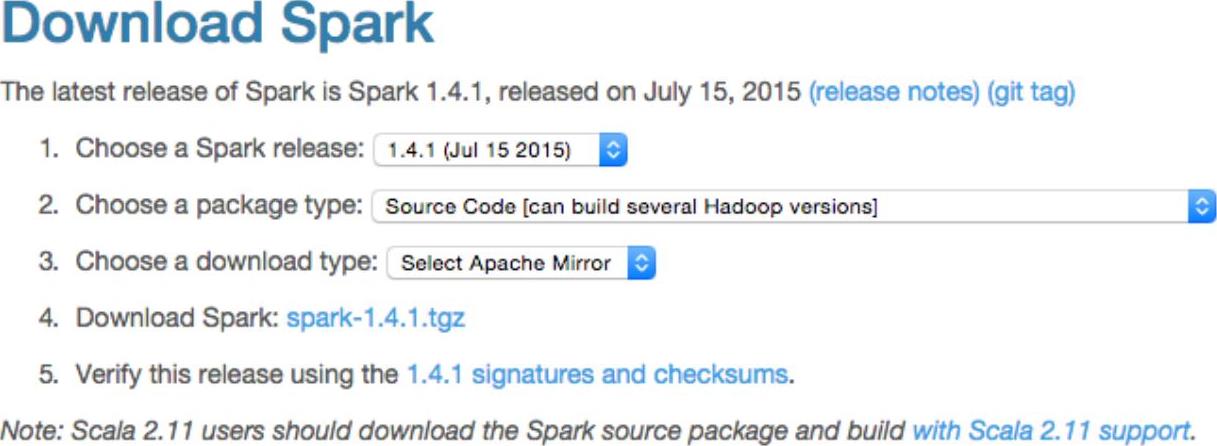
图2-24 下载Spark源码
2.设置Maven内存限制
官方推荐使用Maven来编译项目,由于Maven工具默认分配的内存比较小,因此需要将其内存上限调整为一个合适值,执行的命令如下。
$export MAVEN_OPTS="-Xmx2g-XX:MaxPermSize=512M-XX:ReservedCodeCacheSize=512m"
3.编译源码与构建发行版
Spark允许使用Maven、SBT以及Zinc数据库来编译源码和构建项目,源码目录下的build子目录内提供了相应的Shell脚本文件,用于检查系统中是否已经存在所需的构建工具,如果没有的话会自动从网络上下载,此外,当读者使用其中一种工具进行项目构建时,脚本文件会自动下载其他两种构建工具。
以Maven为例,构建一个可适配于Hadoop 2.4版本的Spark的命令如下。(https://www.xing528.com)
$build/mvn-Pyarn-Phadoop-2.4-Dhadoop.version=2.4.0-DskipTests clean package
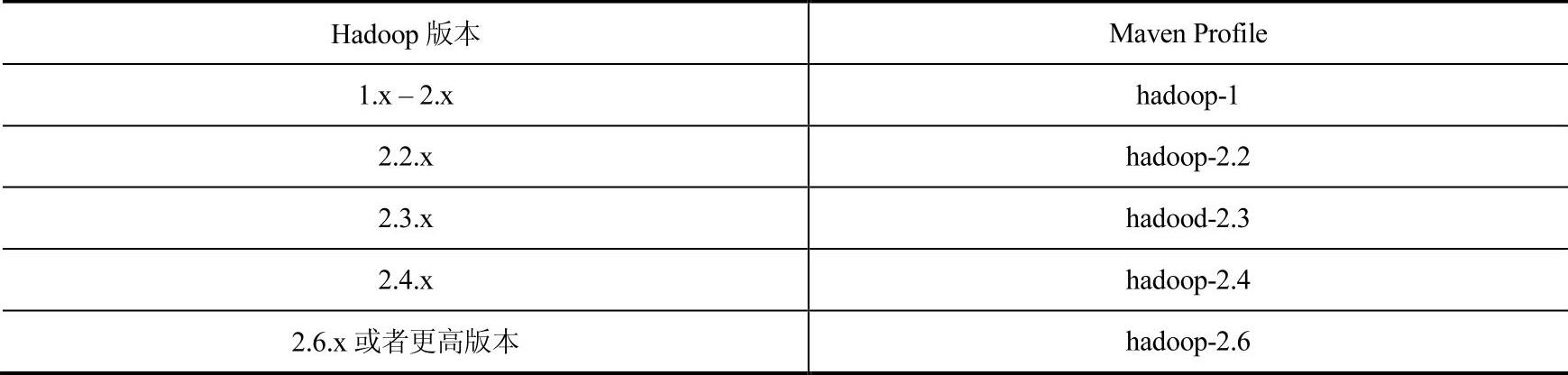
Hadoop版本所对应的Maven版本简介如表2-4所示。其他更多选项与参数读者可参考官方提供的项目构架文档。
表2-4 Hadoop版本对应的Maven版本简介
编译过程中会自动从Maven仓库中下载所需的依赖包,受网络环境影响很大,所耗费的时间也会很长,编者在Ubuntu 14.04中编译整套源码耗时一个小时左右,再次编译源码时,由于无需重新下载依赖包,时间上会快很多。编译完成后的结果如图2-25所示。
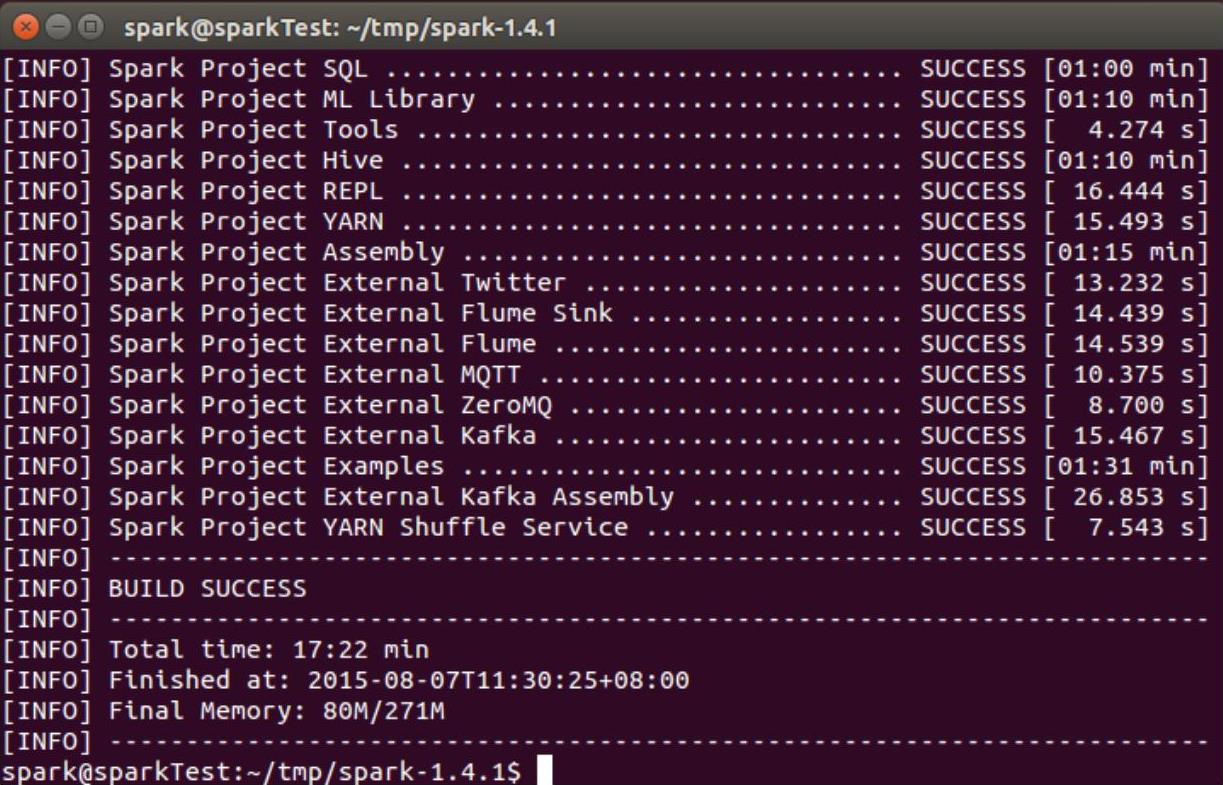
图2-25 编译完结果图
如果读者希望构建一个类似于官方所提供的Spark二进制安装包,可以直接使用make-distribution.sh脚本来完成这个任务。如下命令是一个示例,该脚本会自动调用Maven编译并生成一份适配Hadoop 2.4和Yarn的Spark版本,并生成tar.gz格式的压缩包。更为具体的使用方法读者可以执行命令“./make-distribution.sh-help”查看。
$./make-distribution.sh--name custom-spark--tgz-Phadoop-2.4-Pyarn
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。