



因为Spark程序执行的特性,即延迟执行和基于Lineage最大化的pipeline,当Spark中由于对某个RDD的Action操作触发了作业时,会基于Lineage从后往前推,找到该RDD的源头RDD,然后从前往后计算出结果。很明显,如果对某个RDD执行了多次Transformation 和Action操作,每次Action操作触发了作业时都会重新从源头RDD处计算一遍来获得该RDD,然后再对这个RDD执行相应的操作。当RDD本身计算特别复杂和耗时(如某个计算时长超过半个小时)时,这种方式的性能显然是很差的,此时必须考虑对计算结果的数据进行持久化。
持久化就是将计算出来的RDD根据配置的持久化级别,保存到内存或磁盘中,以后每次对该RDD进行算子操作时,都会直接从内存或磁盘中提取持久化的RDD数据,然后执行算子,而不会从源头处重新计算一遍这个RDD,再执行算子操作,这无疑会提高程序执行的效率。
建议对多次使用的RDD,计算特别复杂和耗时,或计算链条特别长的RDD,进行持久化。只需要对希望缓存的RDD Persist或Cache方法进行标记,这两种方法的区别在于,Cache是将RDD持久化到内存里,而Persist可以指定不同的持久化级别。在标记之后,当由Action触发Job导致了该RDD的计算后,计算结果就会根据指定的持久化级别被持久化到内存或磁盘中。
RDD的各个持久化级别如表9-1所示。
表9-1 RDD的持久化级别
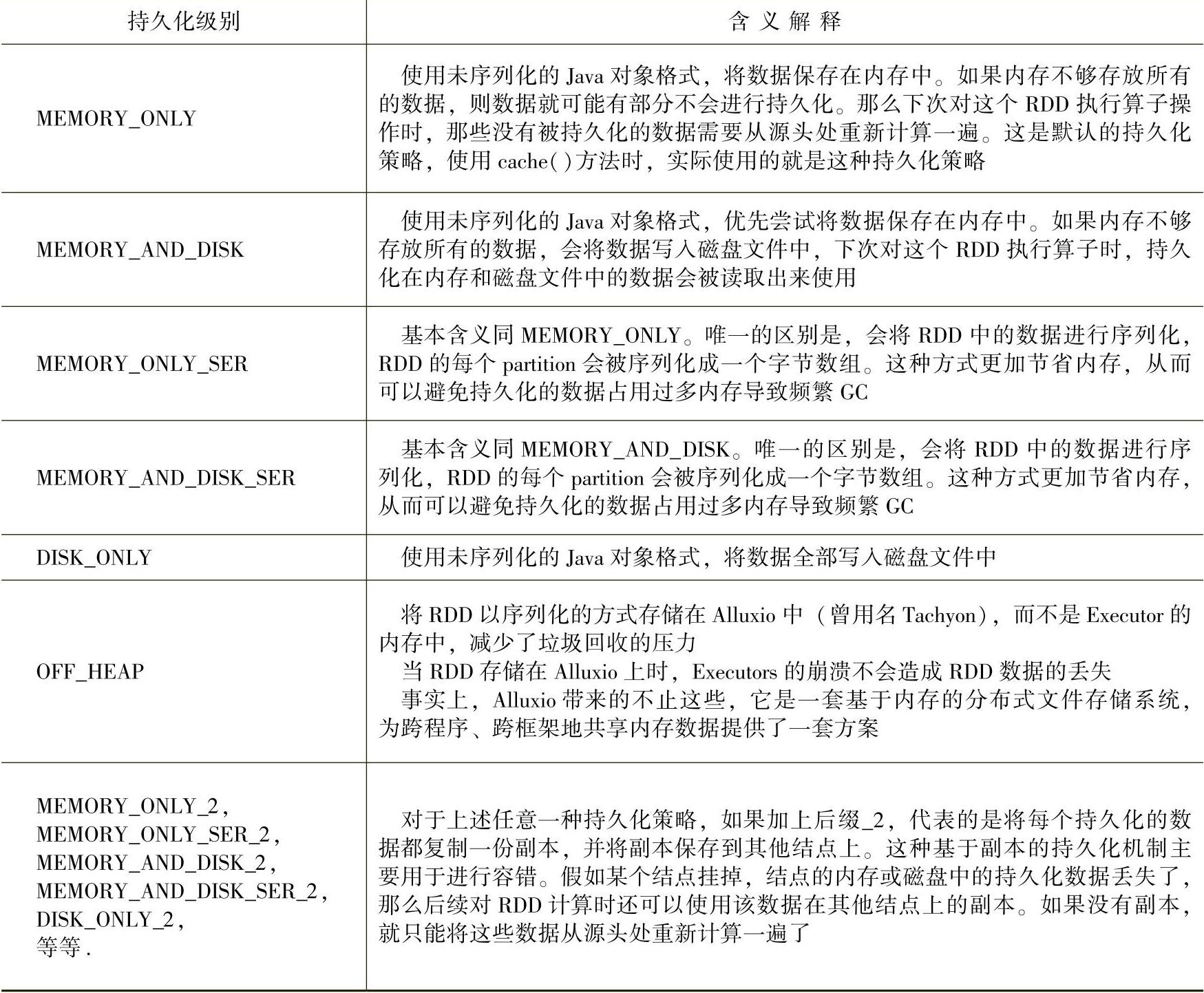
Spark提供了不同的持久化级别,以满足内存使用率和CPU效率的均衡。如何选择合适的持久化级别呢?
通常遵循的准则是,优先考虑内存,内存放不下就考虑序列化后放在内存里,尽量不要存储到磁盘上,因为一般RDD的重新计算比从磁盘中读取更快,只有在需要更快的恢复时才使用备份级别(所有的存储级别都可以通过重新计算来提供全面的容错性,但是备份级别允许用户继续在RDD的备份上执行任务,而无须重新计算丢失的分区)。
按照顺序来讲,通常按照以下方式来选择。
采用默认情况下性能最高的MEMORY_ONLY。该持久化级别下,不需要进行序列化与反序列化操作,就避免了这部分的性能开销;对这个RDD的后续算子操作,都是基于纯内存中的数据的操作,不需要从磁盘文件中读取数据,性能也很高;而且不需要复制一份数据副本,并远程传送到其他结点上。但是这里必须要注意的是,使用该持久化级别的前提是,集群的内存必须足够大,可以绰绰有余地存放整个RDD的所有数据,如果RDD中的数据比较多(比如几十亿条),直接用这种持久化级别可能会导致JVM的OOM内存溢出异常。
如果使用MEMORY_ONLY级别时发生了内存溢出,那么建议尝试使用MEMORY_ONLY_SER级别。该级别会将RDD数据序列化后再保存到内存中,此时每个partition仅仅是一个字节数组而已,大大减少了对象数量,并降低了内存占用。这种级别比MEMORY_ONLY多出来的性能开销,主要就是序列化与反序列化的开销。但是后续算子可以基于纯内存进行操作,因此性能总体还是比较高的。此外,可能发生的问题同上,如果RDD中的数据量过多,还是可能会导致OOM内存溢出的异常。
如果纯内存的级别都无法使用,那么建议使用MEMORY_AND_DISK_SER策略,而不是MEMORY_AND_DISK策略。因为此时RDD的数据量很大,内存无法完全放下,需要通过序列化来节省内存和磁盘的空间开销。该策略会优先尽量尝试将数据缓存到内存中,内存缓存不下时才会写入磁盘。(https://www.xing528.com)
通常不建议使用DISK_ONLY级别。因为完全基于磁盘文件进行数据的读写,会导致性能急剧降低,有时还不如重新计算一次该RDD。
通常不建议使用后缀为_2的备份级别。因为该级别必须将所有的数据都复制一份副本,并发送到其他结点上,而数据复制和网络传输会导致较大的性能开销,除非是作业的高可用性要求很高,否则不建议使用。
这里需要重点指出的是,推荐尝试使用OFF_HEAP方式,因为该方式将RDD数据持久化到了Alluxio中(曾用名Tachyon),而不是Executor的内存中。OFF_HEAP方式有以下几个优势:允许多个Executors共享同一个内存池;显著地减少了垃圾回收的开销;如果某个Executors崩溃,缓存的数据不会丢失。事实上,Alluxio带来的不止这些,它是一套基于内存的分布式文件存储系统,为跨程序、跨框架地共享内存数据提供了一套方案。更详细的情况请查阅Alluxio官网。
需要说明的是,持久化会最大化地保留整个RDD的所有分区数据,但是如果当前的计算需要内存空间而空闲内存不够,那么持久化在内存中的数据必须让出空间,此时如果RDD的持久化级别指定了可以把数据放在磁盘上,那么部分分区数据就可以从内存转入磁盘,否则数据就会丢失;Spark的持久化也具有容错性,当持久化的RDD的某一分区丢失后,后续计算该分区后也会自动重新计算并持久化该分区;同时,Spark也有自己的一套机制,自动监控每个结点上的缓存使用率,并通过LRU(Least Recently Used,近期最少使用)算法删除过时的缓存数据(当然也可以手动使用RDD.unpersist()方法来删除)。也就是说,持久化的数据在执行时不一定被有效地持久化了,要想知道要持久化的RDD有没有被正确地持久化,可以通过查看WebUI的Executor页面,详见9.2.8节。
下面是一个使用Persist的示例。

把数据通过Persist或Cache持久化到内存或磁盘中,虽然是快速的但却不是最可靠的,Checkpoint机制的产生就是为了更加可靠地持久化数据以复用RDD计算数据,通常针对整个RDD计算链条中特别需要数据持久化的环节,启用Checkpoint机制来确保高容错和高可用性。
可以通过调用SparkContext.setCheckpointDir方法来指定Checkpoint时持久化的RDD的数据的存放位置。在Checkpoint中可以指定把数据以多副本的方式存放在本地或HDFS中(在生产环境下通常是放在HDFS中,从而天然地借助HDFS高容错和高可靠的特征完成最大化的可靠的持久化);同时为了提高效率,可以指定多个目录。
需要说明的是,Checkpoint同Persist一样是惰性执行的,在对某个RDD标记了需要Checkpoint后,并不会立即执行,只有在后续有Action触发Job从而导致了该RDD的计算,且在这个Job执行完成后,才会从后往前回溯找到标记了Checkpoint的RDD,然后重新启动一个Job来执行具体的Checkpoint,所以一般都会对需要进行Checkpoint的RDD先进行Per-sist标记,从而把该RDD的计算结果持久化到内存或者磁盘上,以备checkpoint复用。
下面是一个使用Checkpoint的示例。

免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。