



语音交互包括语音合成和语音识别两部分。
1.语音合成
语音合成,又称文语转换(Text to Speech)技术,它涉及声学、语言学、数字信号处理、计算机科学等多个学科技术,是中文信息处理领域的一项前沿技术,主要解决如何将文字信息转化为声音信息,即让机器像人一样开口说话。这在情感机器人的设计中是必不可少的,只有让情感机器人开口说话,才能达到人与机器人的语音交互,才能在语言、语调中体现出机器人的情感状态,才能追求自然和谐的人机交互。下面介绍一下如何实现情感机器人的语音合成功能。
微软的Speech SDK 5.1采用了COM组件形式实现语音合成,比较简单易学。成功安装Microsoft Speech SDK 5.1后,就会在系统的控制面板->语音->文字语音转换下拉框中出现语音合成引擎,其中英文的语音合成有Mike,Mary和Sam三个角色,而对于中文的语音合成微软仅提供了simple Chinese一种声音。
语音合成的具体程序步骤如下:
1)调用API函数CoInitialize初始化COM组件;
2)使用SpFindBestToken函数,传入参数,设置中英文语言类型;
3)调用CoCreateInstance API函数创建COM语音合成接口实例IspVoice;
4)调用IspVoice接口方法SetVoice,加载前面所设置的声音类型;
5)初始化工作全部成功后,则可以在程序需要的地方调用IspVoice接口中的Speak方法,将合成的语句以宽字符的形式作为参数即可。
在合成过程中,可以使用SetVolume、SetRate等方法调节语音合成的音量、速度等。另外,还可以调用IspVoice接口的SetNotifyWindowMessage方法,设定在语音合成过程中某一事件发生时合成引擎向程序窗口发送的消息。
2.语音识别
语音识别是通过机器识别和理解把语音信号转变为相应文本文件或命令的技术。作为一个专门的研究领域,语音识别又是一门交叉学科,它与声学、语音学、语言学、人工智能、数字信号处理理论、信息理论、模式识别理论、最优化理论、计算机科学等众多学科紧密相连。在情感机器人的设计中语音识别是必不可少的一步,语音识别就如同让情感机器人拥有了“耳朵”,这种人性化的设计是完成语音交互的基础。
语音识别模块利用微软的Speech SDK 5.1提供的API设计开发。Speech SDK 5.1提供了两套API函数。分别是Application-Level Interfaces和Engine-Level Interfaces。前者为语音识别应用程序为开发提供了各种接口和方法。后者提供的是语音识别引擎接口和方法,主要是为了便于用户进行DDI或设备驱动程序开发。本应用实例使用Application-Level Interfaces提供的API进行程序设计与开发。(https://www.xing528.com)
相比较于语音合成而言,语音识别的实现过程稍显复杂。简单说来,在经历了一系列的初始化之后,设置识别引擎返回消息,当语音识别事件发生后,若识别成功,识别引擎自动向程序窗口发送识别成功的消息,若识别失败消息,开发者根据自身程序的情况进行相应得处理。具体过程如图6-3所示。
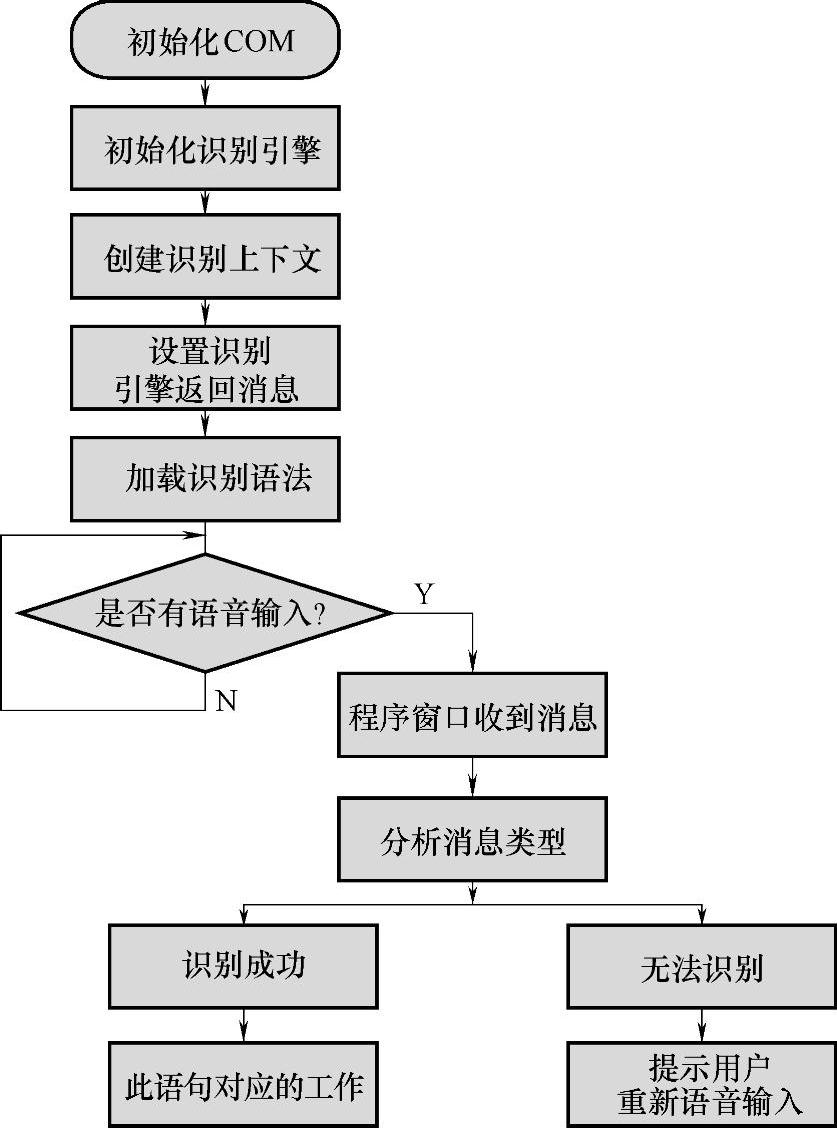
图6-3 语音识别流程图
1)初始化COM:微软Speech SDK以COM组件的形式提供给开发人员,因此,在调用SAPI之前需要对COM进行初始化。由于本系统是MFC基于对话框的程序,所以在程序实例初始化InitInstance函数中调用CoInitialize初始化COM。
2)初始化识别引擎:首先调用SpFindBestToken接口在系统注册表中查找合适的识别引擎。此接口的参数决定识别的语言类别特性——409表示英文,804表示中文和音频输入设备,然后调用CoCre-ateInstance初始化ISpRecognizer接口实例,最后使用SetInput和SetRecognizer接口函数将这些特性设置到语音识别引擎接口ISpRecognizer中。
3)创建识别上下文:识别上下文(Reco Context)就是语音识别的相关环境。一个语音识别引擎可以对应多个识别上下文,每个Reco Context规定了识别的语法规则、返回系统窗口的消息等。
4)设置识别引擎返回消息:消息就是当识别引擎检测到某种情况或完成某项任务后向主程序通知的事件,由此程序会对不同的事件作出不同的后继处理。SAPI所有消息都定义为枚举类型SPEVENTENUM,其中比较常用的为SPEI RECOGNITION(语音已被成功识别)、SPEI_FALSE_RECOGNITION(语音识别不成功)、SPEI_SOUND_START(声卡检测到有声音输入)、SPEI_SOUND_END(声卡检测到声音输入停止)等。应用程序先调用API函数SetNotifyWindowMessage将自身的主窗口句柄和消息类型通过参数传入。此时的消息是自定义的类型,程序需要调用接口ISpRecoContext的方法SetInterest指明程序关心的消息,这里可以是单个消息也可是一系列消息的组合。当语音识别引擎检测到相关的事件后自动向程序发送上述设定好的消息,程序根据参数判断具体消息的类型,再做相应的处理。
5)加载识别语法:所谓语法规则就是事先设定好的语音识别的内容。语法规则用XML语言形式存储到文件中,然后通过Speech SDK带有的编译器编译成.cfg文件,在程序运行时动态加入。先使用方法函数CreateGrammar创建语法接口,然后调用LoadCmdFromFile方法从外部文件将语法规则加载进来。
6)处理消息:本系统所关心的语音识别消息是SPEI_RECOGNITION与SPEI FALSE RECOGNITION,自定义的消息类型是WM_RECOEVENTCH。在自定义消息的响应函数中,首先调用SetRecoState,在处理语音识别结果时将识别引擎关闭,不接受新的语音输入;然后通过CSpEvent与当前的识别上下文关联;随后通过判断event ID来确定消息的类型,做相应的处理;最后再次调用SetRecoState,将识别引擎恢复正常,继续接受语音输入。
在整个语音识别程序中,识别语法和识别状态都可以动态的改变。只要将语法规则预先存储到不同的文件中,就可以因情况不同而更换。在改变识别引擎设置的时候,需要先将识别状态置为关闭状态。此外,可以看出windows的消息机制在整个识别处理中起到重要的作用,所有识别功能的实现,必须要在消息到来之后再去执行。所以自定义消息,手动添加消息响应函数,也是不可或缺的一个环节。
图6-4所示为简单的应用截图,其中采用了Microsoft Agent这个形象载体,语法规则采用的是动态数据库加载方式,这样能够适时地修改、添加和删除语音识别交互内容。通过实验,在安静的环境中经过训练后,可以满足用户的对话交互。
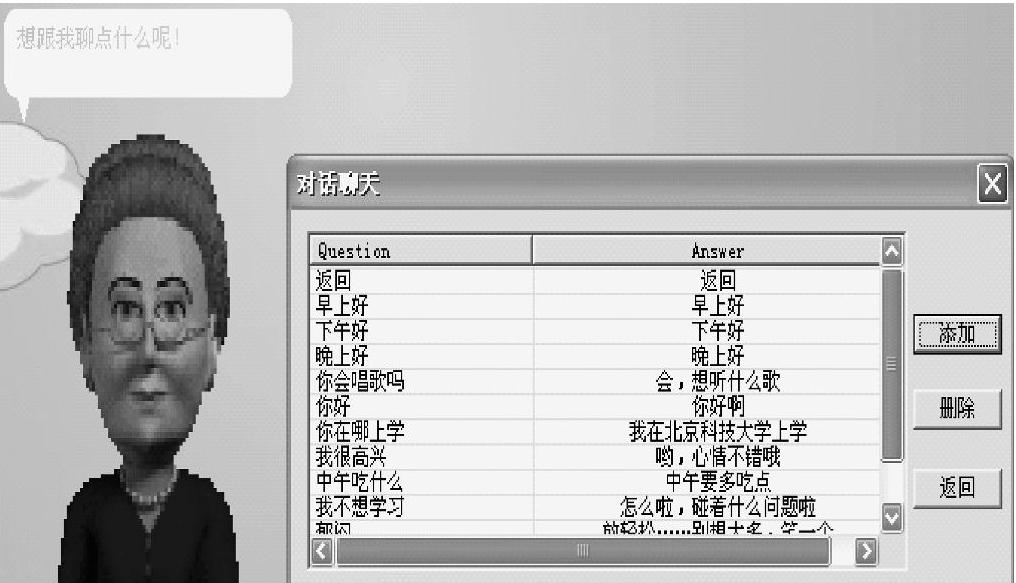
图6-4 语音交互实例
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。