



(1)逐层训练
图6.1第一层得到一个特征,如果重构误差小于给定的阈值,可以确定这个特征就是原输入信号的良好表达,或者牵强点说,它和原信号是一模一样的(表达不一样,反映的是一个东西)。那第二层和第一层的训练方式就没有差别了,将第一层输出的特征当成第二层的输入信号,同样最小化重构误差,就会得到第二层的参数,并且得到第二层输入的特征,也就是原输入信息的第二个表达(见图6.2)。其他层采用同样的方法(训练这一层,前面层的参数都是固定的,并且解码器已经没用了,都不需要了)。
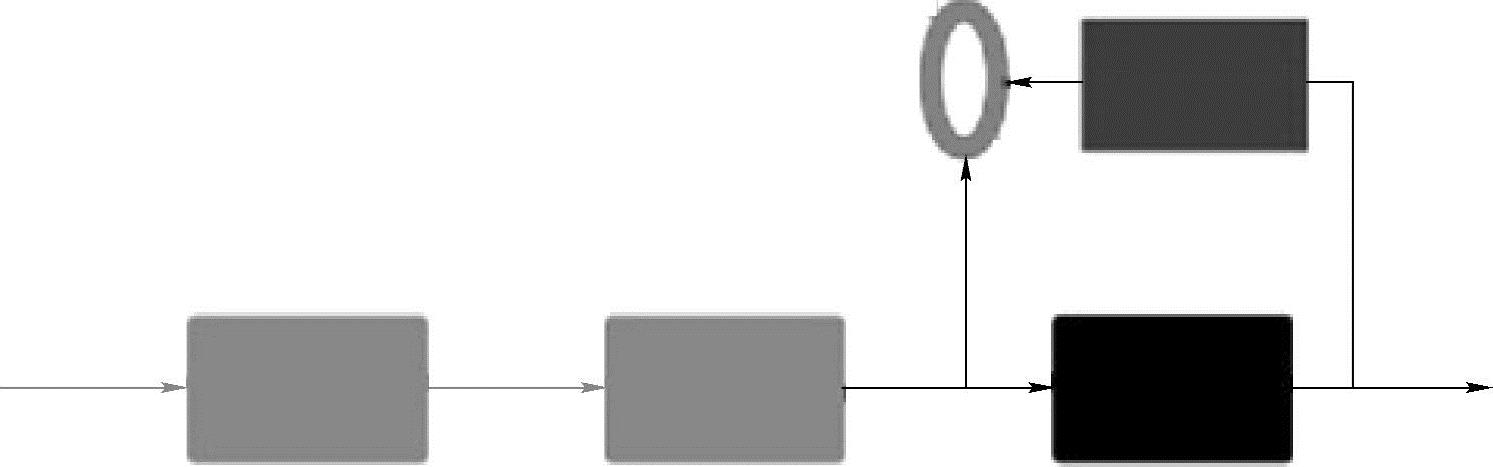
图6.2 逐层训练过程
(2)微调
经过逐层训练,需要自己调试这个网络。每一层都会得到原始输入的不同表达。当然,越抽象(层数越多)越好,就像人的视觉系统一样。
到这里,这个SA还不能用来分类数据,因为它还没有学习如何去联结一个输入和一个类。它只是学会了如何去重构或者复现它的输入而已。或者说,它只是学习获得了一个可以良好代表输入的特征,这个特征可以最大程度上代表原输入信号。那么,为了实现分类,可以在AE的最顶的编码层添加一个分类器(例如Logist回归、SVM等),然后通过标准的多层神经网络的监督训练方法(梯度下降法)去训练。(https://www.xing528.com)
也就是说,这时候,需要将最后层的特征输入到最后的分类器,通过有标签样本和监督学习进行微调,这也分两种,一种是只调整分类器(黑色部分,见图6.3);另一种通过有标签样本,微调整个系统(如果有足够多的数据,这个是最好的)。
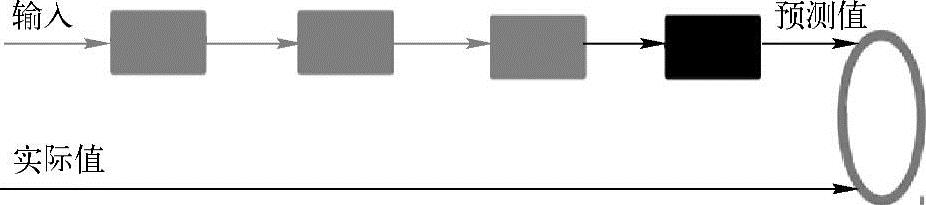
图6.3 微调过程
一旦有监督训练完成,这个网络就可以用来分类了。神经网络的最顶层可以作为一个线性分类器,然后用一个更好性能的分类器去取代它。
在研究中可以发现,如果在原有的特征中加入这些自动学习得到的特征可以大大提高精确度,甚至在分类问题中比目前最好的分类算法效果还要好!
在上述的堆栈自编码网络用于传统训练方法的流程的时候,一些研究人员对预训练这一步的必要性提出了疑问。但实验告诉我们预训练是最好的建议。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。