



在2016年1月4号发布的Spark 1.6中,提出了一个新的内存管理模型,即统一内存管理模型,对应在Spark 1.5及之前的版本则使用静态的内存管理模型。关于新的统一内存管理模型,可以参考https://issues.apache.org/jira/secure/attachment/12765646/unified-memory-management-spark-10000.pdf。在该文档中详细描述了各种可能的设计,以及各设计的优缺点。另外,也可以参考网上对Spark内存管理模型解析非常深入的博客http://0x0fff.com/ spark-memory-management/(Alexey Grishchenko),博客内容包含了静态内存模型管理与动态内存模型管理的详细说明。
为了解决现有基于JVM托管方式的内存模型所存在的缺陷,Project Tungsten设计了一套新的内存管理机制。在新的内存管理机制中,Spark的Operation可以直接使用分配的Bi-nary Data(二进制数据)而不是JVM Objects。避免了数据处理过程中不必要的序列化与反序列化的开销,同时基于Off-Heap方式管理内存,降低了GC所带来的开销。
Project Tungsten通过sun.misc.Unsafe来管理内存,关于sun.misc.Unsafe(从命名上可知该工具不能滥用)及其使用等内容,可以参考官网文档http://www.docjar.com/docs/api/ sun/misc/Unsafe.html。在此主要分析Project Tungsten中的内存管理模型的具体实现。
1.Project Tungsten内存模型
Project Tungsten内存管理模型主要的类图结构如图8-3所示。
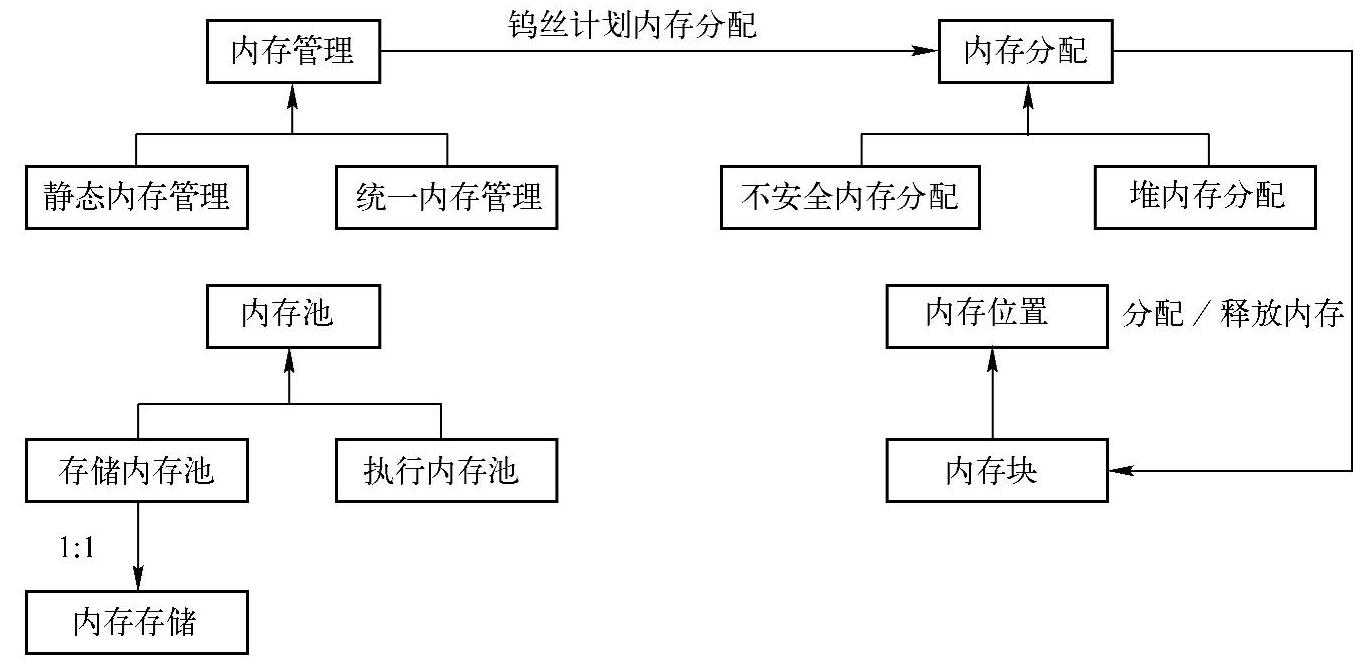
图8-3 Project Tungsten内存管理模型主要的类图结构
在图8-3中,基类MemoryManager封装了静态内存管理模型与统一内存管理模型,即分别对应两个具体实现子类StaticMemoryManger与UnitedMemoryManager。对应的内存分配由MemoryManager的成员tungstenMemoryMode决定,即由基类MemoryAllocator负责具体内存分配,对应Off-Heap与On-Heap两种内存模式,分别实现了两个具体子类UnsafeMemoryAl-locator与HeapMemoryAllocator。MemoryAllocator提供了Allocate和Free两个成员函数来提供内存的分配与释放,分配的内存以MemoryBlock来表示。
另外,根据内存使用目的的不同,将内存分为两大部分:Storage和Execution,对应的以MemoryPool的两个具体实现子类StorageMemoryPool与ExecutionMemoryPool对其进行管理。实际上除了这两部分,总的内存还包括为系统预留的OtherMemory。
关于内存分类及其对应管理的主要类之间的关系,可以通过图8-4来描述。
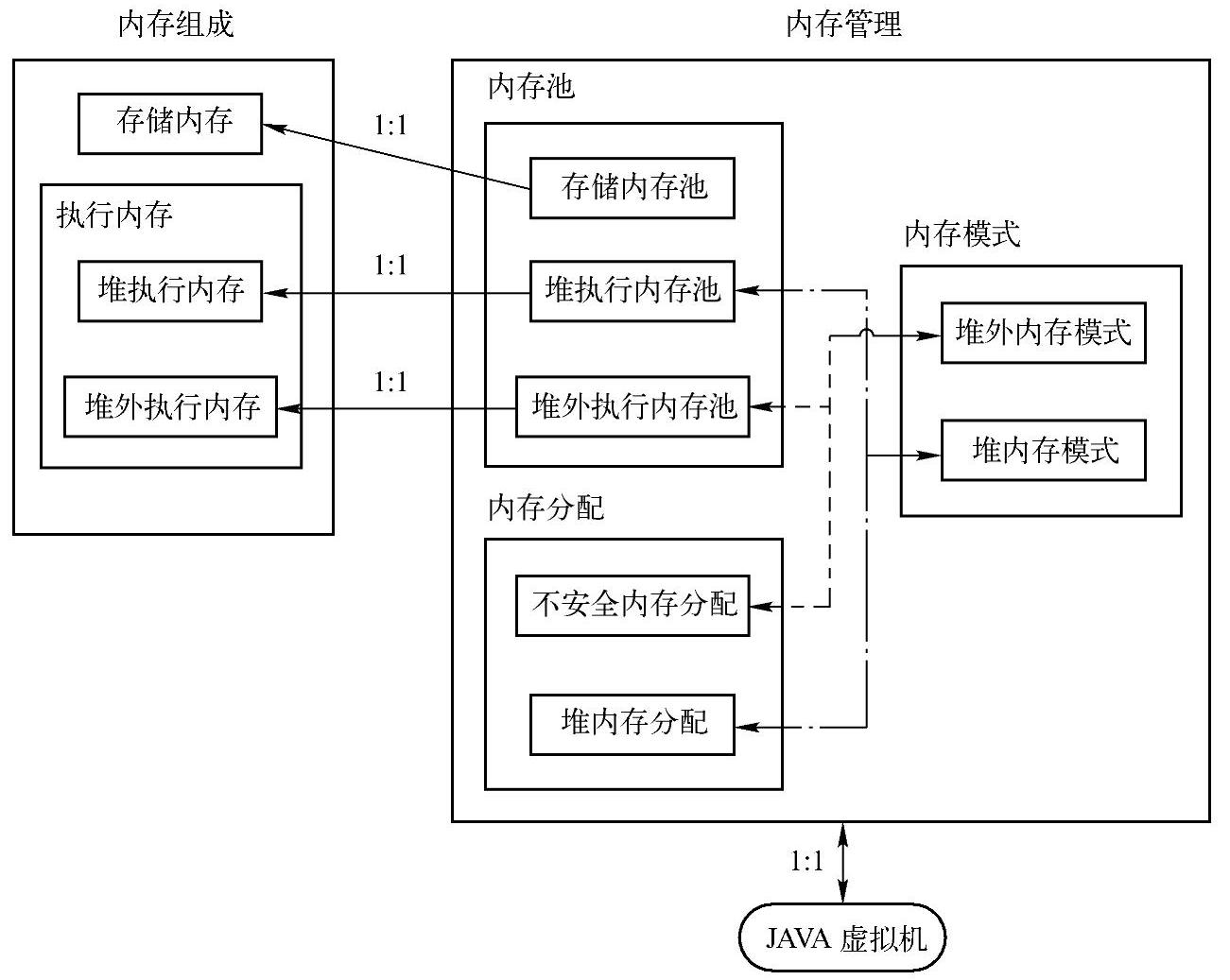
图8-4 内存分类及其对应管理的主要类之间的关系
在Worker上运行的每个Execution进程(抽象描述,实际对应各部署场景下的具体Ex-ecutorBackend实现子类),对应由一个MemoryManager负责管理其内存,即图8-4中Memo-ryManager与JVM的对应关系为1∶1。
Storage部分的内存由StorageMemoryPool负责管理,Execution部分的内存根据不同的内存模式(MemoryMode)分为on-heap与off-heap两种,分别由onHeapExecutionMemoryPool与offHeapExecutionMemoryPool进行管理。管理内存主要是通过内存使用量进行控制,不涉及内存的分配与释放。
2.MemoryManager的实现及其源代码解析
MemoryManager目前实现了两种具体的内存管理模型,从Spark 1.6版本开始,默认使用统一内存管理模型,对应的配置属性为"spark.memory.useLegacyMode",控制代码位于SparkEnv类中,代码如下。

以上是选择具体采用哪种内存管理模型的代码,下面开始分析与内存管理相关的源代码,首先查看MemoryManager的注释,代码如下。

在MemoryManager类中提供的内存分配与释放的几个主要接口如下。
·Storage部分内存的分配与释放接口:acquireStorageMemory、acquireUnrollMemory、re-leaseStorageMemory和releaseUnrollMemory。
·Execution部分内存的分配与释放接口:acquireExecutionMemory和releaseExecution-Memory。
内存具体分配与释放的实现由MemoryManager的具体子类提供。
两大实现子类(StaticMemoryManager和UnifiedMemoryManager)的主要差别在于Storage与Execution内存之间的边界是静态的还是动态可变的,下面分别简单描述两大子类的实现细节。
StaticMemoryManager类的注释如下所示。


静态内存管理模型中各部分内存的分配可以通过以下几个接口或成员变量查看。
1)maxUnrollMemory:unroll过程中可用的内存,占最大可用Storage内存的0.2(占比)。
2)getMaxStorageMemory:获取分配给Storage使用的最大内存大小。
3)getMaxExecutionMemory:获取分配给Execution使用的最大内存大小。
其中,getMaxStorageMemory对应用于Storage的最大内存,具体配置如下。

其中配置属性spark.storage.memoryFraction表示Storage内存占用全部内存(除预留给系统的内存外)的占比,spark.storage.safetyFraction对应为Storage内存的安全系数。
相应的,getMaxExecutionMemory方法指明了用于Execution内存的相关配置属性,与Storage内存一样包含占总内存的占比(0.2)及对应的安全系数。
另外,除了Storage内存与Execution内存占用的0.6+0.2之外的剩余内存,作为系统预留内存。
通过StaticMemoryManager类简单分析静态内存管理模型后,继续查看统一内存管理模型,首先查看其类注释。


UnifiedMemoryManager与StaticMemoryManager一样实现了MemoryManager的几个内存分配和释放的接口,对应分配与释放接口的实现,在StaticMemoryManager中相对比较简单,而在UnifiedMemoryManager中,由于考虑到动态借用的情况,实现相对比较复杂,具体细节可以参考官方提供的统一内存管理设计文档及相关源代码,比如针对各个Task如何保证其最小分配的内存(最少为1/2N,其中N表示当前活动状态的Task个数,最大的Task个数可以从Executor分配的内核个数/每个Task占用的内核个数得到)等。
下面简单分析一下统一内存管理模型中,Storage内存与Execution内存等相关的配置。
查看方法,具体代码如下。

另外,虽然Execution与Storage之间共享内存,但仍然存在一个初始边界值,参考伴生对象UnifiedMemoryManager的apply工厂方法,具体代码如下。

另外需要注意的是,前面Execution内存指的是ON_HEAP部分的内存,在ProjectTung-sten中引入了OFF_HEAP(堆外)内存,这部分内存大小的设置在基类MemoryManager中,对应代码如下。

当需要使用OFF HEAP内存时,需要注意的是,除了需要修改OFF HEAP内存池(off-HeapExecutionMemoryPool)的内存初始值(默认为0)外,还需要打开对应的控制开关,具体代码参考内存分配MemoryManager中内存模式的设置(该内存模式可以控制用于内存分配MemoryAllocator的具体子类),对应代码如下。

从图8-4中可以看出,Execution内存根据不同的内存模式(ON HEAP或OFF HEAP)可以有两种内存池管理方式,可以查看一下Execution内存分配的方法,关键代码如下。

MemoryMode是二选一,因此在启动OFF_HEAP内存模式时,可以将Storage的内存占比(对应配置属性"spark.memory.storageFraction")设置得高一点,虽然在具体分配过程中Storage也可以向ON_HEAP这部分Execution借用内存。
关于内存池部分,下面给出主要类的类图,具体实现可以结合类图阅读源代码来加深理解,主要类图如图8-5所示。
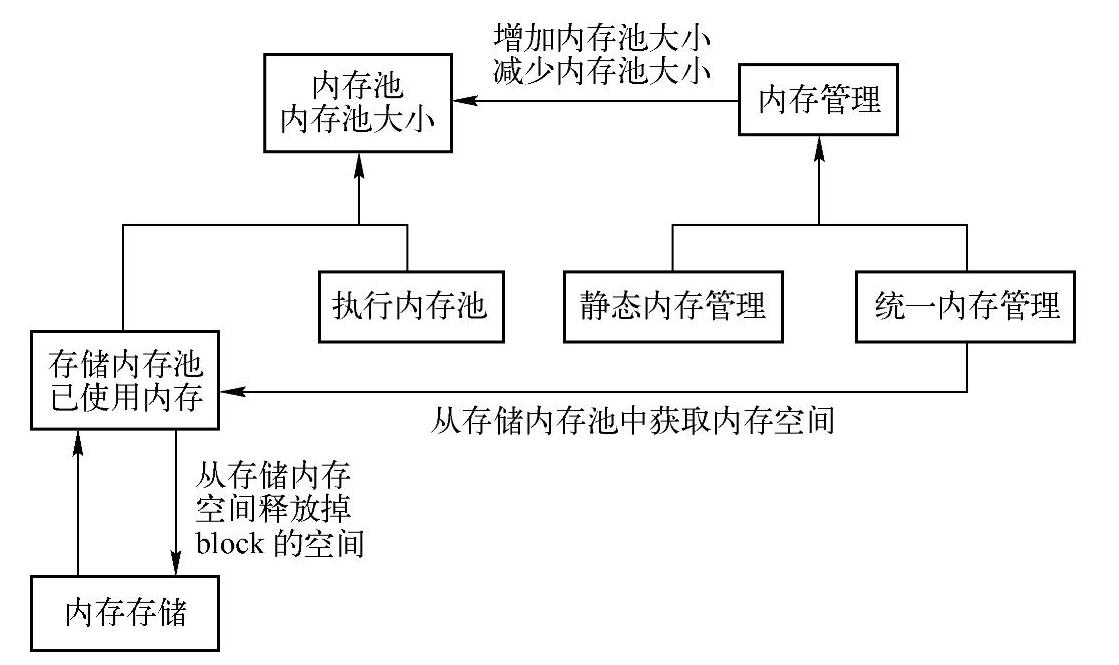
图8-5 内存池相关类图
主要通过内部池大小和使用的内存大小等进行控制,对应统一内存管理模型,需要考虑借用等具体实现(关键代码可以查看UnitedMemoryManager对StorageMemoryPool类的shrink-PoolToFreeSpace方法的调用)。
以上是对Tungsten的两种内存管理模型的简单解析。下面开始对内存管理模型的内部组织结构进行解析。
3.Project Tungsten内存管理模型中对内存描述的封装
关于Project Tungsten的相关内容,可以参考https://github.com/hustnn/TungstenSecret。其中对Page Table给出了描述非常详细的说明图。
下面从最基本的源代码开始逐步分析内存管理模型中内存描述的封装,主要包含内存地址的封装和内存块的封装,分别对应MemoryLocation和MemoryBlock。
在Project Tungsten中,为了统一管理ON_HEAP和OFF_HEAP两种内存模式,引入了统一的地址表示形式,即通过MemoryLocation类来表示ON_HEAP或OFF_HEAP两种内存模式下的地址。
首先查看该类的注释信息,具体如下所示。

当使用OFF_HEAP内存模式时,内存地址可以通过64位的绝对地址来描述,相应的,当使用ON_HEAP内存模式时,由于GC过程中会对堆(heap)内存进行重组,因此地址的定位需要通过对象在堆内存的引用及在该对象内的偏移量来表示,此时便需要对象引用和一个偏移量来表示内存地址。(https://www.xing528.com)
因此,在MemoryLocation中定义了两个成员变量,具体代码如下。

对应两种不同的内存模式,两个成员变量的描述如下。
1)OFF_HEAP内存模式:obj为null,地址由64位的offset唯一标识。
2)ON_HEAP内存模式:obj为堆中该对象的引用,offset对应数据在该对象中的偏移量。
由以上分析可知,通过MemoryLocation类可以统一定位一个OFF_HEAP和ON_HEAP两种内存模式下的内存地址。
对应MemoryLocation类的继承子类为MemoryBlock,顾名思义,该子类表示一个内存块,无论是OFF_HEAP还是ON_HEAP内存模式,在Project Tungsten内存管理时,都使用一块连续的内存空间来存储数据,因此即使是在ON_HEAP模式下,也可以降低GC的开销。下面来看一下MemoryBlock类的注释信息,具体如下。

补充:在代码复用方式上存在两种形式:继承与组合。目前,在MemoryBlock中使用继承的方式包含内存块的地址信息。在实现上,也可以采用组合这种复用方式,指定内存块的地址,以及内存块本身的内存大小。
下面简单介绍一下MemoryBlock类中除了继承自MemoryLocation类之外的部分成员。
1)private final long length:表示内存块的长度。
2)public int pageNumber:表示内存块对应的page号。
3)public static MemoryBlock fromLongArray(final long[]array):这是提供的一个将long型数组转换为MemoryBlock内存块的接口。
在提供了内存块之后,下一步就是如何去组织这些内存块,在Project Tungsten中采用了类似操作系统的内存管理模式,即使用Page Table方式来管理内存。因此,下面将对Page Table管理方式进行解析。
4.Project Tungsten内存管理模型中的内存组织和管理模式
Spark是一个技术框架,数据以分区粒度进行处理,即每个分区对应一个处理的任务(Task),因此内存的组织与管理等可以通过与Task一一对应的TaskMemoryManager来理解。
下面首先给出TaskMemoryManager与MemoryManager间的关系图,如图8-6所示。
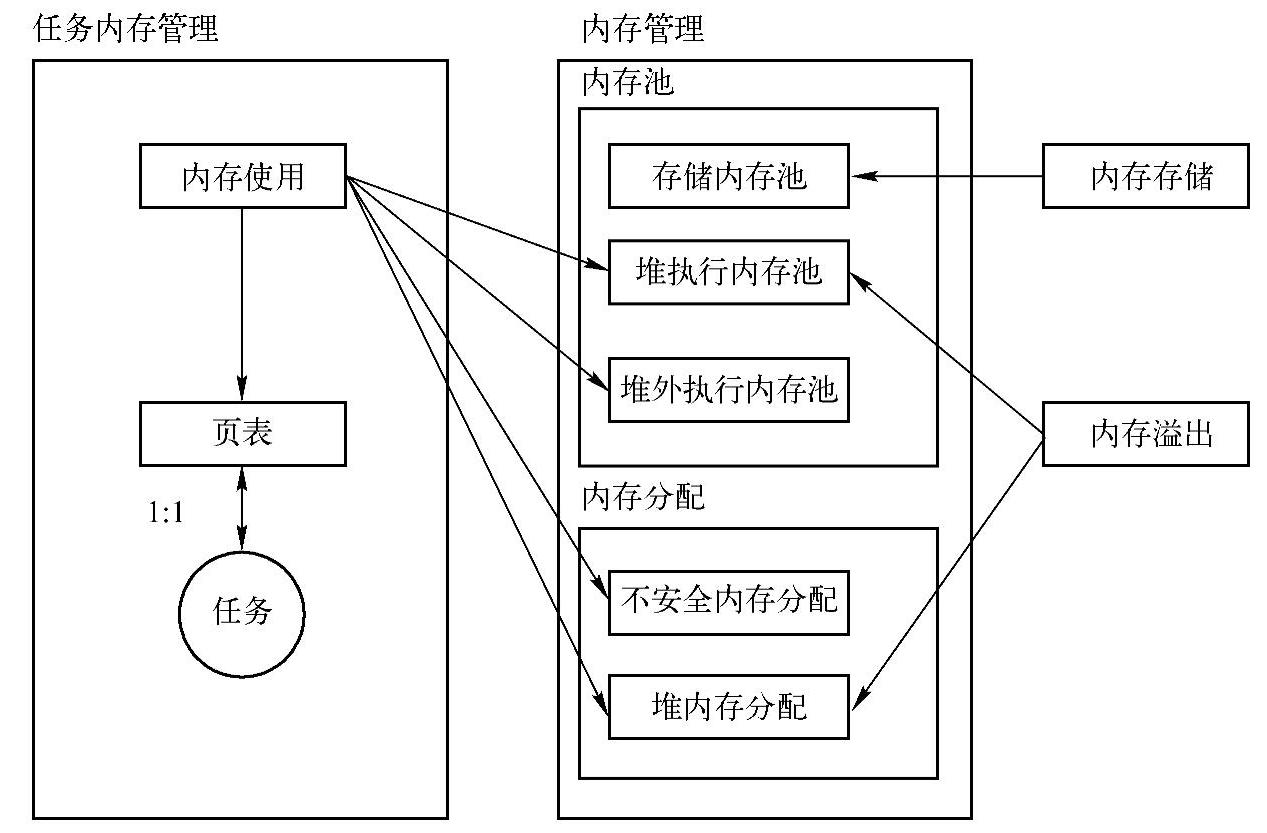
图8-6 TaskMemoryManager与MemoryManager的关系图
在图8-6中,各个MemoryConsumer是具体处理时需要使用(消耗)内存块的实体,MemoryConsumer通过TaskMemoryManager提供的接口向MemoryManager申请或释放内存资源,即申请或释放内存块。TaskMemoryManager类中会管理全部MemoryConsumer,并对这些内存消耗实体所申请的内存块进行组织与管理,具体是通过PageTable的方式来实现。
首先查看类的注释信息,原注释信息比较多,在此仅给出简单的中文描述,具体代码如下。

下面从3个方面对TaskMemoryManager进行分析:包含内存地址的编码与解码、PageTa-ble的组织与管理,以及内存的分配与释放。
(1)内存地址的编码与解码
从TaskMemoryManager类的注释部分可以知道,OFF_HEAP与ON_HEAP两种内存模式最终对外都是采用一致的编码格式,即对应13位的pageNumber(页码)和51位的offset(偏移量),可以通过图8-7来描述对应的编码方式。
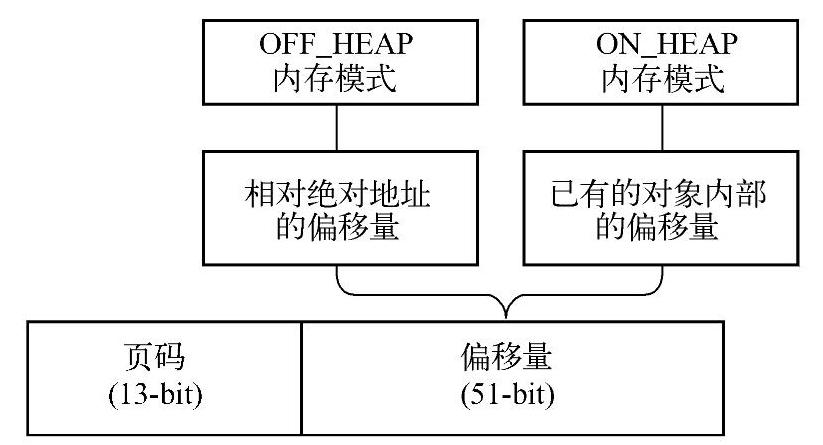
图8-7 Page的编码方式
下面分别对TaskMemoryManager类中与编码和解码相关的几个接口进行解析,编码接口主要有两个,encodePageNumberAndOffset和decodePageNumber其源代码与解析如下所示。

通过pageNumber可以找到最终的Page,Page内部会根据OFF_HEAP或ON_HEAP两种模式分别存储Page对应内存块的起始地址(或对象内偏移地址),因此编码后的地址可以通过查找到Page,最终解码出原始地址。解码的源代码及其解析如下所示。

在TaskMemoryManager类中还另外提供了针对ON_HEAP内存模式下获取base object的接口,对应的源代码及其解析如下所示。

(2)PageTable的组织与管理
在分析这部分内容之前,先看一下Page Table方式进行组织与管理描述图,如图8-8所示。
在图8-8中,右侧是分配的内存块,即当前需要管理的Page。在TaskMemoryManager中,通过Page Table来存放内存块,同时,通过在变量allocatedPages中指定值为Page Num-ber(页码)的下标(索引)对应的值是否为1,来表示当前Page Number对应的Page Table
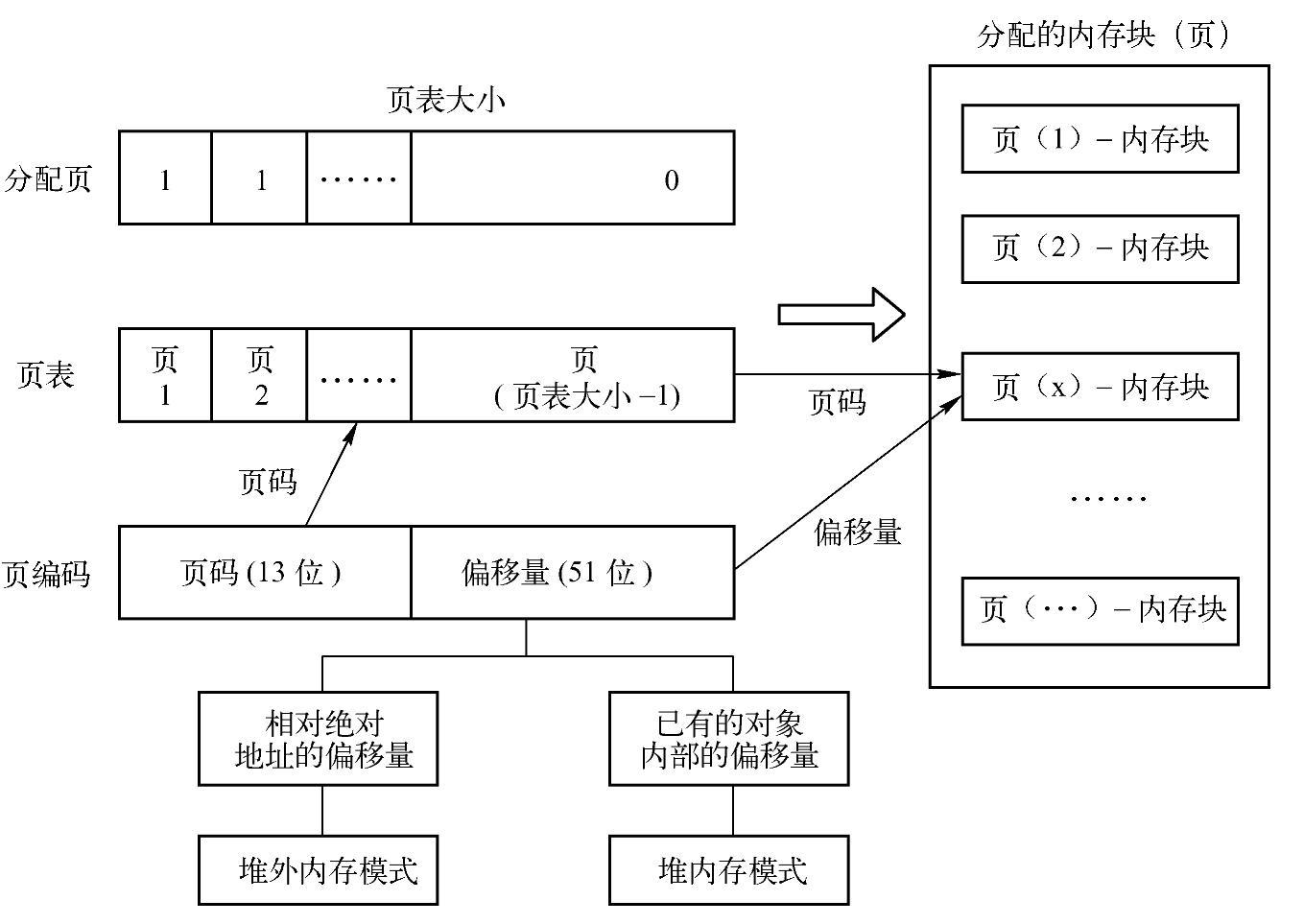
图8-8 PageTable组织与管理描述图
中的Page是否已经存放了对应的内存块,即每当分配到一个内存块时,从allocatedPages获取一个值为0的位置(页码),并将该位置作为内存块放入到Page Table中的位置。
简单来说,就是通过allocatedPages中各个位置上的值为1或0来判断在Page Table中相同位置是否已经放置了内存块(Page)。
而对应在Page Table中已经存放的内存块,实际上就是对应了右侧已经分配的内存块。
当针对一个Page Encode(页地址编码)时,首先从中获取Page Number,根据该值从Page Table中获取确定的内存块(MemoryBlock或Page),找到确定内存块之后,再通过页地址编码中的offset(具体两种内存模式下的概念如图8-8所示)确定内存块中的相关偏移量。如果是OFF_HEAP,则该offset是相对于内存块(从前面分析可知,内存块本身的信息也与内存模式相关)中的绝对地址的相对地址;如果是ON_HEAP,则该offset是相对于内存块的base object中的偏移量。
相关的源代码主要涉及TaskMemoryManager类的两个成员变量,如下所示。

PageTable的组织与管理中关于页码的偏移量已经在上一部分给出了详细描述,而对应的具体管理操作则与实际的内存分配与解析部分相关。通过图8-8对大致的管理有一定的概念后,再继续通过内存分配与解析部分来详细解析具体的管理细节。
(3)内存分配与解析
关于这部分内容,主要参考allocatePage与freePage两个方法,对应allocatePage内部如何申请内存,以及申请内存时采用的spill策略等细节,大家可以继续深入,比如通过查看acquireExecutionMemory的具体源代码来加深理解。
allocatePage方法的源代码及其解析如下所示。


其中,MAXIMUM_PAGE_SIZE_BYTES是页内数据量大小的限制,从之前MemoryBlock提供的从long型数组转换得到MemoryBlock接口,可以知道当前连续的内存块是通过long型数组来获取的,因此对应的内存块的大小也会受到数组的最大长度的限制。
至于对应在具体的处理过程中,对页内的数据量大小是否还有其他限制,可以参考具体的处理细节,下一节会给出一个具体处理过程的源代码解析,其中会包含这部分内容。
由于内存分配的细节比较多,这里给出主要的过程描述。
1)首先通过acquireExecutionMemory方法向ExecutionMemoryPool申请内存(根据统一或静态两种具体实现给出):这一部分主要是判断当前可用的内存是否满足申请需求,并根据申请结果修改当前内存池可用的内存信息(实际是当前使用内存量信息)。
2)从当前Page Table中找出一个可用位置,用于存放所申请的内存块(MemoryBlock或Page)。
3)准备好前两步后,开始通过MemoryAllocator真正分区内存块。
4)将分配的内存块放入Page Table。
在整个过程中,allocatedPages与pageTable这两个成员变量的使用是体现Page Table组织与管理的关键所在。
下面解析freePage的源代码,如下所示。


释放Page的逻辑实际上可以参考申请Page,大部分都是步骤相反而已。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。