



下面以通讯录地址本为例说明Parquet列式存储格式。

整个通讯录地址本是一个嵌套结构,根结点是通讯录地址本(message),地址本里面包含多个字段[如业主owner、业主电话owner Phone Number、联系人(名字Name、电话Pho-neNumber)]。每个字段包含3个属性:重复属性、字段类型、标识符。
其中重复属性可以是以下3种类型中的任意一种:
1)required(必需的,表示出现1次)。
2)optional(可选的,表示出现0次或者1次)。
3)repeated(重复的,表示出现0次或者多次)。
其中字段类型可以是以下两种:
1)group(组类型表示为一个组结构体,如联系人结构体中包括联系人的电话和名字)。
2)primitive(基本类型可以表示为int、float、boolean、string等)。
其中标识符可以解析为词法标识符单词:如业主名字、业主电话等。
在通讯录地址本嵌套结构中,每条记录表示一个人的通讯录,通讯录中必须登记业主;业主可以记录0个或多个电话号码;每个业主可以拥有0个或多个联系人,每个联系人必须记录名字,而联系人的电话号码可选。
通讯录地址本可以用图4-2来表示。
对通讯录地址本的树状结构图解释如下:
1)图4-2中,叶子结点分别为:业主owner、业主电话ownerPhoneNumbers、联系人名字name、联系人电话phoneNumber。
2)在逻辑上而言,模式(schema)实质上是一个表,如图4-3所示。
3)对于一个Parquet文件而言,数据会被分成Row Group(里面包含很多Column,每个Column就是这一列的数据),这样就构成了矩阵。
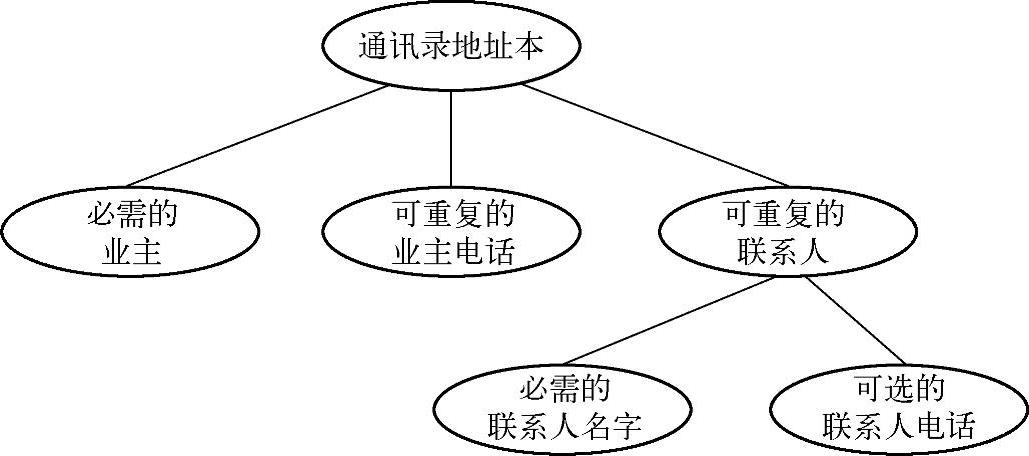
图4-2 通讯录地址本的树状结构图

图4-3 schema示意图(https://www.xing528.com)
4)Column具有几个非常重要的特性,例如:Repetition Level(重复级别)、Definition Lev-el(定义级别)。Column在Parquet中是以Page(页)的方式存在的,Page中有Repetition Lev-el、Definition Level等内容。从根结点往叶子结点遍历的时候,会记录深度,这个就是Defini-tion Level。Definition Level方便我们精准地找到数据。owner是required,所以将其Definition Level可以定义为0。ownerPhoneNumber结点没有叶子结点,定义为1。Name结点是required,定义为1。PhoneNumber是optional,有可能出现,也有可能不出现,定义为2。Repetition Level为重复级别。Owner为0,ownerPhoneNumber为1,name和phoneNumber都是1。
5)Row Group在Parquet中是数据读写的缓存单元,所以对Row Group的设置会极大地影响Parquet的使用速度和效率。如果是分析日志的话,建议把Row Group的缓存大小配置成256MB,而很多人的配置都是大于1 GB,如果想最大化地提高运行效率,强烈建议HDFS的Block大小和Row Group一致。
6)在实际存储的时候把一个树状结构,通过巧妙的编码算法,转换成二维表结构。Parquet在存储时,会将AddressBook正向存储为4列,读取的时候会逆向还原出Address-Book对象,如表4-3所示。
表4-3 二维表

7)Google的Dremel系统解决了列式存储的问题,其核心思想是使用“record shredding and assembly algorithm”记录切碎和组装算法来表示复杂的嵌套数据类型,同时辅以按列的高效压缩和编码技术,实现降低存储空间。该算法就是把一行数据打碎,打碎之后按照自己的编码规则,再把数据组装起来。Parquet就是基于Dremel系统的数据模型和算法来实现把树状结构转换成图4-3所示的二维表结构。
8)Definition Level是为了快速精准地找到数据,通过Definition Level可以精准地判断数据一定在哪个位置上。嵌套数据类型的特点是有些field可以是空的,也就是没有定义。如果一个field是定义的,那么它的所有父结点都是被定义的。从根结点开始遍历,当某一个field的路径上的结点开始是空的时候,记录当前的深度作为这个field的Definition Level。如果一个field的Definition Level等于这个field的最大Definition Level,就说明这个field是有数据的。对于required类型的field必须是有定义的,所以这个Definition Level是不需要的。在关系型数据中,optional类型的field被编码成0(表示空)和1(表示非空,或者反之)。所以对于上个例子,Owner是叶子结点,且是一定存储的,因此就将Definition Level定义为0。因为Contacts为repeated,所以name的Definition Level不可以为0,只能为1。phoneNumber是optional,因此它的Definition Level是2。
9)什么是Repetition Level?Repetition Level用于记录该field的值是在哪一个深度上重复的。只有repeated类型的field需要Repetition Level,optional和required类型的不需要。Rep-etition Level=0表示开始一个新的record。在关系型数据中,repetition level总是0。所以对于上个例子,Owner为0,ownerPhoneNumber为1,name和phoneNumber都是1。下面是更细致的表达:

通过上述Definition Level、Repetition Level的取值就可以精准地判断哪个数据一定在什么地方,以及映射成物理结构也比较容易,具体写到磁盘的时候就是Definition Level、Repetion level和value的构成。
例如:如果一条记录是如下的数据记录,包括两条AddressBook,第一条AddressBook中有两个联系人,其中第一个联系人的姓名是Spark,第二个联系人的电话是18610086859;第二条AddressBook为空。


分析上述记录,如图4-4中,R表示重复级别,D表示定义级别。对于name:"Spark"字段:其R重复级别是0,表示是一个新的record记录,从根开始按照schema建立结构,D定义级别是1,name是required的,因此不需要definition level,所以沿用contacts的级别1;对于phoneNumber:“18610086859”字段:其R重复级别是1,表示在第一级插入新值,即从第一条AddressBook的第一个contacts联系人之后插入一个新联系人记录,phoneNumber是optional的,需要definition level,这里D定义级别是2;对于第二条AddressBook,其R重复级别是0,表示是一个新的record记录,D定义级别也是0,null表示是空数据。
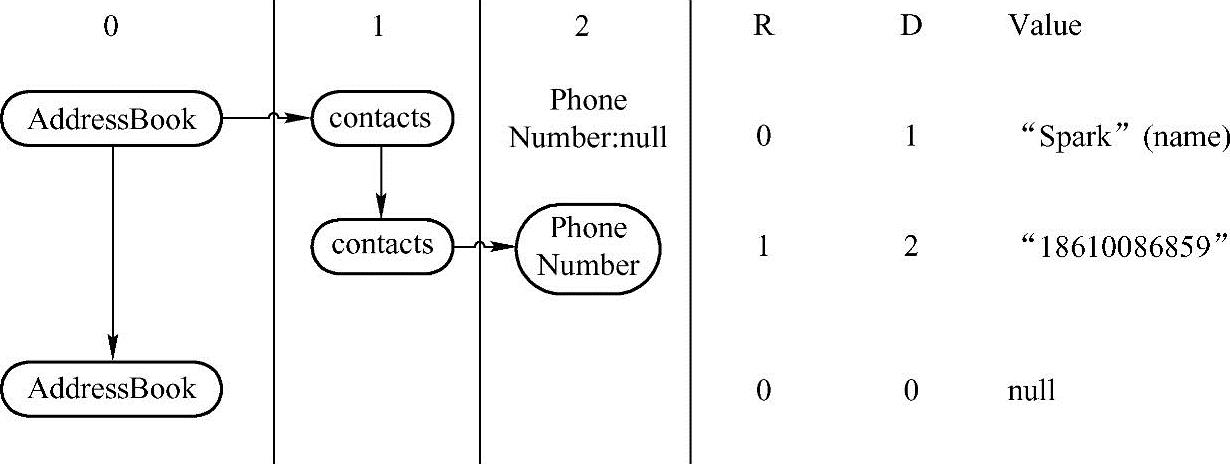
图4-4 AddressBook记录的序列化过程示意图
整理上述两条AddressBook的通讯信息如下图4-5所示。

图4-5 Definition Level、Repetion level和Value的构成表
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。