



这里重点分析两类主要路由算法及相关的具体协议,一类是距离向量算法,具体实例有路由信息协议(RIP);另一类是链路状态算法,具体实例有开放最短路径优先协议(OSPF)。
1.距离向量算法及RIP
(1)距离向量算法实现过程
距离向量算法的思想是:每个路由器都构造一个包含到所有其他路由器的距离信息。并将该信息发送给与其直接相连的所有邻居。相邻的路由器收到路由信息后,将所接收到的与自己原来已有路由信息进程组合,最后得到完整的连接到所有可到目的网络的路由。图7-4所示为距离向量算法如何工作。
路由选择协议最基本的问题就是找出任意两结点之间的最低开销路径。该例中,首先假设每两个结点之间链路开销都是1,也就是说一条开销最小的路径就是包含跳点数最少的路径。
路由器在启动其路由表时,一开始只有与它们直接相连路由器的信息。最初,每结点都把与其直接相连的结点的开销赋值为l,与其不直接相连的赋值为无穷大。这样就可得到一个关于所有结点初始距离的统计表(表7-1)。
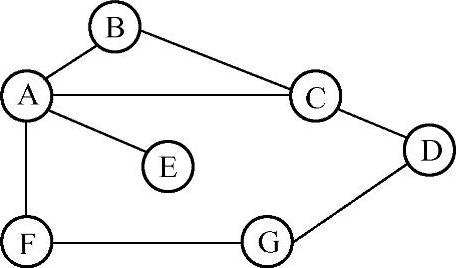
图7-4 距离向量路由选择结构图
表7-1 存储在各结点的初始距离表
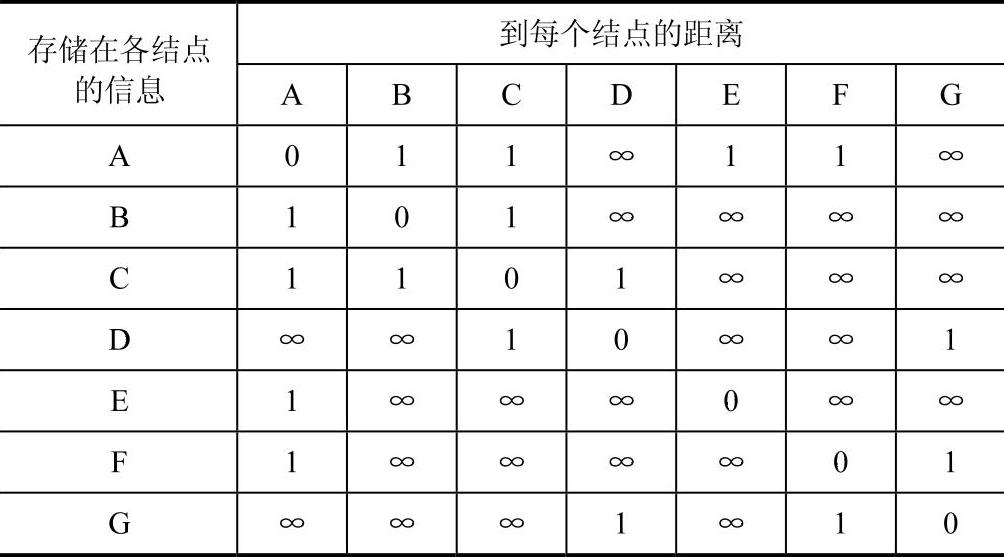
表中“l”代表直接到达相应结点,且开销为1,“∞”则代表不可到达相应结点。例如A可直接到达B结点,但不可到达D结点。表7-1是从整体角度分析各结点的情况,实际上各结点的路由表只包含本结点与其他结点信息。以A的初始路由表来说明(表7-2)。
初始化各路由器路由表后,距离向量路由选择协议在每台路由器上运行,路由表使用从相邻路由器得到的所有路由信息完成更新。例如,结点F告诉结点A,它可到结点G,开销为l;A也知道自身到F开销为1,这样A就知道它可经过F到达G,并计算出开销为2,与初始化时A的路由表上到G的信息一比较发现,经过F到G的开销小于原先到G的开销,因此A更新路由表的关于到G路由这一项。B结点与A也相邻,因此它也会与A交换路由消息。B告诉A,它可到C结点,开销为1,又A可到B且开销为l,因此A将得知它可经过B到达C,开销为2。A将这条路由与初始路由表比较后发现,初始时,A可到达C,且开销为l。以此得出结论:A经过B到达C路径开销大于A直接到达C的路径,因此将不更新A路由表中关于到达C的路由,保留原先信息。同理,A与所有相邻结点交流后,得到最终的路由表(表7-3)。
表7-2 结点A的初始路由表
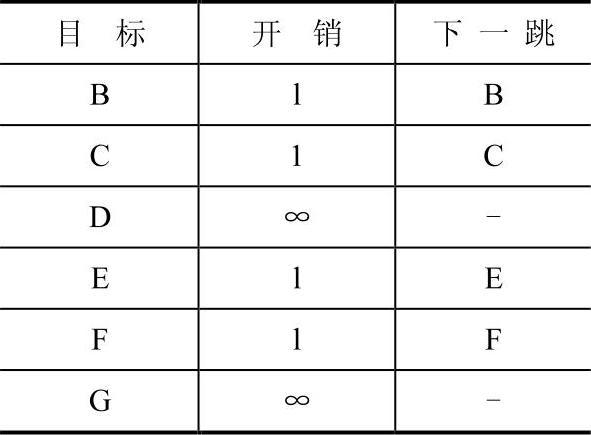
表7-3 结点A的最终路由表

其他结点同理,更新各自的路由表。每个结点通过与相邻结点交换路由信息,最终得到完整的路由表。这个过程就是聚合(或称收敛,convergence)。
上面涉及的理想模型是以送到结点为目标,互联网中路由器的目标是计算如何向不同网络转发数据,因此应计算到达网络的开销,而不是指到达路由器的开销。图7-5说明了该情形。

图7-5 使用距离向量路由选择协议的互联网络
各路由器在启动时初始路由表见表7-4。
表7-4 各路由器启动时初始路由表
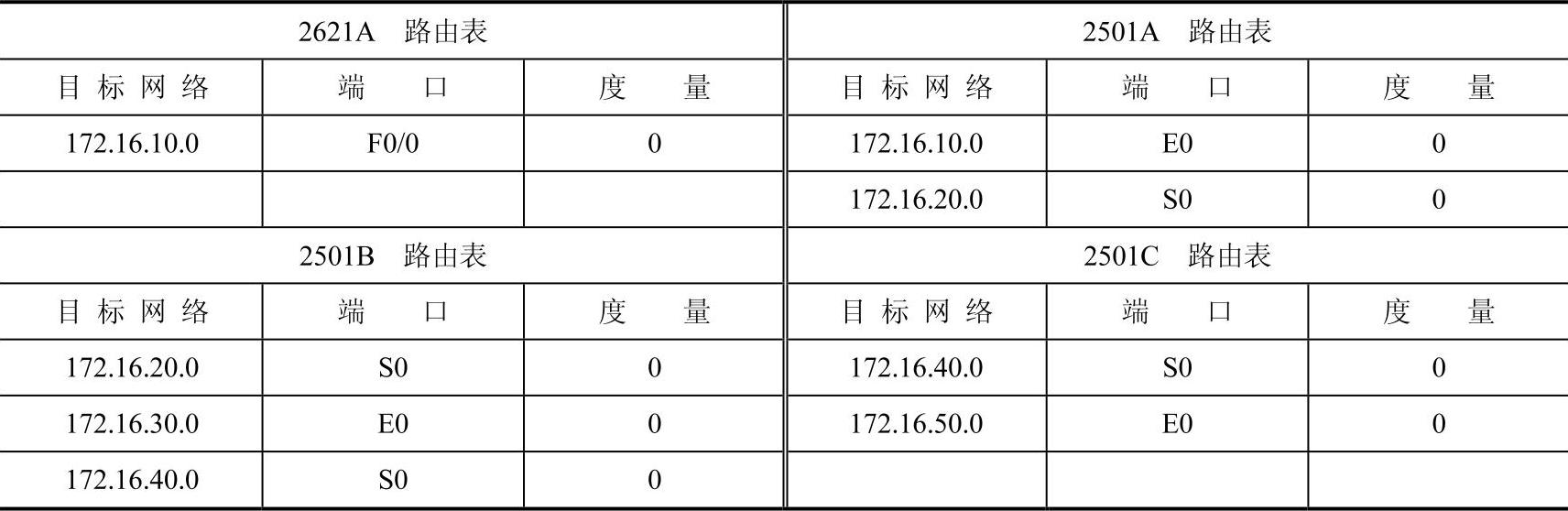
经过路由器交换信息后,每个路由将得到完整的更新后路由表,见表7-5。
表7-5 各路由器更新后路由表
(2)距离向量算法中存在的问题
距离向量算法通过不断发送更新消息给相邻结点来跟踪网络的任何变化。在两种情况下,结点会发送更新消息。一是定期更新,此时,即使网络无任何变化,结点也自动定时发送更新消息,虽然此更新会占用一定CPU进程与网络带宽,但能告知相邻结点,发送消息的结点处于正常工作状态。二是触发更新,当一个结点从它相邻结点收到更新消息,且该消息中包含路由表中某条路由变化的信息,接到消息的结点才向其相邻结点发送更新消息。
正常情况下,系统中各路由器经过相互通信,迅速统一路由,达到稳定状态。但当网络有故障发生时,各路由器将如何处理?首先要有发现故障的方法。一种方法是结点连续发送控制分组给其他结点,如接收并应答,则说明无故障,反之,则存在故障。另一种方法是采用定期更新,如最近几次更新都接收不到预期更新消息,说明链路有故障,反之,链路正常。
当确定发生故障后,相应结点即修改本地路由表,并将新路由信息发送给相邻结点,而这些相邻结点又会给它们的相邻结点发送更新消息。但出现这种故障后更新路由表的过程中会产生问题。由于运行距离向量算法的路由器不能同时完成路由表的更新,更新消息无法立即到达所有结点,因此网络中的一个结点可能在接收到表明一个链路失效的更新消息前向另一已接收到该更新消息的结点发送另一条消息,并且该消息包含的内容是将之前已失效的路由表示为有效,那么后一结点便包含了不正确的路由信息,而且还可能将该错误信息继续传播下去,于是造成路由环路的产生。这里以图7-4拓扑结构说明路由环路的产生。假设结点A到结点E的链路出现故障。当A发现故障后,就将其路由表中到E的距离设置为无穷大,但这个更新周期内B和C无法知道A与E之间出现状况,因此它们仍然认为E是可达的,且距离为2。然后在其后面更新周期中,有可能发生这种情况:即结点B知道C可经过2跳到达E,于是就认为它可经过3跳到达E,并把该消息告诉A。A收到消息后会认为它可经过4跳到达E,然后把该消息告诉C,那么C又认为它可经过5跳到达E,这样在A、B、C之间形成路由环路,而到达E的距离也会不断增加。只有当距离到达是无穷大时,循环才会停止。因此,该情况又称计数到无穷问题。
针对该问题,有几种解决方案。第一种,设定最大跳数值。可使用一个较小的数作为无穷大近似值,当跳数超过该值,就认为不可达,但该方法限定网络规模。第二种,水平分割。通过强制信息的传送规则来减少不正确路由信息和路由管理开销的产生。具体做法是,当一个结点把路由选择的更新消息发送给相邻结点时,它不把从相邻结点获得的路由信息再回送给那些相邻结点。该方案可避免临近结点之间的路由循环。图7-4中,结点A发送消息给结点B,告诉B它可到E。那么B在回发给A的消息中就不应包含此路由,因为A距离E更近:按照水平分割规则,B应从它发往A的所有更新消息中删除这条路由。水平分割规则有助于避免两结点之间的路由循环。假定A通向E的链路中断,在不使用水平分割情况下,B会继续通知A它可通过A到达E,如A没有有效判别功能,它就会用B发来的路由代替失效的路由,从而导致路由环路产生。第三种,路由“中毒”(route poisoning)。这是更好的避免由不一致更新可能造成的问题并防止路由环路产生的方法。该方法中,结点可把来自相邻结点的路由回送给相邻结点,但回送的信息是关于路由“中毒”的信息。为更形象地说明路由中毒,仍采用图7-4的拓扑结构。在图中,假设A到E的链路中断,那么A获知E不可到达后,在其路由表中将结点E对应路由改为无穷大来引发一个路由“中毒”。然后A向B和C发送这条中毒路由的更新消息,以阻止其他错误通向E的路由更新消息发往B和C,B、C又继续向其他结点发送路由“中毒”,包括向A回送,保证所有路由器都可收到路由“中毒”消息。
解决距离向量算法的路由环路问题,还必须涉及“保持关闭”的内容。保持关闭用于阻止无效的定期更新消息去恢复一个不断开闭的路由。在一条串行链路上路由无效然后又被恢复这是经常发生的,若没有方法稳定这种状况,网络中将会有大量路由更新信息,将影响会聚,甚至导致网络瘫痪。
通过为每个已关闭的路由的恢复或为提高下一个最佳路由修改前网络的稳定性设置一个允许定时器,有助于防止过度频繁路由修改。“保持关闭”设定的时间段通常大于用某个路由变化消息更新整个网络所需的时间。当路由器从临近结点接收到一条更新消息,表明一个原来可到达的网络现已不可到达时,路由器的保持关闭定时器即开始工作。如在定时器停止计时之前,从临近的路由器接收到一新的路由更新消息,而且这条新路由包含的跳数小于接收该路由消息之前的跳数,那么路由器将取消保持关闭。否则,路由器会忽略更新消息,继续保持关闭,保留原有的路由。
保持关闭使用的是触发更新。触发更新不像定期更新,必须等待规定好的时间再更新,而是由网络的变化立即触发更新,并立即发送给相邻路由器新的路由信息。
当出现下列3种情况:保持关闭定时器期满,更好的路由更新被接收,一个路由被删除之前,则从路由表中删除该路由需要保持的时间,即刷新定时器。保持关闭定时器会被触发更新消息重新设置。
(3)距离向量路由选择协议RIP
路由信息协议RIP是一个真正的距离向量路由选择协议。默认状态下,RIP路由器每隔30s便向邻近路由器发送更新消息。
RIP路由器通过UDP端口520收发路由更新消息。
RIP定义两种消息类型:请求消息和应答消息。请求消息用来从其他路由器那里请求路由信息,应答消息则用来传输被请求的路由信息。初始化时RIP路由器每隔30s便从所有激活的RIP接口发送出应答消息。
在路由协议中可用多种标准衡量开销,RIP采用最简单的只用跳数计量的方法,并在默认时所允许的最大跳数为15跳,超过15跳被认为不可达。RIP的最大跳数规定避免了“计数到无穷”问题,但同时也限制了网络应用规模,因此,在大型互联网中不适合应用RIP。
除规定最大跳数,RIP还使用水平分割、路由中毒、保持关闭这些策略避免路由环路产生及保持路由稳定。
RIP使用3种类型的定时器来控制其性能:
●路由更新定时器。用于设定定期路由更新的时间间隔,常用值30s。
●路由失效定时器。值90s。
●路由刷新定时器。用于设置一个路由成为无效路由并将其从路由表中删除的时间,常用值240s。在将该路由从路由表中删除之前,路由器会通知邻近路由器这个路由即将消亡。路由刷新定时器的值一定要大于路由失效计数的值。因为需要足够的时间在表更新之前通知邻近路由器路由失效的消息。通常,路由刷新定时器值会设置成路由更新定时器的值的倍数。
RIP有两个版本。RIP v1建立在IP地址的子网掩码出现之前,它使用的是分级路由选择,也就是说网络中所有设备必须使用相同的子网掩码。RIPv2提供了称为前缀路由选择的信息,并且利用路由更新来传送子网掩码信息。
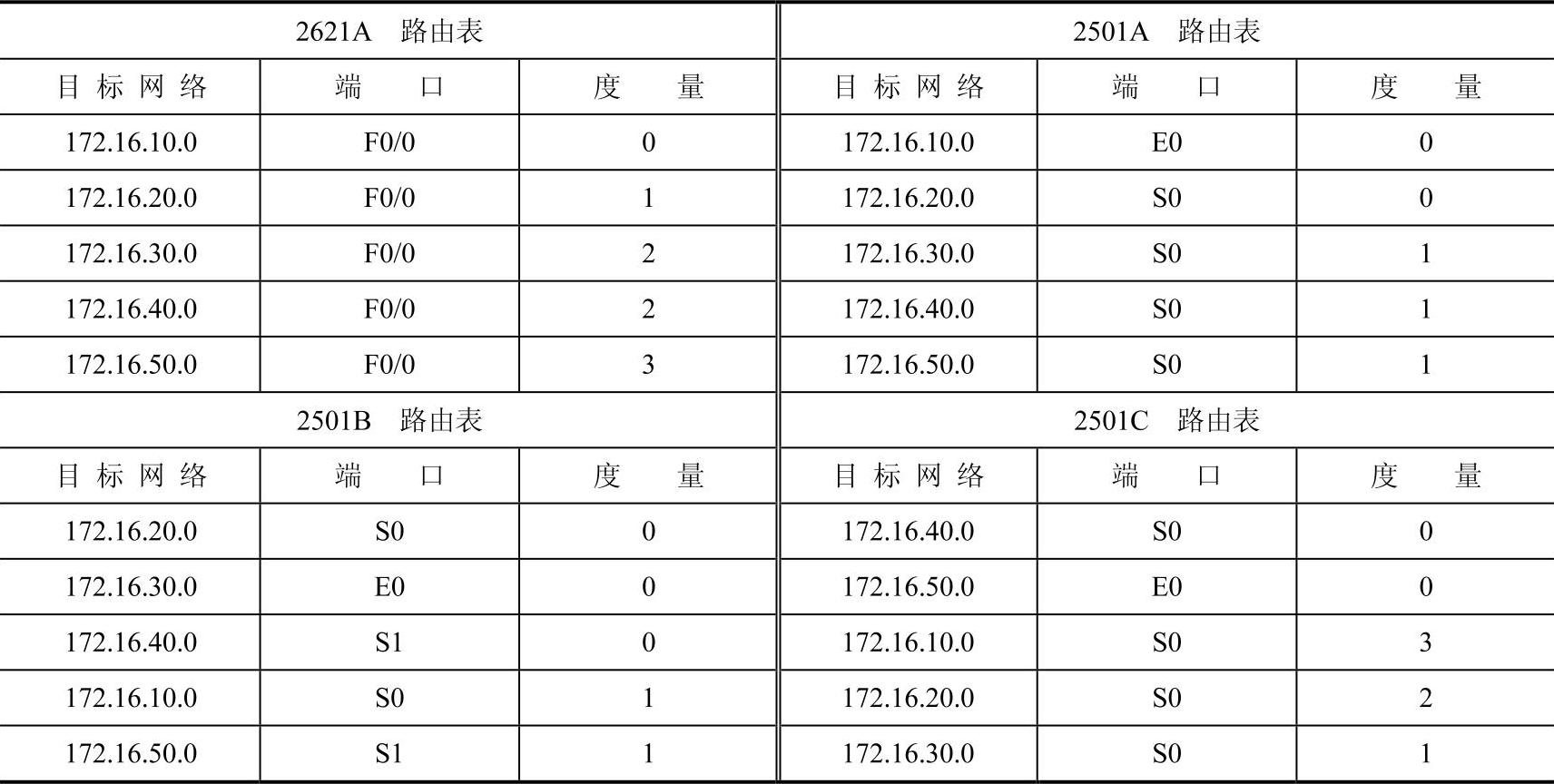
RIP报文格式如图7-6所示。
命令:用数字形式描述报文类型的信息。1表述该报文是个请求报文,2表示该报文是应答报文。
版本:区别使用的RIP版本号。一个路由器上允许同时实现RIP的两个版本。
网络i系列:指出目标地址所属的网络地址系列。用来区别BSD UNIX操作系统中使用的不同地址系列。
网络i的IP地址:指明目标网络地址到网络i的距离:用跳数表示从源路由器到目标路由器的距离。
图7-6 RIP报文格式
2.链路状态算法及OSPF
在分析该算法之前,假设每个结点都能知道与它相邻结点链路状态及每条链路的开销。链路状态算法的基本思想是:每个结点都知道如何到达其邻近结点。如能保证信息可完整、准确传播到每个结点,那么每个结点就能根据这些信息建立一个完整的网络映射图,从而能够在各个结点之间传送数据。链路状态算法通过两种机制实现上述思想:链路状态信息的可靠传播机制和根据链路状态信息进行路由计算的机制。
(1)可靠传播机制
可靠传播是指保证参与路由协议的所有结点都能获得来自其他结点的链路状态信息的副本的处理过程。可靠传播基本思想是每个结点都把各自的链路状态信息传送给与其直接相连的结点,接收结点再沿着与它直接相连的结点继续传送该信息,重复该过程,直到该信息传送到网络中每个结点。
结点向相邻结点传送信息之前,先要创建一个更新信息,该信息称为链路状态分组(Link-State Packet,LSP)。该分组包含以下内容:
●创建该分组的结点的标识ID。
●与该结点直接相连的结点的列表和到这些结点的链路开销。
●一个序号。
●分组生存期(TTL)。
其中,结点标识ID和关于相邻结点的列表以及链路开销是用来计算路由的,序号和生存期用来保证LSP分组能可靠传送到所有结点。
下面举例说明可靠传播过程。如图7-7所示,表示了LSP在网络中的传播过程。图7-7a中,一个LSP到达结点X,结点X首先检查是否已有一份来自同一个源结点的LSP。如没有,X则存储该LSP。如已有一份该LSP的副本,则比较LSP中的序号。如新LSP中序号值更大,那么X会认为这是新的LSP,则保存该LSP替换旧LSP。如新LSP中序号值小于或等于原来的LSP,那么X就忽略该LSP。这就是LSP传送到结点X的过程。图7-7b中,X将接收到的LSP继续向相邻结点A和C传送。图7-7c中,A和C接收到LSP后不把它向X回发,而继续向它们的相邻结点B传送。由于A和C都会向B发送,因此B会接收到两份相同的LSP,这时B会将首先接收到的LSP保存,而将后接收到的忽略。图7-7d中,B向D传播LSP。由于D没有相邻结点,传播过程到此结束。
结点在两种情况下会产生LSP。一是周期性产生,由周期性定时器触发。二是拓扑结构变化时产生,由外界环境的变化触发。通过链路层的协议和发送周期性“hello”分组可检测到拓扑结构的变化。具体说:每个结点都会在规定的时间间隔内向它的相邻结点发送“hello”分组,如足够长时间内没有收到来自相邻结点的“hello”分组,就说明通向邻居的链路出现问题,于是产生一个新的LSP通知其他结点出现的新情况。

图7-7 链路状态分组的扩散
a)接收新LSP b)继续传送到A,C c)A,C传到B,B保留1份 d)最终B传到D,结束
为保证信息可靠传输,链路状态算法规定LSP需携带序号。每当结点产生一个新的LSP,序号就加1。这些序号不能重叠,因此需要很大字段存储序号。如一个结点出现故障后又恢复了,那么其序号将从0开始。如该结点出现故障后很长一段时间都没有恢复,那么所有关于该结点的LSP都会超时,否则该结点最终会接收到一份自身的带有很大序号的LSP,然后将序号加1后作为自己的序号。
除需要携带序号,LSP还携带生存期,TTL用来确保旧的LSP能最终从网络中消除。结点在将新接收到的LSP传播到相邻结点之前,会将LSP的TTL值减l。这样每次准备传送到下一个结点都减1,直到TTL值减到0。当结点接收到的LSP的TTL值为0时,该结点会删除收到的LSP,这样就保证生存期结束的LSP在网络上消失。
(2)路由计算机制
路由的计算采用最短路径优先算法(SPF),这是一典型的链路状态路由协议。在SPF算法中,每个路由器被当做一个根(ROOT)来计算其到每个目的路由器的距离。当该路由器获得其他各路由器发送过来的LSP后,就能创建一个统一的数据库,从而得到完整的网络拓扑结构图,因此也就能计算出到各结点的最佳路径。该结构图类似于一棵树,因此被称为最短路径树。由于该算法是基于图论中的Dijkstra最短路径算法,因此也称Dijkstra算法。(https://www.xing528.com)
在SPF算法中,每个路由器有两张表。试探表(Tentative)和证实表(Confirmed)。两张表中每条记录都是以目的地、开销、下一跳格式组成。算法步骤如下:
●初始化时,源路由器将自身记录放入证实表。目的地为自身,开销为0,下一跳空缺。
●查询最后加入到证实表中的路由器的LSP。该路由器称Next,其相邻路由器称Neighbor。
●根据Next的LSP,填写试探表内容。如Neighbor既不在证实表中,也不在试探表中,那么直接把关于Neighbor的信息以目的地(Destination)、开销(Cost)、下一跳(NextHop)的格式添加到试探表中。如Neighbor已在当前试探表中,就计算从源路由器到Neighbor的距离,若开销小于当前表中开销,则用新记录替换当前记录。如开销大于当前开销,则忽略。
●将试探表中开销最小的记录转移到证实表中,该记录中的目的路由器作为新的Next。继续新一轮计算。如试探表内容为空,则结束计算。通过实例进一步理解链路状态算法。如图7-8所示,有A、B、C、D4个路由器和若个条链路。链路边上标明各链路开销。以D路由器为例,表7-6说明各路由器建立路由表的过程。
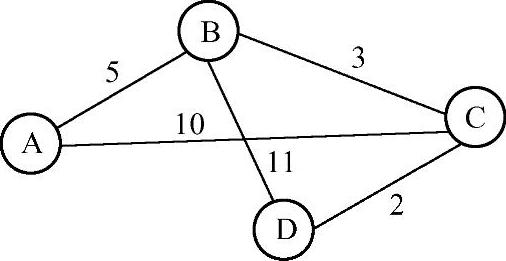
图7-8 链路状态路由选择算法的拓扑结构图举例
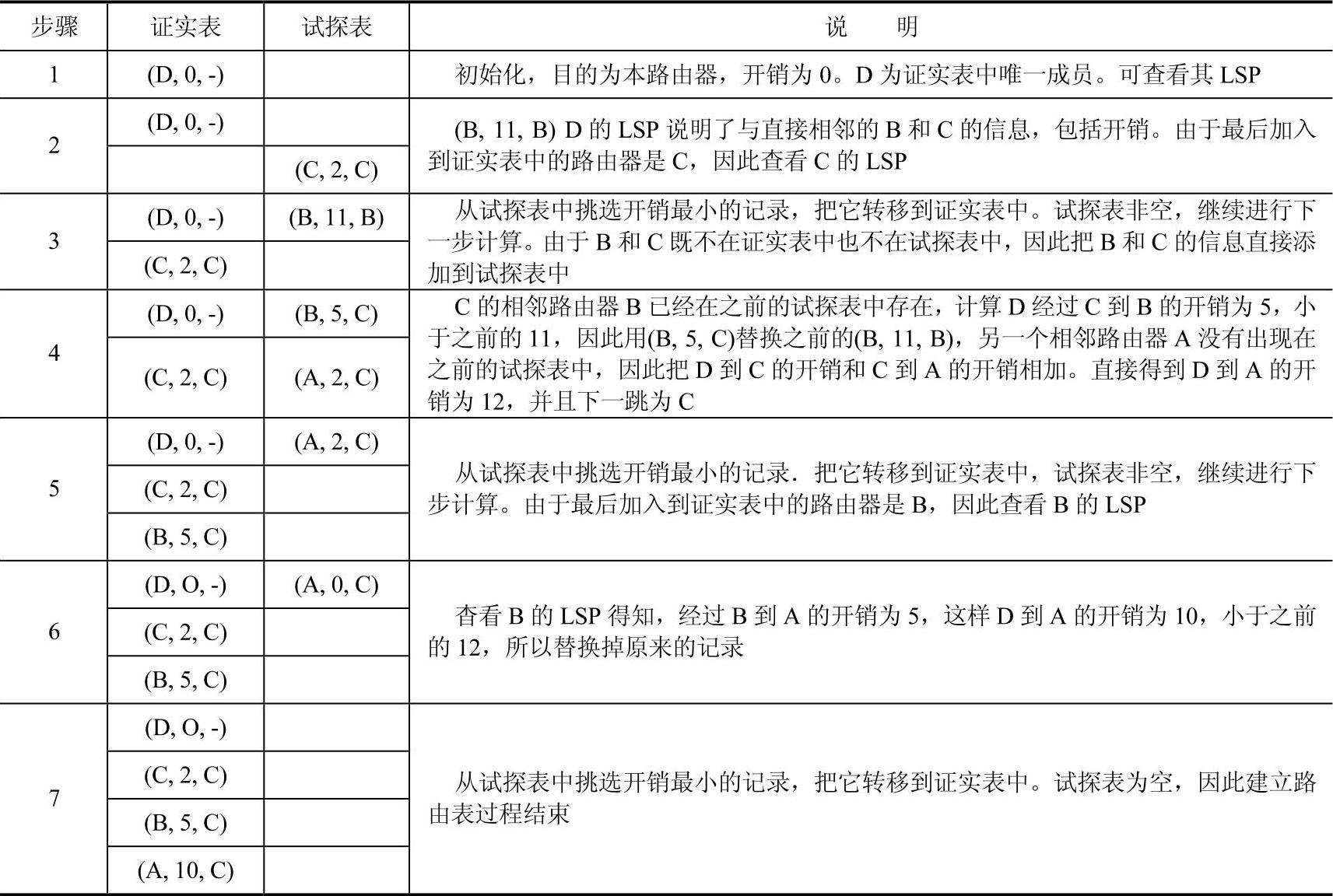
表7-6 D建立路由表的过程
(3)开放最短路径优先协议OSPF
OSPF(Open Shortest Path First)是一种基于SPF算法的典型链路状态路由协议,一般用于同一路由域内。所谓路由域是指一个自治系统(Autonomous System,AS),指一组通过统一的路由政策或路由协议交换路由信息的网络。
OSPF在基本的链路状态算法上增加了一些特性,包括如下内容。
●路由消息确认:有些错误配置的主机会认为它能以零开销到达任何一台主机。当消息在网络中发布后,相邻路由器都会指向这个主机,该主机会接收到大量数据。一般主机会将所有数据丢弃,导致网络停止。在此情况下,通过路由消息确认进行改善。
●层次扩展:OSPF通过将域(domain)划分成区(area),使原有层次得到扩展。这一方法使域内路由器不必知道如何到达域内每个网络,只需知道如何到达某区即可。这样做可有效减少通信量。
●负载均衡:OSPF允许到同一目的地的多条相同开销的路由,使通信量分散在几条路由上,避免单一路由的堵塞。
OSPF有5种消息类型:Hello报文、数据描述报文(Database Description)、链路状态请求报文(Link State Request)、链路状态更新报文(Link State Update)和链路状态应答报文(Link State Acknowledgment)。所有不同类型报文都有相同报文头。
OSPF报文头格式如图7-9所示。各字段含义如下。

图7-9 OSPF的报文头格式
Version:OSPF的版本号。
Type:OSPF报文类型。
Packetlength:OSPF报文的长度,以字节为单位,包括了标准OSPF的报文头。
Router ID:源路由器的ID。
Area ID:区号。
Checksum:检验和。
Authentication type:认证类型。
Authentication:认证。
1)Hello报文格式如图7-10所示,各字段含义如下。

图7-10 HELLO报文格式
表格前6行:标准报文头。Hello报文的类型号是l。
Network Mask:子网掩码。
Hello Interval:两个Hello报文之间的时间间隔。
Options:选项。
Router Priority:路由器优先级。用于选择指定(或后备)路由器。设定为0时,该路由器将无权成为指定(或后备)路由器。
Router Dead Interval:沉默路由器被认为是断开的时间间隔。
Designated Router:指定路由器IP接口地址。如没有指定路由器,该值将被设定为0.0.0.0。
Backup Designated Router:后备指定路由器的IP接口地址。如没有后备指定路由器,该值将被设定为0.0.0.0。
Neighbor:所有邻居路由器的ID号。
2)数据描述报文(Database Description)格式如图7-11所示,各字段的含义如下。
表格的前6行:标准报文头。数据描述报文的类型号是2。
Interface MTU:MTU接口。如数据描述报文是在虚拟链路上传送,MTU接口应设置0。
Options:选项。
I-bit:起始比特位。如该位设置为l,则表示该报文是数据描述报文序列中第一个报文。
M-bit:More比特位。如该位设置为1,则表示后面还有更多报文。
MS-bit:主/从比特位。如该位设置为l,则意味在数据交换过程中,该路由器是主路由器;如该位设置为0,则是从路由器。
DD sequence number:DD序列号,用于将收集到的数据描述报文排序。
报文剩下部分由一系列链路状态数据库记录组成。数据库中每个LSA由各自的LSA头描述(LSA头结构后面介绍)。

图7-11 数据描述报文格式
3)链路状态请求报文(The Link State Request Packet)格式如图7-12所示,各字段含义如下。
表格的前6行:标准报文头。链路状态请求报文的类型号是3。
LStype:链路状态类型。链路状态类型决定LSA的格式和功能。不同LSA有不同名称。
LinkStateID:链路状态ID。
AdvertisementRouter:通告路由器。该栏指明发布LSA的源路由器ID。对于路由器LSA,该栏等同于链路状态ID栏;对于网络LSA,该栏指的是网络目的路由器,对于汇总LSA,该栏指区域边界路由器;对于自治域外部LSA,该栏指自治域边界路由器。
LStype、LinkState ID和AdvertisementRouter构成LSA头部。这三部分组合唯一确定一份LSA。

图7-12 链路状态请求报文格式
4)链路状态更新报文(The Link State Update Packet)格式如图7-13所示,各字段含义如下:
表格的前6行:标准报文头。链路状态更新报文的类型号是4。
#LSAs:更新报文中包含的LSA数量。
LSAs:LSA列表。每个LSA都是以20B的LSA头开始。

图7-13 链路状态更新报文格式
5)链路状态应答报文(The Link State Acknowledgment Packet)格式如图7-14所示。其参数含义如下。
表格的前6行:标准报文头。链路状态应答报文的类型号是5。
An LSA Header:通过每个LSA的头部来描述已经应答的LSA。

图7-14 链路状态应答报文格式
OSPF中链路状态消息的基本构件块称做链路状态通知(Link State Advertisement,LSA)。OSPF路由器之间使用LSA来交换各自的链路状态信息,并把获得的信息存储在链路状态数据库中。各OSPF路由器独立使用SPF算法计算到各个目的地址的路由。LSA也就是链路状态算法时提及的LSP。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。