



下面给出用数据挖掘方法产生摩擦模糊规则库的主要步骤,这种方法的优点保证了无论是用小样本数据还是大样本数据产生的摩擦模糊规则库都是完备的。另外,这种方法保证了即使在样本数据中含少量坏数据,产生的规则库仍能保证模糊模型的性能,即规则库具有良好的鲁棒性。
对于给定的速度和摩擦力采样数据对
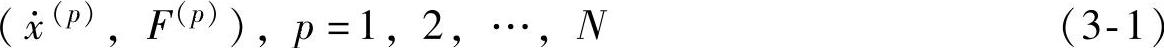
式中 ,表示速度;
,表示速度;
F∈R,表示摩擦力。
设计任务是如何从采样数据对式(3-1)中提取模糊规则,从而确定一个映射函数f: 。设计的方法由下面几个步骤组成:
。设计的方法由下面几个步骤组成:
步骤1.输入输出变量的模糊区间划分
由前面的摩擦模型可知摩擦力是速度的函数,即摩擦力随速度的变化而变化。故把速度作为模糊系统的前提变量,而把摩擦力作为结论变量。设输入变量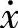 域值区间取[
域值区间取[ ,
, ],在此域值区间对
],在此域值区间对 取模糊集合A(
取模糊集合A(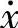 )={
)={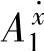 ,…,
,…,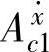 },隶属度函数为高斯函数。另设输出变量F域值区间取[F-,F+],在此域值区间对F取模糊集合B(F)={
},隶属度函数为高斯函数。另设输出变量F域值区间取[F-,F+],在此域值区间对F取模糊集合B(F)={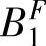 ,…,
,…,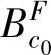 },隶属度函数为三角型函数。
},隶属度函数为三角型函数。
步骤2.普通行关系数据库转换为模糊型关系数据库首先,把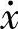 和F的采集数据存放到普通型关系数据库表中。然后把
和F的采集数据存放到普通型关系数据库表中。然后把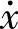 和F的数据转换成隶属度函数值存放到模糊型关系数据库表中。在速度摩擦力数据对的普通型关系数据库中,设L1={
和F的数据转换成隶属度函数值存放到模糊型关系数据库表中。在速度摩擦力数据对的普通型关系数据库中,设L1={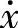 ,F}表示属性集,那么tp表示下面TL1记录集合的第p个元组,也就是
,F}表示属性集,那么tp表示下面TL1记录集合的第p个元组,也就是
TL1={t1,…,tp,…,tN}(3-2)在速度摩擦力数据对的模糊型关系数据库中,设L2={A(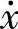 )∪B(F)}表示属性集,μ(tp)表示tp模糊化后的隶属度值,那么μ(tp)表示下面TL2记录集合的第p个元组,也就是
)∪B(F)}表示属性集,μ(tp)表示tp模糊化后的隶属度值,那么μ(tp)表示下面TL2记录集合的第p个元组,也就是
TL2={μ(t1),…,μ(tp),…,μ(tN)}(3-3)
至此,将TL1={t1,…,tp,…,tN}一个普通型关系数据库转化为TL1={μ(t1),…,μ(tp),…,μ(tN)}模糊型关系数据库。为了便于理解上述过程,一个简单的例子如表3-1。
表3-1 普通记录集合与模糊记录集合
 (https://www.xing528.com)
(https://www.xing528.com)
步骤3.计算摩擦模糊规则的支持度
从数据挖掘的角度看,如果一条模糊规则有实际意义,它必须具有足够的支持度,它反映了样本元组对该条规则的支持程度。现定义支持度如下
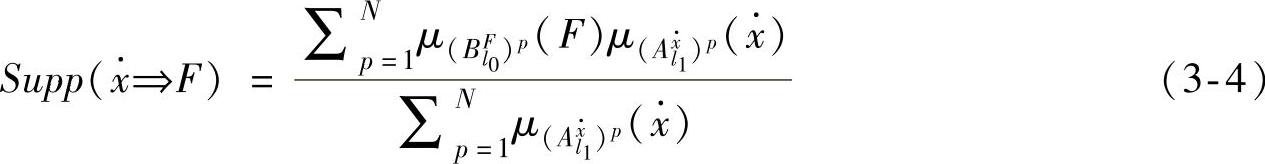
式中μ(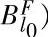 p(F)和μ(
p(F)和μ(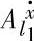 )p(
)p(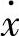 )——分别表示第p条记录上F和
)——分别表示第p条记录上F和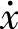 所对应的隶属函数值;
所对应的隶属函数值;
N——在TL2数据库的总记录数;
l0∈{1,…,c0},l1∈{1,…,c1}。
为了简化计算,也可以用下式计算支持度
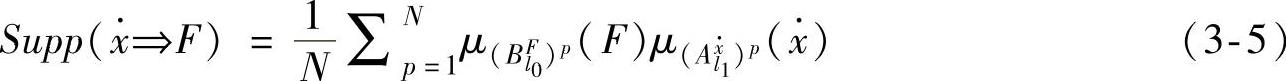
由上面的支持度定义可以看出,数据挖掘法所产生的某条模糊规则是所有空间样本数据TL1={t1,…,tp,…,tN}选举出的结果。有理由相信数据挖掘方法所选举出的规则比单纯用空间样本部分数据(如WM方法)所选举出的规则更可靠、更可信。即使在样本数据中有个别坏数据,也会被众多好数据进行有效的屏蔽,由个别坏数据选举出坏规则的现象将在一定程度上得到抑制。
步骤4.创建完备的摩擦模糊规则库
首先,算法要保证由前提变量构成的每个模糊子空间都能被遍历;其次,结论变量在模糊子空间选用哪个模糊集,由规则的最大支持度决定。算法的主要步骤如第二章所示,通过上面的遍历产生了完备的模糊规则库。如图3-4所示,我们用一个简单例子说明此过程。设前提变量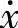 和结论变量F的模糊集合分别为A={
和结论变量F的模糊集合分别为A={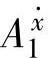 ,…,
,…,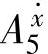 }和B={
}和B={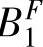 ’’
’’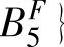 。对于{
。对于{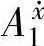 },我们首先分别计算{
},我们首先分别计算{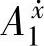 ,
,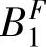 },{
},{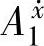 ,
,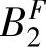 },{
},{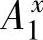 ,
,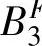 },i{
},i{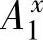 ,
,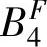 )}和{
)}和{ ,
,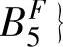 的支持度,然后结论变量F最终选择的模糊集由最大支持度决定。对于
的支持度,然后结论变量F最终选择的模糊集由最大支持度决定。对于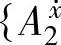 ),{
),{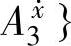 ,
,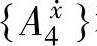 和
和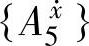 重复上面的过程。由这些规则构成了所有模糊规则的一个子空间,该子空间是最后选择的模糊规则库(由图3-4中星号构成的空间)。
重复上面的过程。由这些规则构成了所有模糊规则的一个子空间,该子空间是最后选择的模糊规则库(由图3-4中星号构成的空间)。
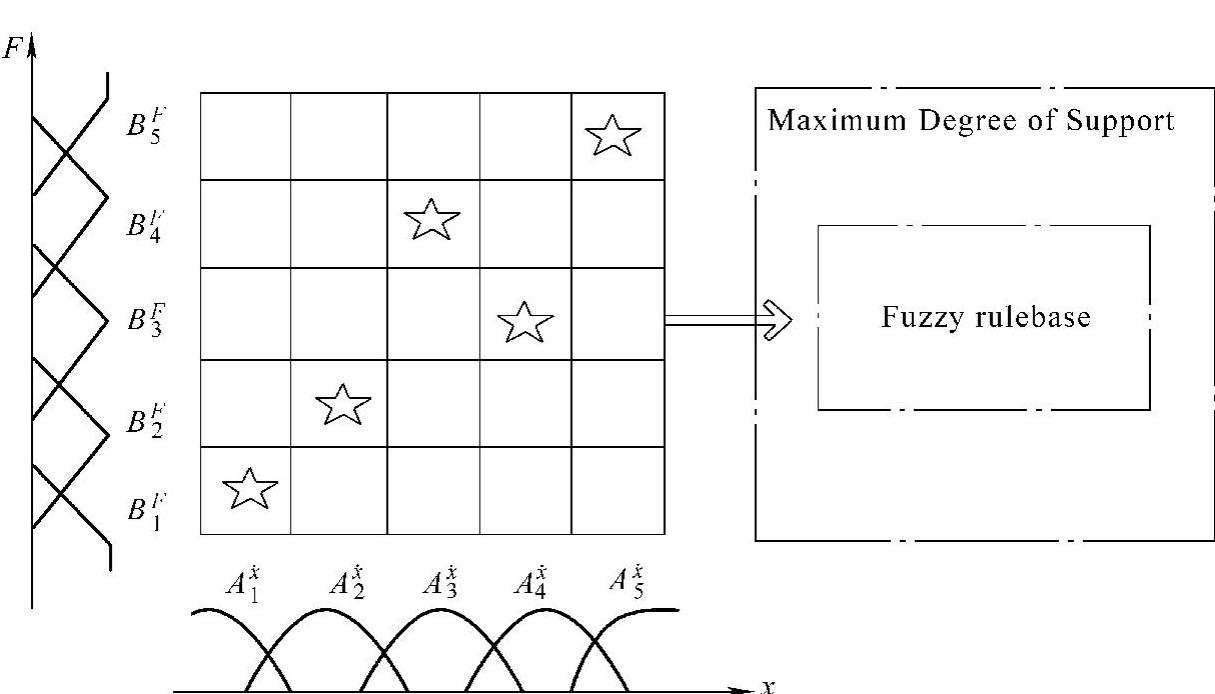
图3-4 基于最大支持度决定的模糊规则子空间
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。