



无监督学习就是采用没有标签的训练数据进行学习,最主要的无监督学习方法是聚类的方法。可以用公式描述为[31]:
设X是聚类集,即X=(x1,x2,…,xn),定义X的m聚类集合Ω,将X分割成m个集合(聚类)C1,…,Cm,使其满足下面三个条件:
Ci≠φ,i=1,…,m;
Umi=1Ci=X;
Ci∩Cj=φ,i≠j,i,j=1,…,m;
聚类的处理过程如图1-7所示[33]。(https://www.xing528.com)
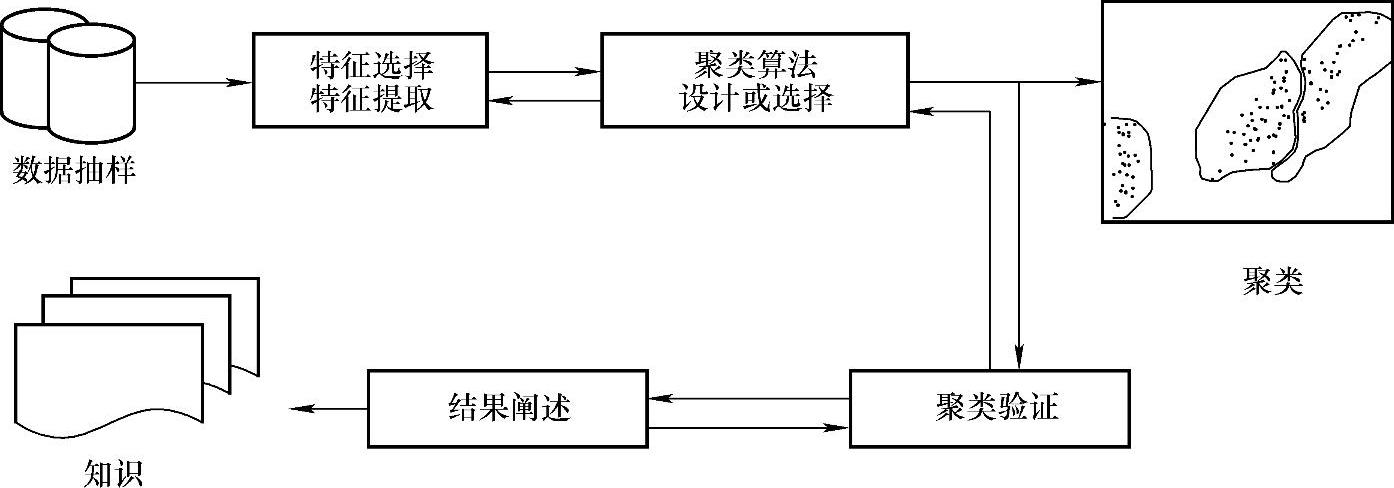
图1-7 聚类处理的过程
图1-7中聚类处理过程的主要有四个步骤:特征选择/特征提取、聚类算法设计或选择、聚类验证、结果阐述。其中特征选择/特征提取是利用一些变换从原始的特征中产生有用和新型的特征。聚类算法设计或选择中因为聚类是普遍存在的,且已有大量的聚类算法被开发出来用于解决具体领域中的不同问题。但是不存在一种聚类算法可以普遍用于解决所有问题。在技术层面上,开发一个统一的关于聚类推理和多种聚类方法的框架是非常困难的。聚类验证是必须的。因为给定一个数据集,不管是否存在结构,每个聚类算法都能产生一个划分。此外,不同的方法通常会导致不同的聚类;即使是相同的算法,参数辨识或输入模式的呈现顺序也可能影响最终的结果。因此,提供有效的评价标准和准则是十分重要的,因为它为用户提供一种置信度,这种置信度来自于其使用算法产生的聚类结果。聚类结果分析必须要符合实际应用。聚类的最终目标是从原始数据中为用户提供有意义的见解,使他们能够有效地解决遇到的问题。因此利用相关领域专家解释数据划分,进一步的分析甚至实验可能要求保证提取知识的可靠性。
常用的聚类方法有:基于层次自聚类的重心法(Centroid Linkage),BIRCH层次聚类算法(Balanced Iterative Reducing and Clustering using Hierarchies),CURE算法(Clustering Using REpresentatives),ROCK算法(RObust Clustering u-sing linKs)等;基于矢量量化的K均值聚类算法(K-means),迭代自组织数据分析法(Iterative Self-Organizing Data Analysis Technique,ISODAT)等;基于混合密度估计的高斯混合密度降解模型(Gaussian Mixture Density Decomposition,GMDD);基于图类的Delaunay三角剖分图(Delaunay Triangulation Graph,DTG),高连接子图(Highly Connected Sub-graphs,HCS),集群近似搜索技术(ClusterAffinity Search Technique,CAST);基于神经网的学习矢量量化(Learning Vector Quantization,LVQ),自组织特征映射模型(Self-Organizing Feature Map,SOFM),超椭球聚类网(Hyper-Ellipsoidal Clustering network,HEC)等;基于大型数据集的算法有基于密度的噪声应用空间聚类(Density-Based Spatial Clus-tering of Applications with Noise,DBSCAN),基于密度分布函数的聚类算法(DENsity-based CLUstEring,DENCLUE)等。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。