



1.数据存储技术
为保证高可用、高可靠和经济性,云计算采用分布式存储的方式来存储数据,采用冗余存储的方式来保证存储数据的可靠性,即为同一份数据存储多个副本。另外,云计算系统需要同时满足大量用户的需求,并行地为大量用户提供服务。因此,云计算的数据存储技术必须具有高吞吐率和高传输率的特点。云计算的数据存储技术主要有美国谷歌公司的非开源的Google文件系统(Google File System,GFS)和美国Apache软件基金会Hadoop开发团队开发的开源Hadoop分布式文件系统(Hadoop Distributed File System,HDFS)。
以GFS为例。GFS是一个管理大型分布式数据密集型计算的可扩展的分布式文件系统。它使用廉价的商用硬件搭建系统并向大量用户提供容错的高性能的服务。GFS和普通的分布式文件系统的区别见表5-6。
表5-6 GFS与传统分布式文件系统的区别

GFS由一个Master和大量块服务器构成。Master存放文件系统的所有的元数据,包括名字空间、存取控制、文件分块信息、文件块的位置信息等。GFS中的文件切分为64MB的块进行存储。在GFS中,采用冗余存储的方式来保证数据的可靠性。每份数据在系统中保存3个以上的备份。为了保证数据的一致性,对于数据的所有修改需要在所有的备份上进行,并用版本号的方式来确保所有备份处于一致的状态。
客户端不通过Master读取数据,避免了大量读操作使Master成为系统瓶颈。客户端从Master获取目标数据块的位置信息后,直接和块服务器交互进行读操作。
GFS的写操作将写操作控制信号和数据流分开,如图5-6所示。客户端在获取Master的写授权后,将数据传输给所有的数据副本,在所有的数据副本都收到修改的数据后,客户端才发出写请求控制信号。在所有的数据副本更新完数据后,由主副本向客户端发出写操作完成控制信号。
未来的发展将集中在超大规模的数据存储、数据加密和安全性保证及继续提高I/O速率等方面。
2.数据管理技术
云计算系统对大数据集进行处理、分析,向用户提供高效的服务。因此,数据管理技术必须能够高效地管理大数据集。其次,如何在规模巨大的数据中找到特定的数据,也是云计算数据管理技术所必须解决的问题。
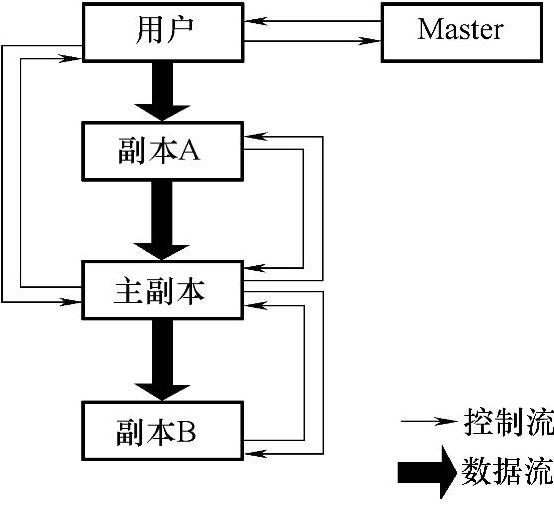
图5-6 GFS写操作
云计算的特点是对海量的数据存储、读取后进行大量的分析,数据的读操作频率远大于数据的更新频率,云中的数据管理是一种读优化的数据管理。因此,云计算系统的数据管理往往采用数据库领域中列存储的数据管理模式,将表按列划分后存储。
云计算的数据管理技术最著名的产品是美国Google公司的BigTable数据管理技术,同时Hadoop的开发团队正在开发BigTable的开源数据管理模块———HBase。由于采用列存储的方式管理数据,如何提高数据的更新速率及进一步提高随机读速率是未来的数据管理技术必须解决的问题。
下面以BigTable为例。BigTable在很多方面和数据库类似,但它并不是真正意义上的数据库。BigTable数据管理方式设计者美国Google公司给出了如下定义:“BigTable是一种为了管理结构化数据而设计的分布式存储系统,这些数据可以扩展到非常大的规模,如在数千台商用服务器上的达到拍字节(Petabytes,PB)规模的数据。”
BigTable对数据读操作进行优化,采用列存储的方式,提高数据读取效率。BigTable管理的数据的存储结构为,<row:string,column:string,time:int64>->string。BigTable的基本元素是,行、列、记录板和时间戳。其中,记录板是一段行的集合体。(https://www.xing528.com)
BigTable中的数据项按照行关键字的字典序排列,每行动态地划分到记录板中。每个节点管理大约100个记录板。时间戳是一个64位的整数,表示数据的不同版本。
BigTable在执行时需要三个主要的组件:链接到每个客户端的库,一个主服务器,多个记录板服务器。主服务器用于分配记录板到记录板服务器及负载平衡、垃圾回收等。记录板服务器用于直接管理一组记录板,处理读写请求等。
为保证数据结构的高可扩展性,BigTable采用三级的层次化的方式来存储位置信息,如图5-7所示。其中,第一级的Chubby文件中包含根表单的位置,根表单包含所有元数据表单的位置信息,每个元数据表单包含许多用户表的位置信息。
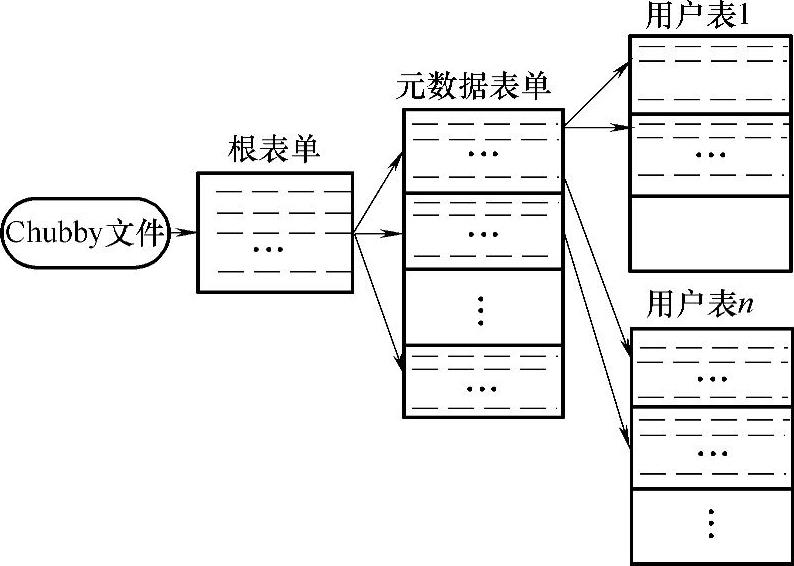
图5-7 BigTable存储记录板位置信息结构
3.软件开发技术
云计算将面临更加严重的软件危机问题,需要降低软件系统的复杂度。为了使用户能更轻松地享受云计算带来的服务,让用户能利用该编程模型编写简单的程序来实现特定的目的。云计算上的编程模型必须十分简单,必须保证后台复杂的并行执行和任务调度向用户和编程人员透明。
MapReduce是美国Google公司提出的一种处理和产生大规模数据集的编程模型,如图5-8所示。Hadoop开发团队也发布了MapReduce的开源实现。现在所有IT厂商提出的“云”计划中采用的编程模型,都是基于MapReduce的思想开发的编程工具。
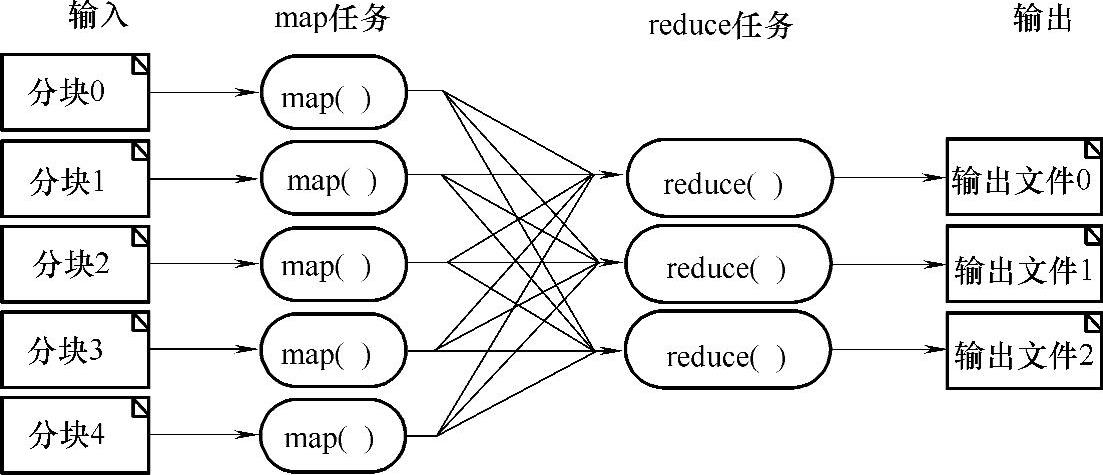
图5-8 MapReduce编程模型示意图
在MapReduce模型中,程序员通过map函数指定对各分块数据的处理过程,然后通过reduce函数指定如何对分块数据处理的中间结果进行归约。这样,程序员只需要指定map和reduce函数就可以编写分布式并行程序。当在机群上运行MapReduce程序时,程序员不需要关心如何将输入的数据进行分块、分配和调度,系统还将自动处理机群内节点失败及节点间通信的管理等问题。
图5-9给出了MapReduce程序的执行过程。从图中可以看出,执行一个MapReduce程序需要五个步骤:输入文件,将文件分配给多个Worker并行地执行(map阶段),写中间文件(本地写),多个Worker并行运行(reduce阶段),输出最终结果。本地写中间文件在减少了对网络带宽的压力同时减少了写中间文件的时间耗费。执行reduce时,根据从Master获得的中间文件位置信息,将reduce命令发送给中间文件所在节点执行,进一步减少了传送中间文件对带宽的需求。
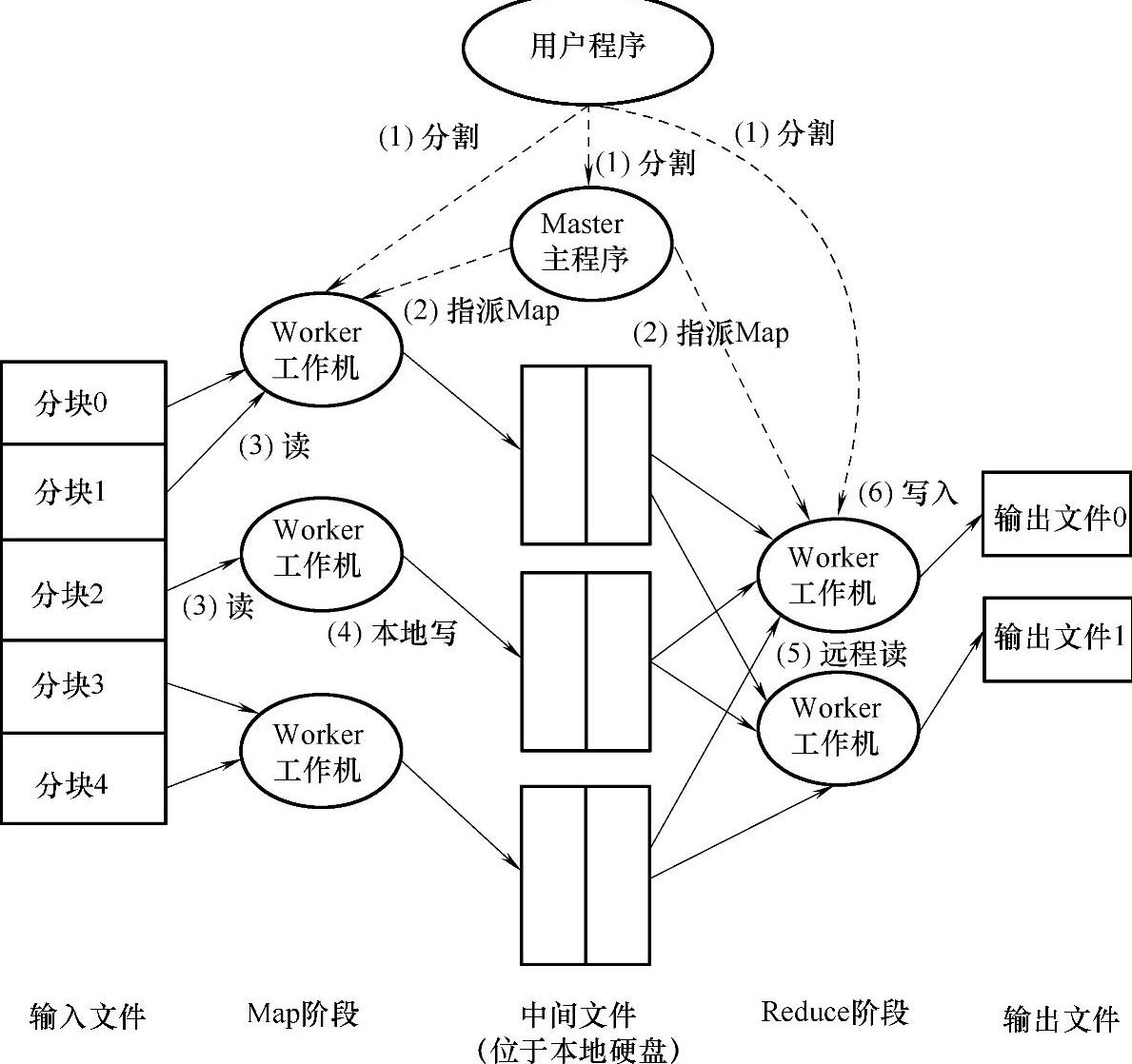
图5-9 MapReduce程序的执行过程
MapReduce模型具有很强的容错性,当Worker节点出现错误时,只需要将该Worker节点屏蔽在系统外等待修复,并将该Worker上执行的程序迁移到其他Worker上重新执行,同时将该迁移信息通过Master发送给需要该节点处理结果的节点。MapReduce使用检查点的方式来处理Master出错失败的问题。当Master出现错误时,可以根据最近的一个检查点重新选择一个节点作为Master并由此检查点位置继续运行。
MapReduce不仅是一种编程模型,同时也是一种高效的任务调度模型。MapReduce这种编程模型并不仅适用于云计算,在多核和多处理器、微处理器及异构机群上同样有良好的性能。该编程模式仅适用于编写任务内部松耦合、能够高度并行化的程序。如何改进该编程模式,使程序员得能够轻松地编写紧耦合的程序,运行时能高效地调度和执行任务,是Ma-pReduce编程模型未来的发展方向。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。