



Spark非常重视打造自己的生态系统,它不仅支持多种外部文件存储系统,还为了提升自己在实际生产中的运行效率提供了多种多样的集群运行模式。Spark部署在单台机器上时,既可以用本地(Local)模式运行,也可以使用伪分布式模式来运行;当以分布式集群部署的时候,可以根据自己集群的实际情况选择Standalone模式(Spark自带的模式)、Yarn模式(Yarn又分为Yarn-Client模式和Yarn-Cluster模式)或者Mesos模式,在这方面Spark的选择显得非常灵活多变。
Standalone模式,即独立模式,通过它可以独立地部署Spark集群,比如当我们只需要借助Spark进行大数据的计算时,此模式是最佳模式。但是当我们同时需要多种计算框架(比如Spark和MapReduce)时,就需要引入外部的资源管理系统(Yarn和Mesos模式)对硬件资源的使用进行调度了。Spark一开始就支持Mesos,这也使得Spark运行在Mesos上会比运行在Yarn上更加灵活,更加自然(比如Mesos又分为粗粒度和细粒度两种调度模式)。而Yarn上的Container资源是不可以动态伸缩的,具体来说,一旦Container启动之后,可使用的资源不能再发生变化,这也使得Yarn目前只支持粗粒度的调度模式。但是对于Yarn运行模式一个好处是由于淘宝网在大量的使用Yarn模式来进行数据计算,这也使得Yarn运行模式的发展很有前景。
总体来说,Spark的各种运行模式虽然在启动方式、运行位置、调度策略上各有不同,但它们的目的基本都是一致的,就是在合适的位置安全可靠地根据用户的配置和Job的需要运行和管理Task。
本章具体介绍Spark的各种运行模式时,我们都会通过它们的实例部署和内部实现原理两个方面来进行分析。通过实例部署可以熟悉如何在生产环境中快速的使用它们;而结合Spark的源代码对每种运行模式的内部实现原理的分析,可以使我们更深层次的了解Spark的运行机制,当在生产中遇到问题时,可以结合着内部实现原理一步步地进行程序调试并解决问题。
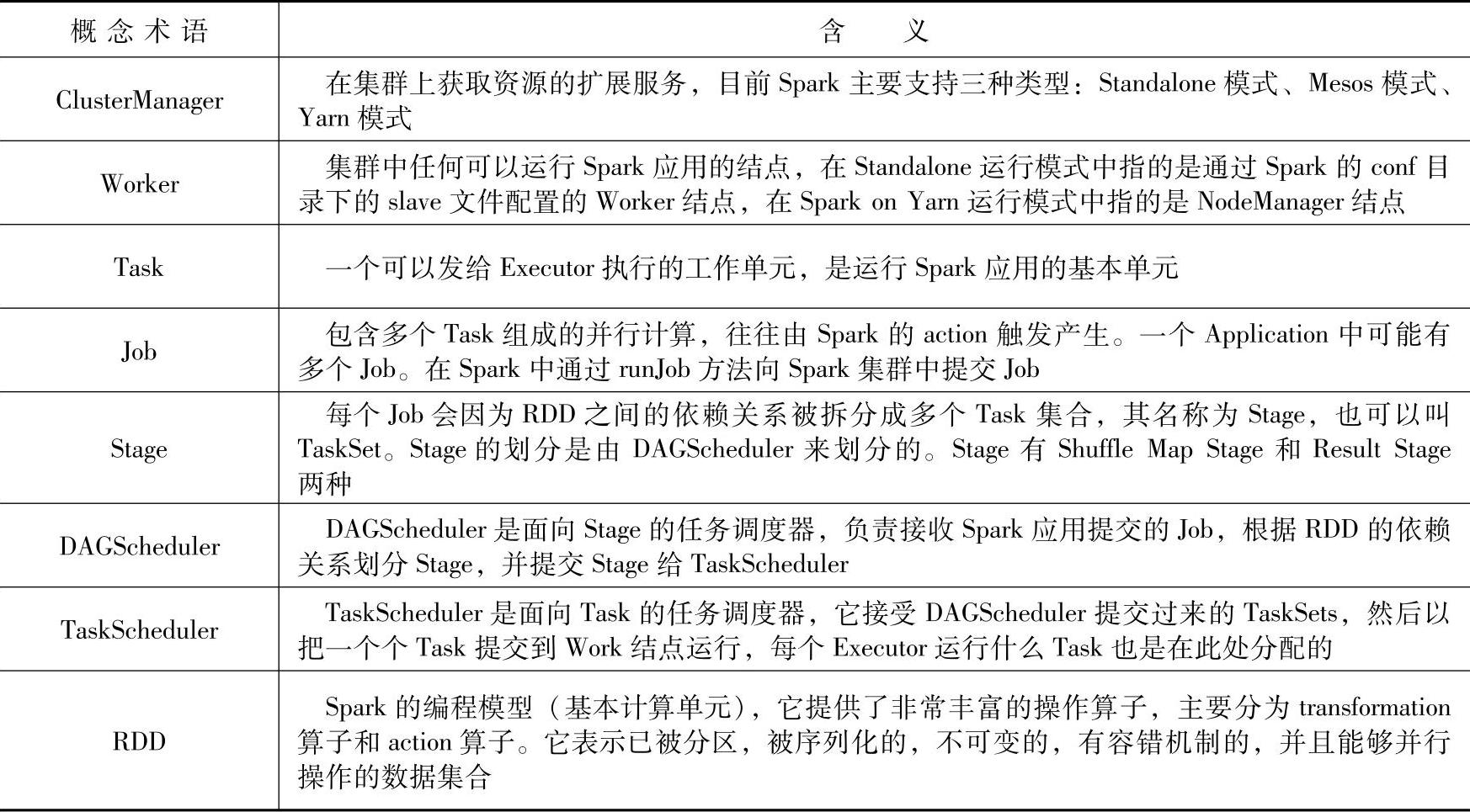
在具体介绍Spark的各种运行种模式之前,首先介绍一些基本的概念术语和编程模型(如表4-1所示)。(https://www.xing528.com)
表4-1 概念术语
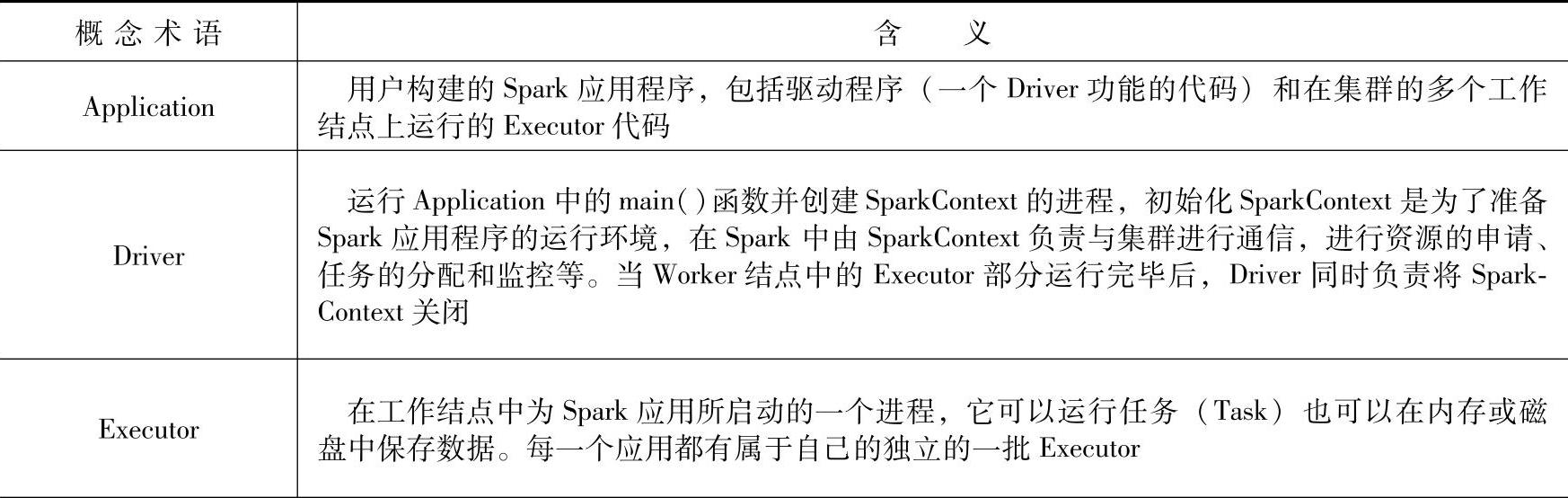
续表
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。