



1.Spark Standalone模式部署的特点
(1)必须把Spark的部署包安装到到每一台结点上,并且每台结点上的Spark的部署目录都应相同。
(2)配置好Master结点到其他结点的SSH无密钥登录,在前面的章节已经演示过SSH的无密钥配置。
(3)修改三个都在$SPARK_HOME/conf目录下的配置文件,三个文件分别是spark-env.sh、spark-defaults.conf和slaves文件(考虑到现在电脑的硬件条件以及我们学习Spark时的最低配置要求,我们在本书中采用的都是三台机器的集群配置,其中一台作为Master结点,两台分别作为Slaves结点)。
2.集群参数配置
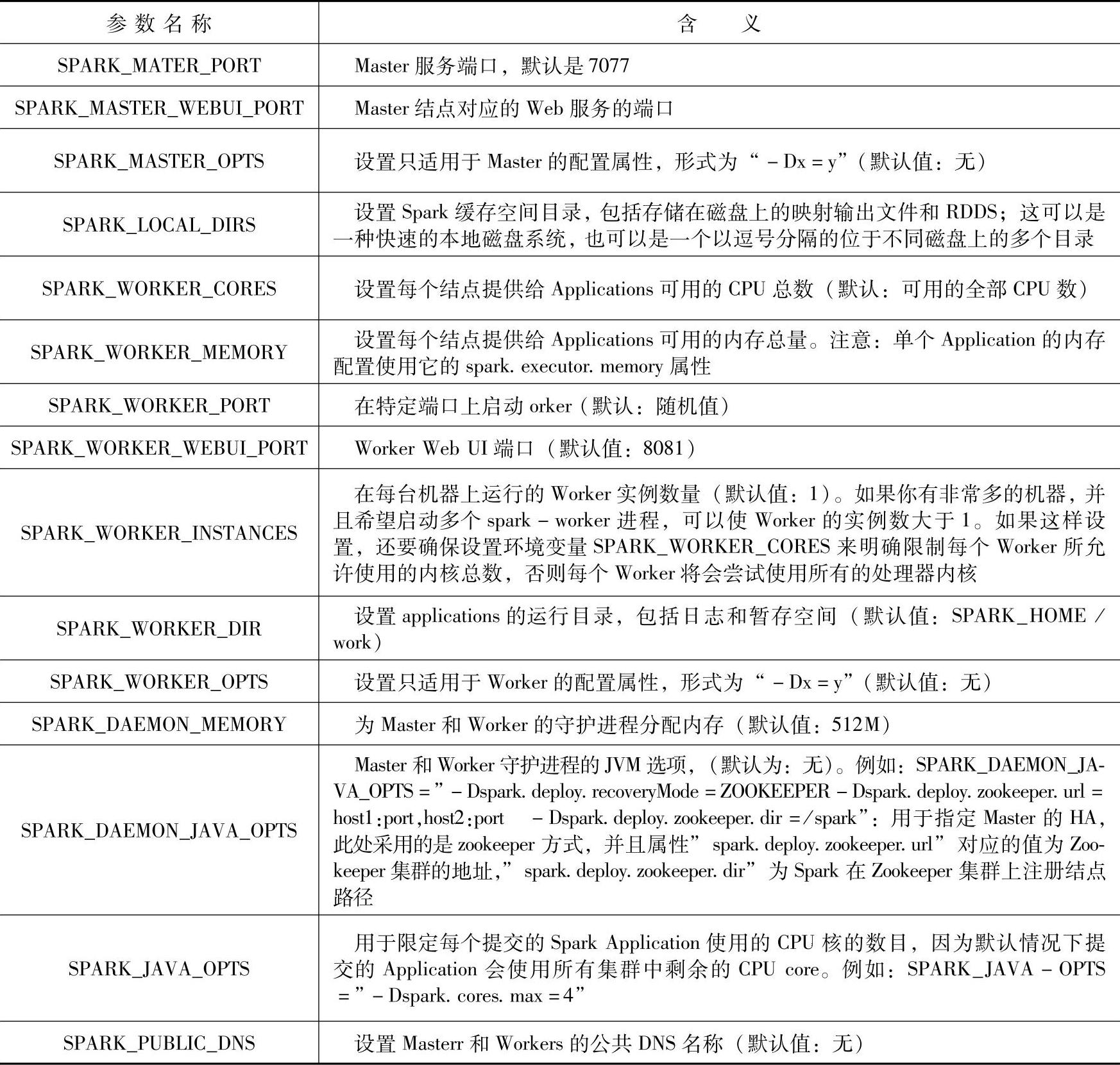
通过对集群参数的配置,我们可以更加灵活的控制Spark集群的运行环境。下面 表4-3列了一些常见的配置参数。
(1)spark-env配置参数。
表4-3 spark-env配置参数
(2)slaves文件配置。Slaves结点中保存的是Worker结点的HostName或者IP,类似如下的配置:


将配置好的Spark文件用SSH的scp命令复制到Spark集群的其他结点的相同路径中,在系统环境变量中配置上SPARK_HOME方便使用spark-shell或者其他Spark的命令脚本。
另外要注意每个Worker结点进程的CPU个数和内存的大小,要结合机器硬件的实际情况来配置,如果一个Worker结点上的所有Worker进程需要的CPU总数目或者内存大小超过当前Worker结点的硬件条件,则Worker进程会启动失败。
3.Standalone模式下的Spark应用程序运行演示
对于Standalone运行模式下的Spark应用程序的运行,在这里我们通过两个实例来演示;一个实例是用Spark的交互工具Spark Submit提交Spark应该程序给Spark集群运行,第二个实例是使用分布式系统中经常使用的HA((High Available)工具Zookeeper来处理Spark应用程序在Spark集群运行过程中的Master单点故障问题。
(1)用Spark Submit工具提交Spark应用程序给集群运行。
在这里我们还是化繁为简,用Spark 1.2源码提供的示例代码SparkPi来演示如何通过Spark Sumit工具提交Spark应用程序给Spark集群运行,然后在Spark的WebUI上查看Spark作业(应用)运行消息。
1)启动HDFS。因为我们是用Spark来进行数据计算,而数据的存储使用的是HDFS,所以这里需要启动HDFS文件系统,但是不需要启动Hadoop。
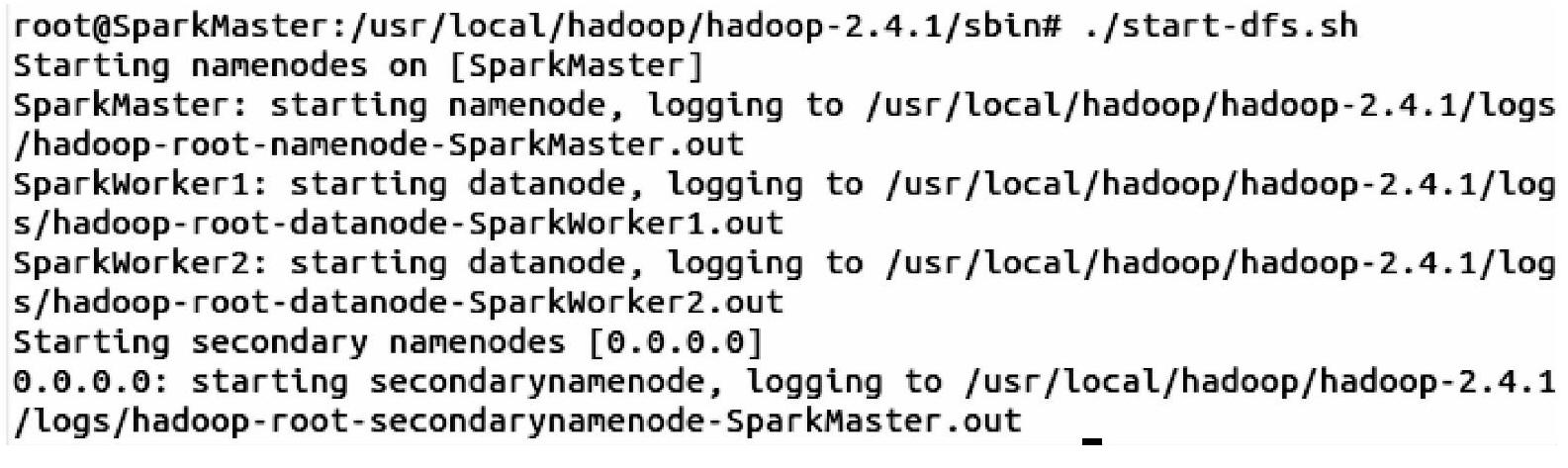
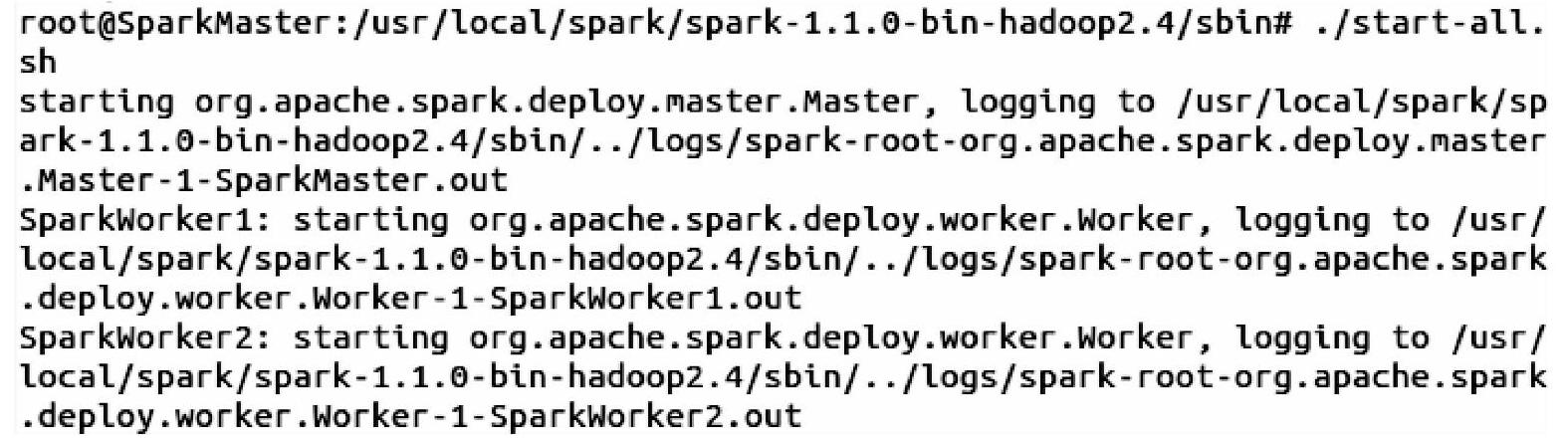
2)启动Spark集群。启动Spark集群的命令在Spark的sbin目录下,这里需要注意的是由于Hadoop也有start-all.sh命令,为了跟它区分开来,我们在Spark的sbin目录下,会用./start-all.sh命令来启动Spark集群,其中“.”表示的就是当前目录了。
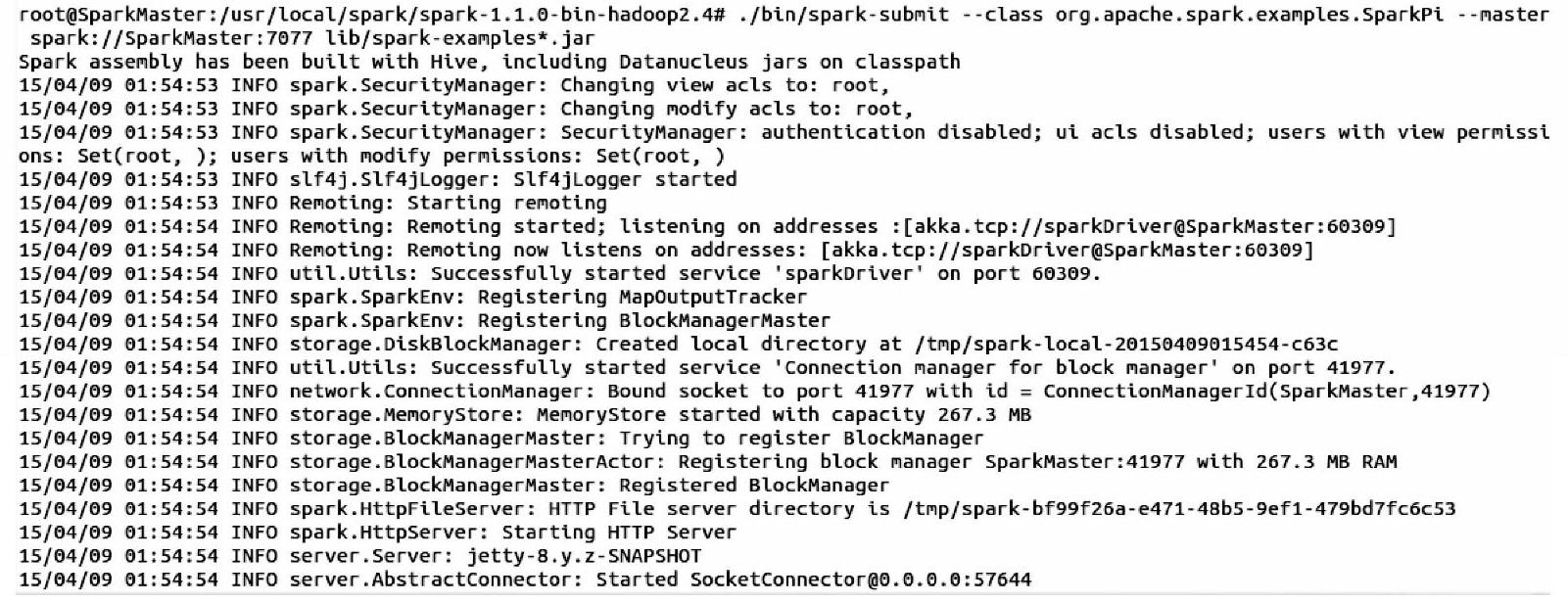
3)用Spark Submit提交作业。在spark-submit命令的附加参数里我们加入了“--class”、“--master”以及伴生对象SparkPi所在的Jar包。
4)在Spark的WebUI控制台查看作业(应用)运行情况(如图4-2所示)。在Spark WebUI中,对作业监控的IP和地址是:MasterIP:8080,其中MasterIP就是Master结点的IP地址或主机名,8080端口是默认的监控端口,如果不想使用8080端口,需要在spark-env.sh文件里面配置SPARK_MASTER_WEBUI_PORT来重新指定端口号。
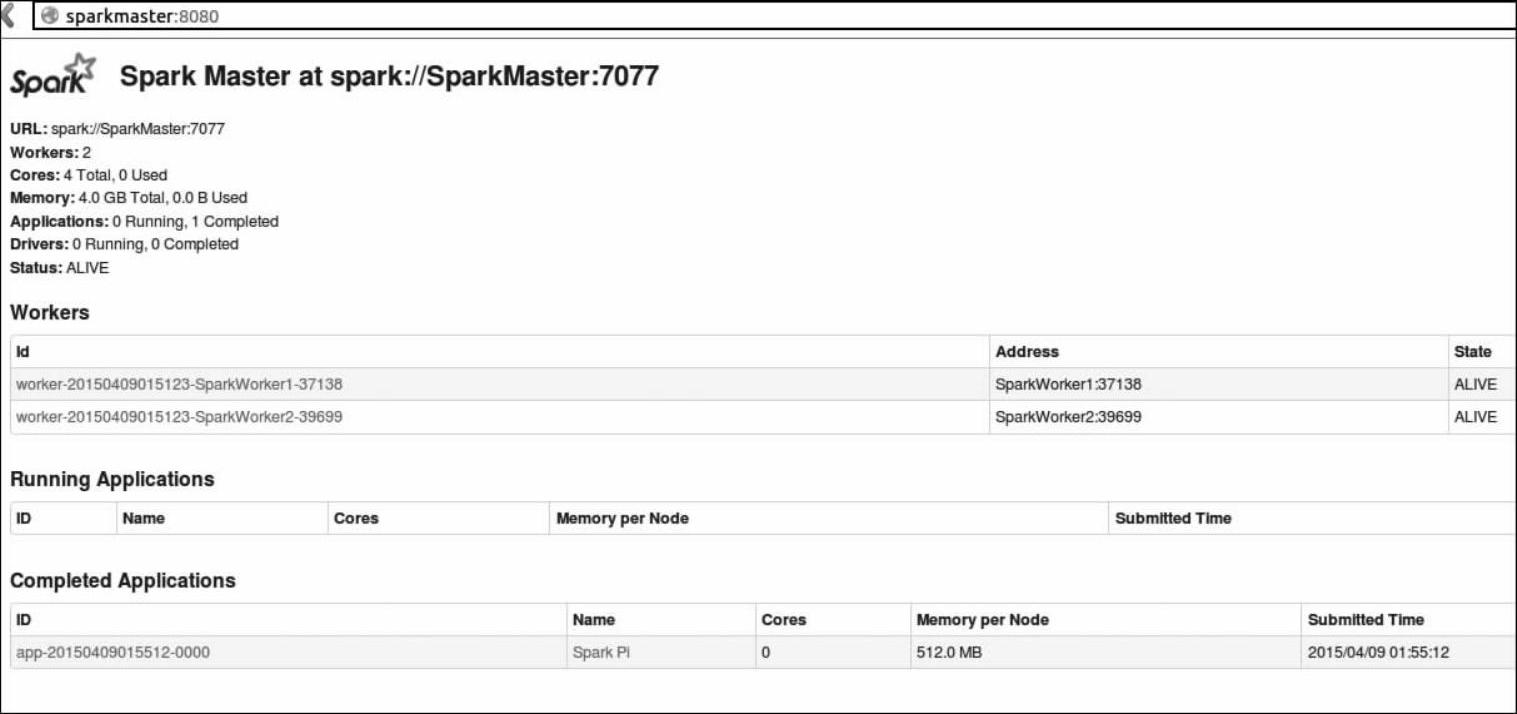
图4-2 作业运行情况
在图4-2中,我们在Completed Application选项下面看到运行了一个Name为SparkPi的作业,并且该集群中一共有两个Worker结点,四颗CPU(Cores)。
(2)在HA方式下用Spark Submit工具提交Spark应用给集群运行。
在使用基于Zookeeper的HA之前我们先简单介绍一下HA和Zookeeper的基本概念。
高可用性(High Availability,简称HA)集群是共同为客户机提供网络资源的一组计算机系统。其中每一台提供服务的计算机称为结点(Node)。当一个结点不可用或者不能处理客户的请求时,该请求会及时转到另外的可用结点来处理,而这些对于客户端是透明的,客户不必关心要使用资源的具体位置,集群系统会自动完成。
而ZooKeeper是一个开放源码的分布式应用程序协调服务,它也是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、名字服务、分布式同步、组服务等。
Zookeeper通过一种和文件系统很像的层级命名空间来让分布式进程互相协同工作。这些命名空间由一系列数据寄存器组成,我们也叫这些数据寄存器为znodes。这些znodes就有点像是文件系统中的文件和文件夹。和文件系统不一样的是,文件系统的文件是存储在存储区上的,而Zookeeper的数据是存储在内存上的。同时,这就意味着Zookeeper有着高吞吐和低延迟。Zookeeper实现了高性能、高可靠性和有序的访问。高性能保证了Zookeeper能应用在大型的分布式系统上;高可靠性保证它不会由于单一结点的故障而造成任何问题;有序的访问能保证客户端可以实现较为复杂的同步操作。
下面我们演示Zookeeper的安装以及通过Zookeeper方式Spark作业的运行以及如何容错。
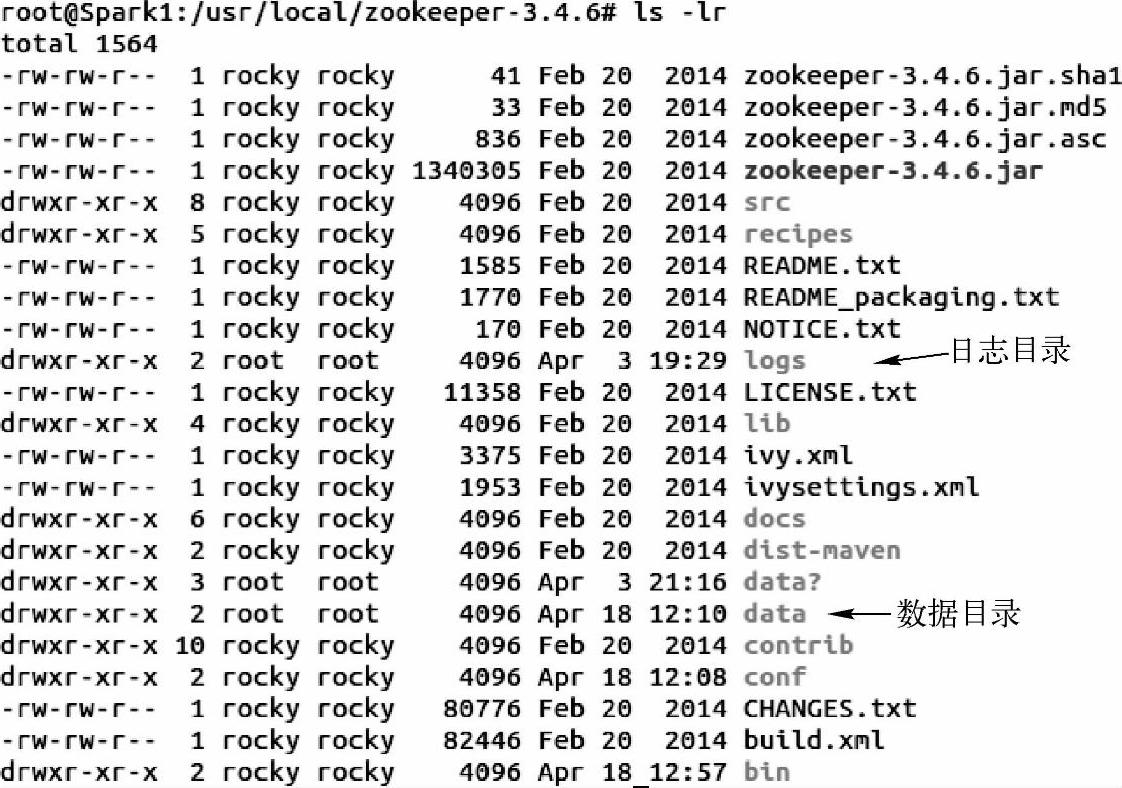
1)安装Zookeeper。下载Zookeeper安装包,并解压到自己创建的目录下进行管理。同时创建两个目录,一个是数据目录,一个日志目录。
2)配置:进到conf目录下,把zoo_sample.cfg复制一份为zoo.cfg(这一步是必须的否则zookeeper不认识zoo_sample.cfg),并添加如下内容:

3)在/usr/local/zookeeper-3.4.6/data目录下创建myid文件,并在里面写1。(https://www.xing528.com)
用vim打开myid文件,查看里面的内容。
4)把Spark1结点上的/usr/local/zookeeper-3.4.6整个目录复制到Spark集群的其他结点(这里我们的集群只包括Spark1和Spark2两个结点)上。
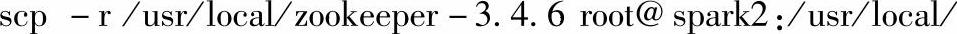
5)登录到Spark2结点上,修改myid文件里的值,将其修改为2。
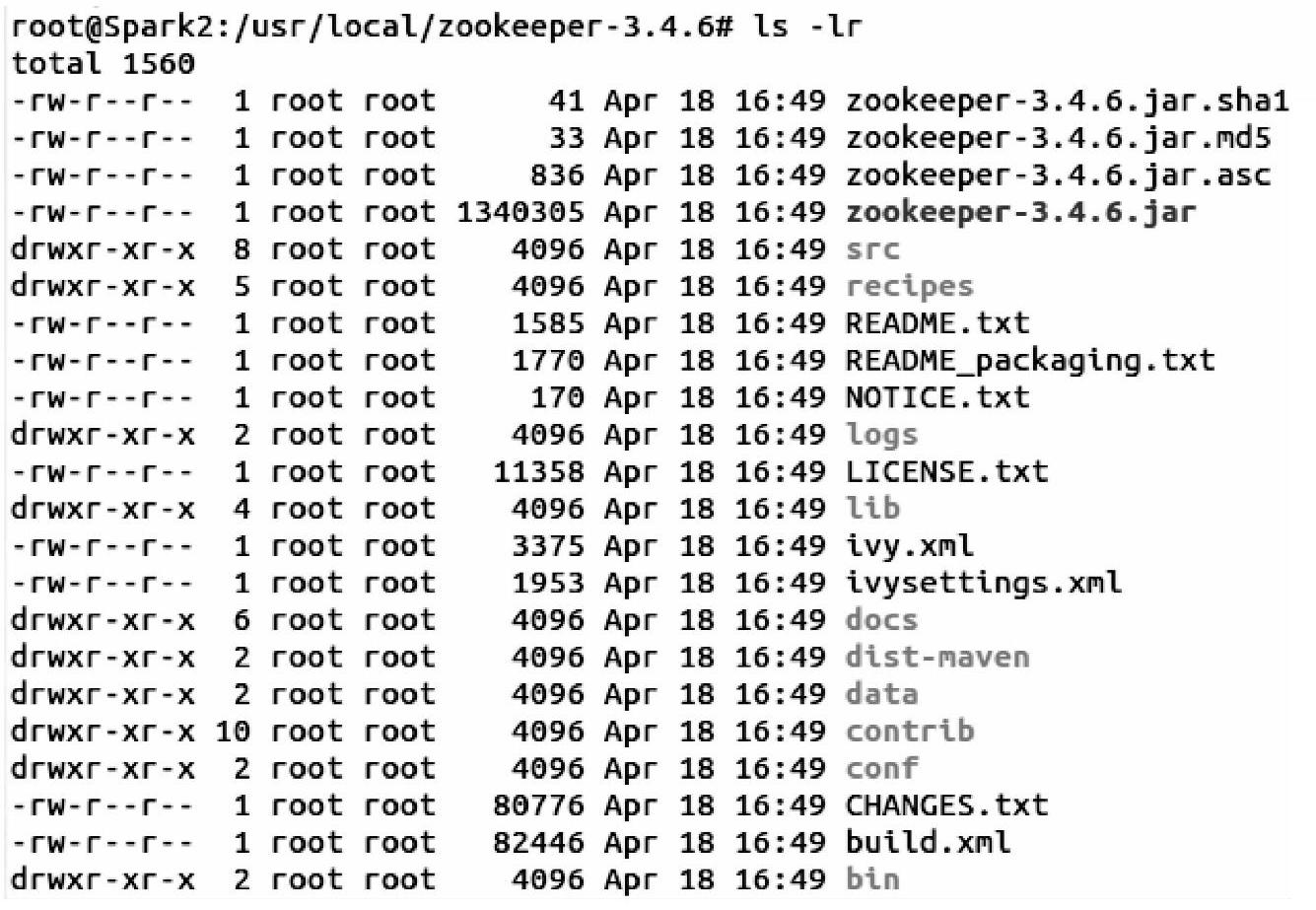
输入以下命令:
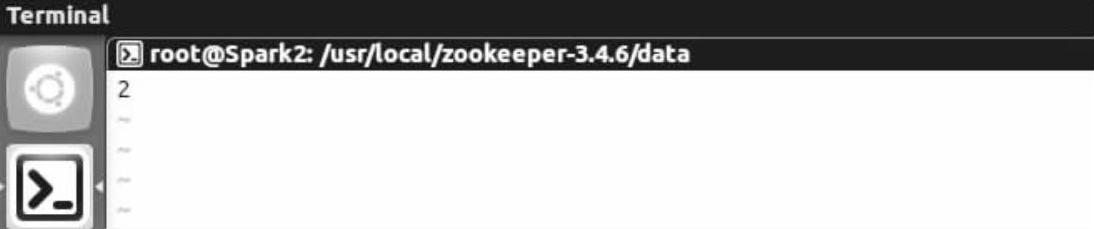
用vim打开myid文件,查看里面的内容。
6)在Spark1,Spark2两个结点上分别启动Zookeeper,查看进程是否开启,其中Quo-rumPeerMain就是Zookeeper的进程。

7)配置Spark的HA。进到Spark的conf目录,在spark-env.sh修改代码如下:
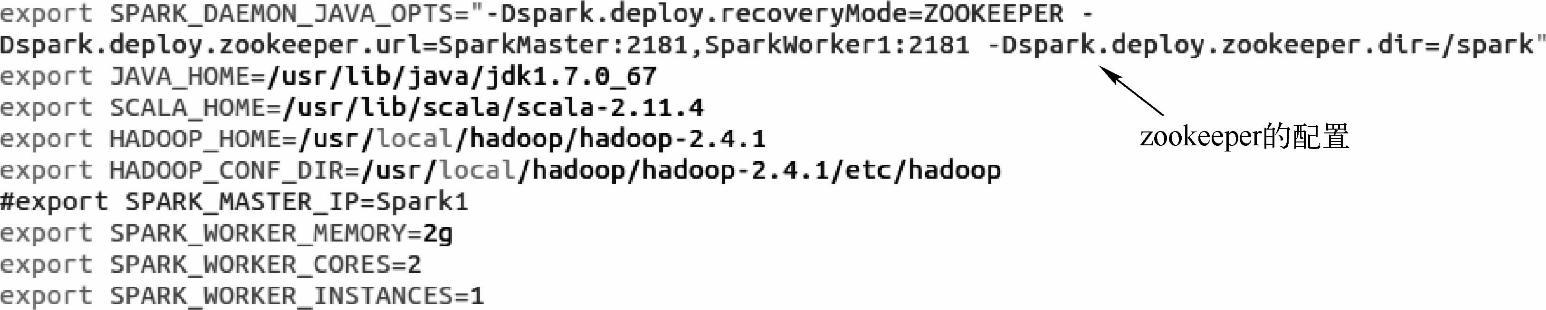
8)使用以下命令把spark-env.sh配置文件分发到其他各个结点上去。
9)使用以下命令在Spark1结点上启动Spark集群。
10)进到Spark2结点的sbin目录下,启动“start-master.sh”命令,当Spark1结点挂掉时,Spark2结点顶替当Spark1。

11)在命令终端用jps命令查看Spark1和Spark2上运行了哪些进程。

12)测试HA是否生效。先查看一下两个结点的运行情况,现在Spark1运行了Master(如图4-3所示),Spark2是待命状态(如图4-4所示)。
在Spark1上把Master服务停掉。

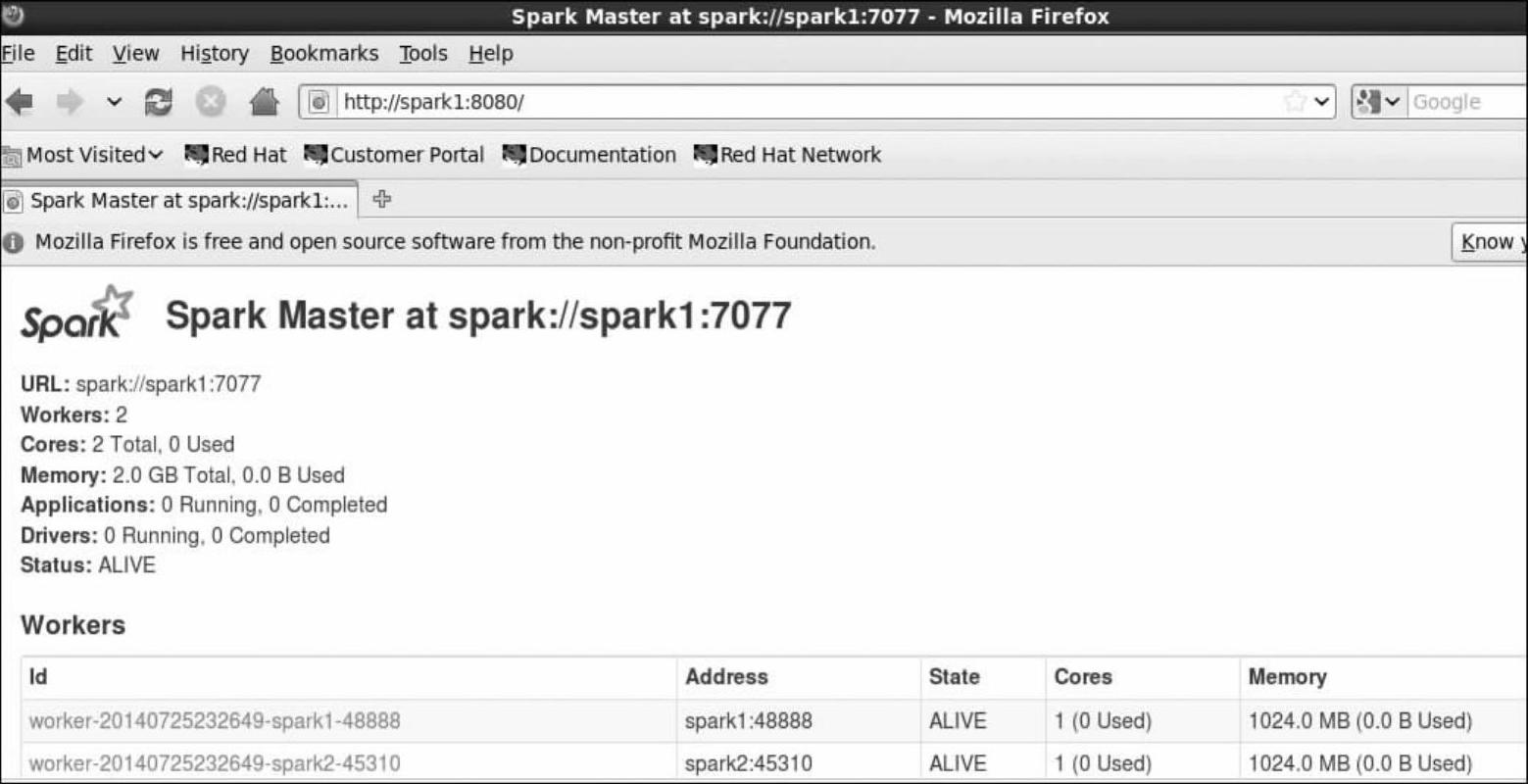
图4-3 Spark1的运行状况
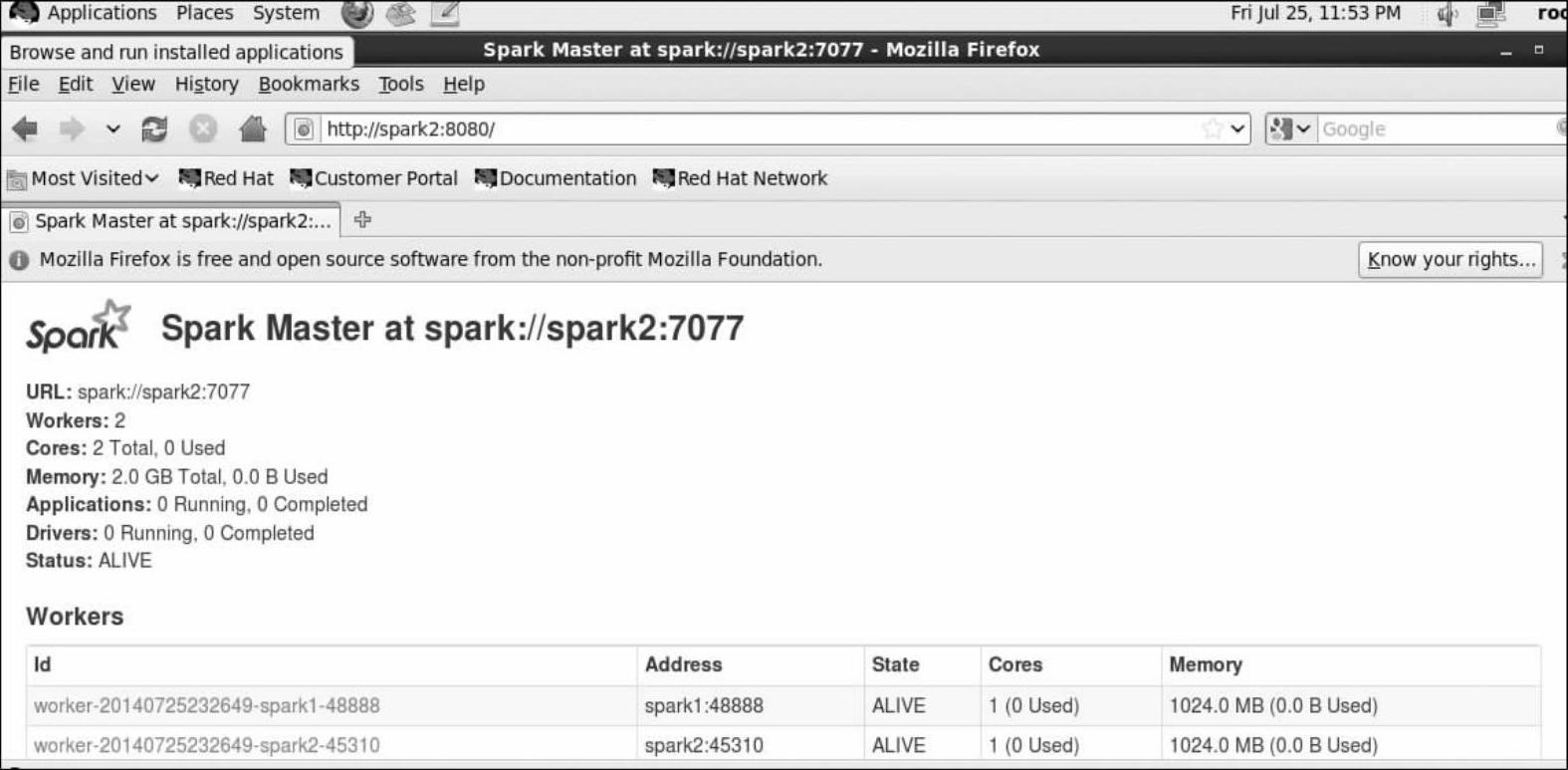
图4-4 Spark2的运行状况
在WebUI上访问Spark1的8080端口,看是否还处于运行状态(active)。从图4-5中可以看到显示“unable to connect”,这表示Spark1结点上的Master已经挂掉。
再用WebUI访问查看Spark2的状态,从图4-6看出,Spark2已经被切换当Master了。
通过以上两个案例,我们分析了在Standalone运行模式下如何向Spark集群提交作业(应用),以及对于Spark集群本身的单点故障问题,如何通过基于Zookeeper的HA进行解决。在讲解了Standalone运行的实际部署问题后,我们下一步趁热打铁结合Spark 1.2的源码来更深层次的分析Standalone模式的内部实现原理。还是那句话,精通原理会使得我们更容易从整体上把握Standalong模式的精髓,在实际生产环境中出现问题时可以轻松地解决。
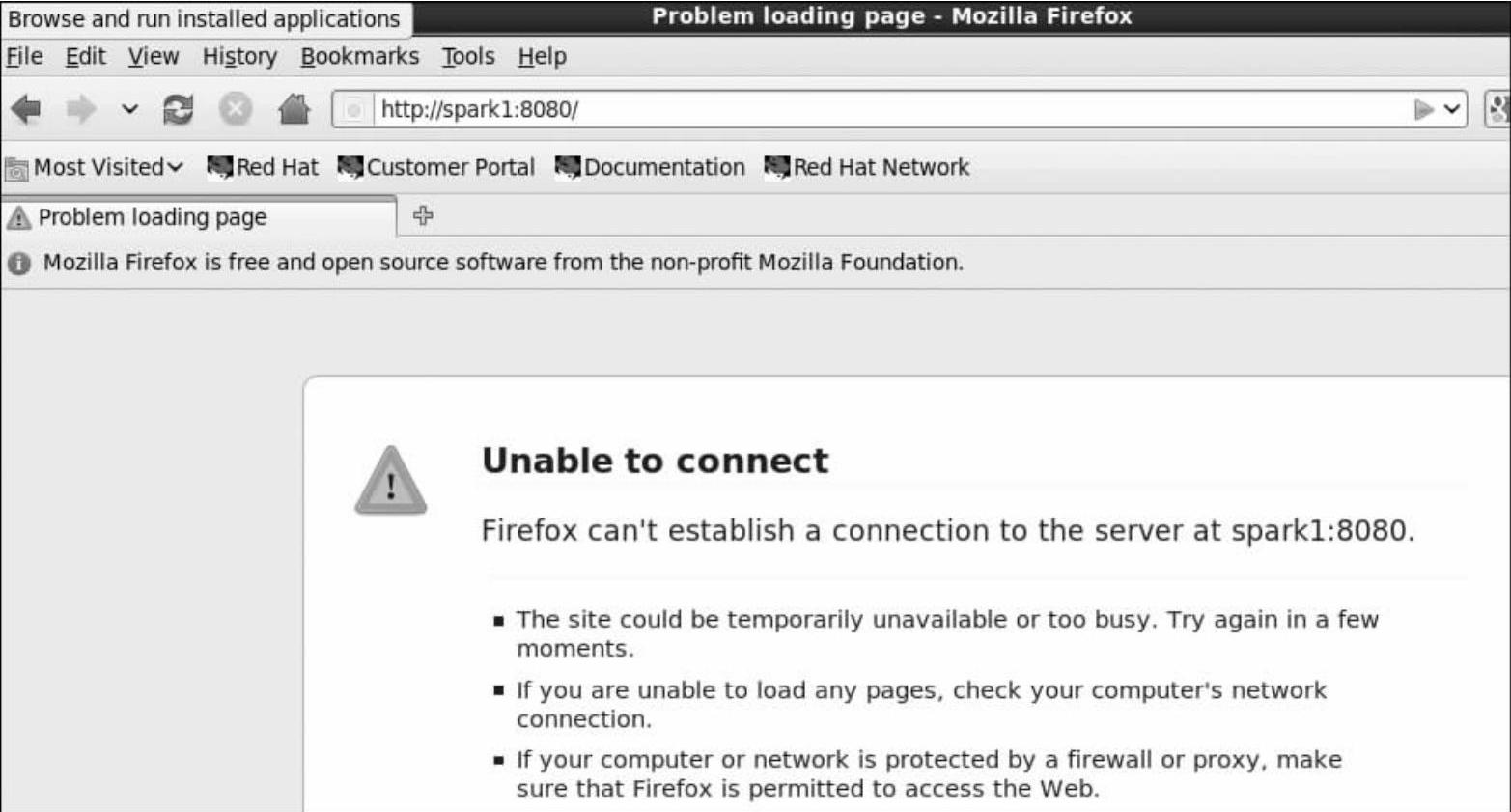
图4-5 Spark1的运行状况
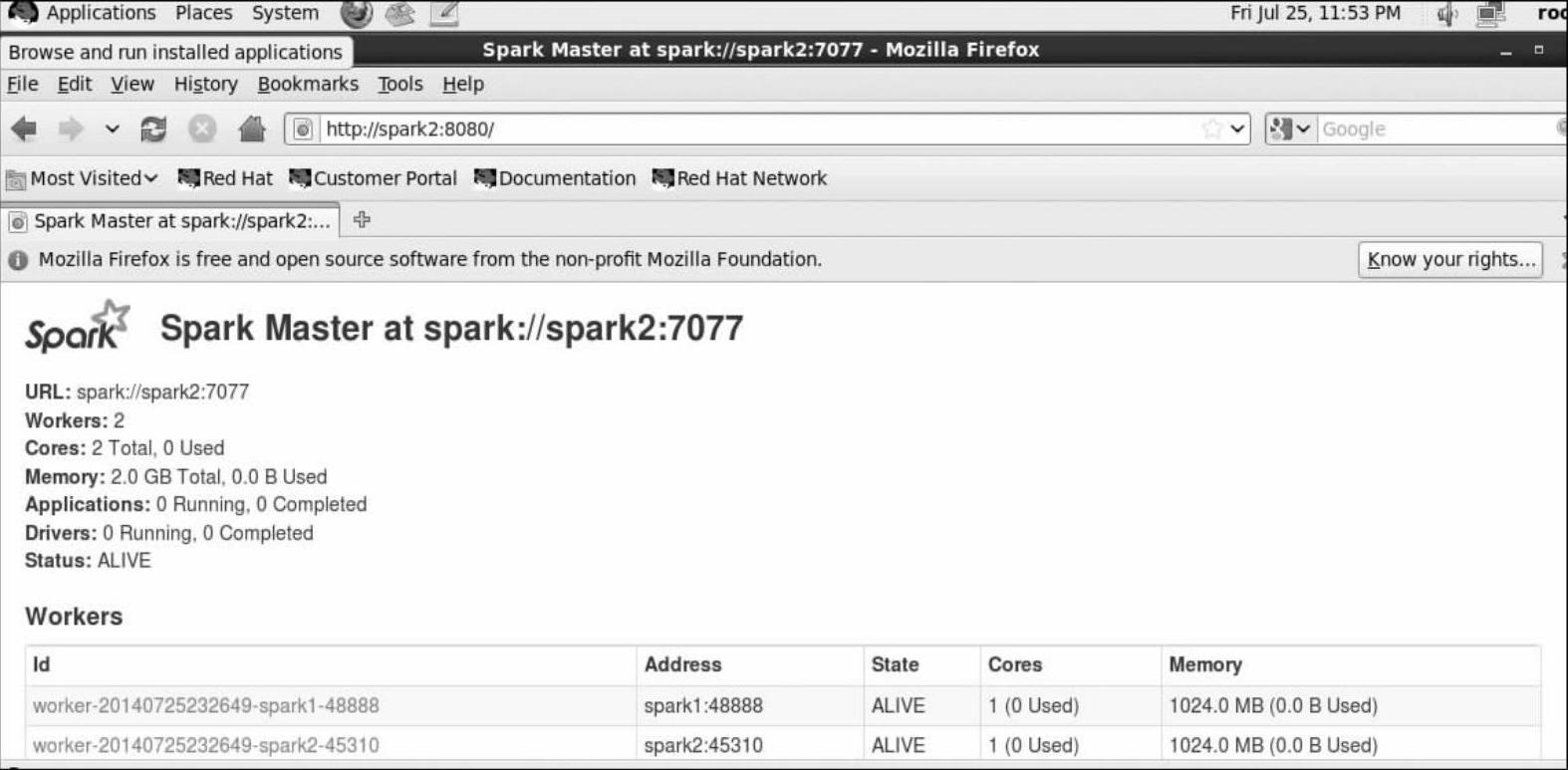
图4-6 Spark的运行状况
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。