



和Yarn-Cluster模式一样,Yarn-Client模式的Spark Application主要也是通过spark-submit脚本提交的。但是Yarn-Client模式的Spark Application的运行不需要通过Client类来封装启动,而是直接通过反射机制调用作业的main函数。下面我们参考图4-12来分析其内部实现原理。
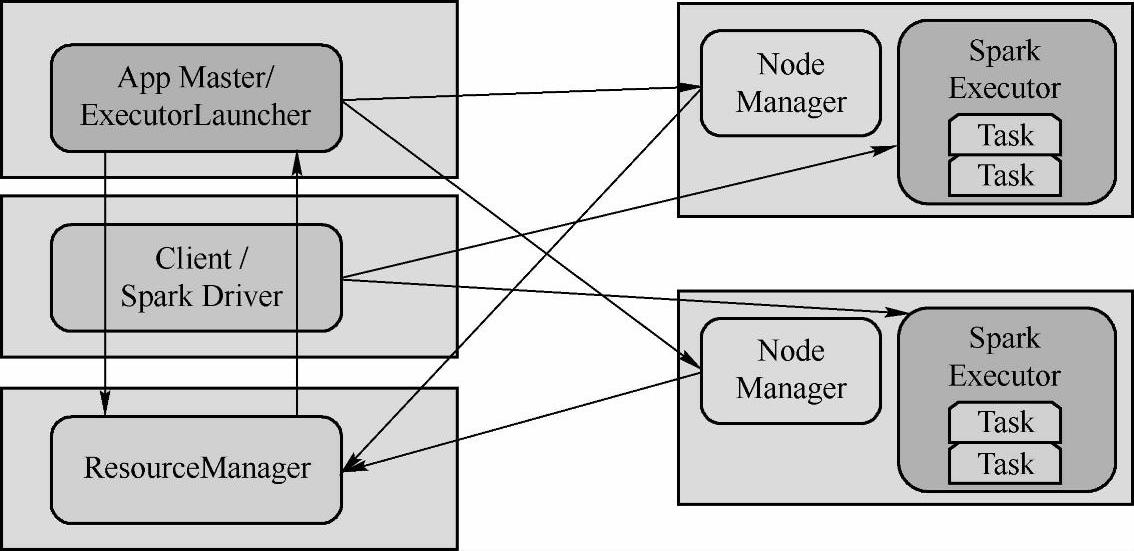
图4-12 yarn-Client模式的工作流程
(1)客户端向Yarn提交Spark Application,在这里通过SparkSubmit类的launch的函数直接调用作业的main方法(通过反射机制实现),如Spark源码的SparkSumit类的cre-ateLaunchEnv()方法中,当部署模式为CLIENT时,会通过反射得到用户编写的Spark应用程序的main方法。

(2)客户端会在本地启动Driver,因为Spark Application的main方法一定都有Driver的SparkContext,会对SparkContext进行初始化。
(3)在SparkContext初始化中将会依次做如下的事情:设置相关的配置、注册MapOut-putTracker、BlockManagerMaster、BlockManager,创建TaskScheduler和dagScheduler;其中比较重要的是创建TaskScheduler和dagScheduler。在创建TaskScheduler的时候会根据我们传进来的master来选择Scheduler和SchedulerBackend。由于我们选择的是yarn-client模式,程序会选择YarnClientClusterScheduler和YarnClientSchedulerBackend,上面两个实例的获取都是通过反射机制实现的,YarnClientSchedulerBackend类是CoarseGrainedSchedulerBackend类的子类,YarnClientClusterScheduler是TaskSchedulerImpl的子类,仅仅重写了TaskScheduler-Impl中的getRackForHost方法。(https://www.xing528.com)
(4)初始化TaskScheduler(这里是YarnClientClusterScheduler)后,将创建dagSchedul-er,然后通过taskScheduler.start()启动TaskScheduler,而在TaskScheduler启动的过程中也会调用SchedulerBackend(这里是YarnClientSchedulerBackend)的start方法。在SchedulerBack-end启动的过程中将会初始化一些参数,封装在ClientArguments中,并将封装好的ClientAr-guments传进Client类中,并调用client.runApp()方法获取Application ID。
(5)client.runApp里面的做是和前面yarn-cluster模式中进行操作那节类似,不同的是在里面启动是org.apache.spark.deploy.yarn.ExecutorLauncher(yarn-cluster模式启动的是ApplicationMaster),它只负责启动Executor和客户端的Driver进行通信。
(6)在ExecutorLauncher里面会向ApplicationMaster注册该Application。注册完之后将会等待driver的启动,当driver启动完之后,会创建一个MonitorActor对象用于和CoarseG-rainedSchedulerBackend进行通信。
(7)ExecutorLauncher通过YarnAllocationHandle向ResourceManager申请资源来运行Task,ExecutorLauncher接受到ResourceManager分配的Container资源后,会启动CoarseG-rainedExecutorBackend,然后CoarseGrainedExecutorBackend会向客户端的Driver注册并申请Task。
(8)最后Task会在Executor中运行,CoarseGrainedExecutorBackend通过Akka通信框架跟CoarseGrainedSchedulerBackend进行Task运行状况的通信,直到Job运行完成。
(9)在Application运行的时候,YarnClientSchedulerBackend会每隔1 s会获取到Applica-tion的运行状况,并打印出相应的运行信息,当Application的状态是FINISHED、FAILED和KILLED中的一种,那么程序将退出等待。
(10)最后有个线程会再次确认Application的状态,当Application的状态是FINISHED FAILED和KILLED中的一种,程序就运行完成,并停止SparkContext。整个过程就结束了。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。