



在这里我们通过一个和Spark GraphX官方类似的属性图来进行图的操作的演示(如图8-10),具体的操作我们会在spark-shell环境下进行演示。图8-10是一个由6个顶点和8条边组成的社交关系的图,图中每个顶点的属性包括一个人的姓名和年龄,每条边有一个属性值,我们可以假设这个属性值表示的是源顶点向目的顶点追求的次数。
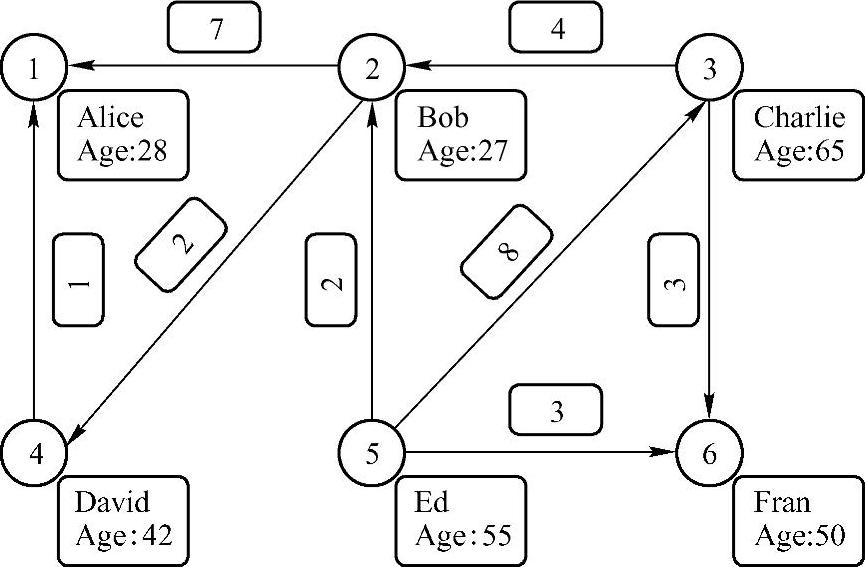
图8-10 Spark GraphX属性图
下面我们在一个SimpleGraphX object(对象)中完整地列出了我们进行图的操作时需要的代码以及代码所表示的含义,这些代码是我们在IntelliJ IDEA工具中编写的,考虑到演示效果的因素,我们会截取其中的关键代码然后在spark-shell中进行图操作的演示。






以上代码可以直接通过IntelliJ IDEA工具进行操作实践。
1.图的构建
(1)在进行图的构建之前,我们首先要引入一些图操作中用到的类,比如org.apache. spark.graphx包下的Graph等。在spark-shell的命令终端输入以下内容:
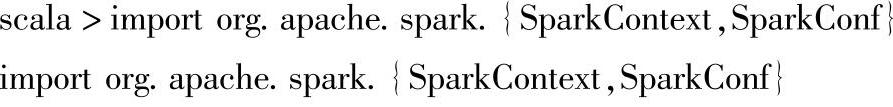

(2)设置顶点。注意,顶点是用元组定义的Array,顶点的数据类型是VD:(String,Int)。可以看到最终产生了一个类型为Array[(Long,(String,Int))]的变量vertexArray,其中Long类型指的是顶点ID,(String,Int)指的是顶点属性的类型。

(3)设置边。注意,边是用一组Edge对象组成的Array,边的数据类型是边的数据类型ED:Int。可以看到在spark-shell交互界面中输入设置边的代码后产生了一个Array[org.apache.spark.graphx.Edge[Int]]类型的edgeArray变量。

(4)使用SparkContext对象的parallelize()方法,把关于顶点的数组vertexArray转换成一个RDD[(Long,(String,Int))]类型的RDD。
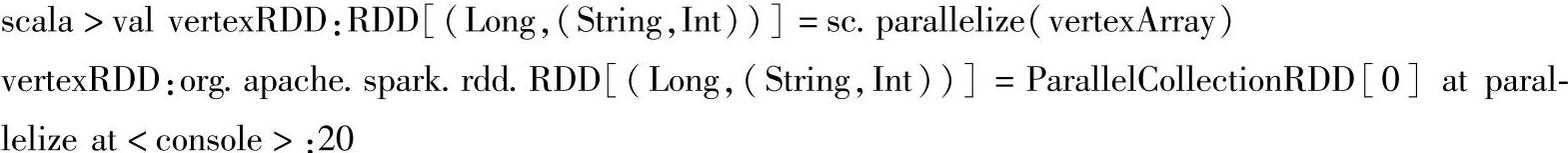
(5)同样使用SparkContext对象的parallelize()方法,把关于边的数组edgeArray转换成一个org.apache.spark.rdd.RDD[org.apache.spark.graphx.Edge[Int]]类型的RDD。

(6)下面我们就可以使用Graph类的apply()方法构建一个图,其中图的顶点RDD就是vertexRDD,边RDD就是edgeRDD。

这样,经过以上6个步骤,我们就构建出了一个Graph对象,在下面几个小节中,对图的数据的操作都是依赖于这里我们构建的这个图。
2.图的属性操作
(1)找出图中年龄大于30的顶点。首先使用graph.vertices找到我们构建的图中的顶点vertices(VertexRDD)。然后使用filter{case(id,(name,age))=>age>30}过滤出年龄大于30的人员,因为顶点是用“(顶点的ID号,(属性的姓名,属性的年龄)”来表示的,如(1L,("Alice",28)),所以这里使用“case(id,(name,age))”来进行匹配“(顶点的ID号,(属性的姓名,属性的年龄))”。接着使用RDD的collect()方法将过滤的结果进行收集,最后使用foreach输出收集到的结果。最后我们可以看到年龄大于30的人有David、Fran、Charlie和Ed。

(2)对于从图的顶点中找出年龄大于30的人,我们除了在代码中使用Scala语言的模式匹配外,还可以使用Scala的元组特性进行操作,如以下的代码所示,最终的查找结果跟上一个查找结果相同。

(3)边的操作:找出图中属性大于5的边。首先使用graph.edges产生一个边RDD(EdgeRDD),再调用EdgeRDD的filter()方法来过滤出边属性大于5的边,然后使用RDD的collect()方法收集结果为一个单机的数组,并调用数组的foreach()把结果输出在spark-shell控制台。最终的输出结果显示只有顶点2到顶点1的边和顶点5到顶点3的边值大于5。

(4)triplets(边三元组)操作:列出所有的tripltes,其中每个边三元组包括源顶点ID和属性,目的顶点ID和属性以及边的属性。格式如:((srcId,srcAttr),(dstId,dstAttr),at-tr)。首先调用graph.triplets产生一个RDD[EdgeTriplet[VD,ED]]类型的RDD,然后调用这个RDD的collect()方法生成一个单机的数组,最后使用for循环遍历这个数组中的值并使用println()方法以“triplet.srcAttr._1}likes${triplet.dstAttr._1”的格式把结果打印到控制台。


(5)同样是对triplets(边三元组)操作:列出边属性>5的tripltes。这里的操作跟上一个对边三元组的操作类似,唯一不同的是在调用graph.triplets后会先对RDD[EdgeTriplet[VD,ED]]中的数据进行过滤,只保留边属性大于5的边三元组,最后还是输出结果到控制台上。我们可以看到过滤后满足条件的边三元组只剩下两个。


(6)Degrees操作:找出图中最大的出度、入度、度数。首先要预定义一个max()函数,它负责从任意两个值中选出值大的那一个。接下来通过调用graph.outDegrees.reduce(max)得出出度最大的顶点ID和它的出度数,调用graph.inDegrees.reduce(max)得出入度最大的顶点ID和它的入度数,调用graph.degrees.reduce(max)得出度数(包括出入度)最大的顶点ID和它的度数。从输入结果中我们看到出度最大的是顶点ID为5出度为3的顶点,入度最大的是顶点ID为2出度为2的顶点,出入度最大的是顶点ID为2出入度为4的顶点。


3.转换操作(Property Operations)
(1)顶点的转换操作:每一个顶点属性中的age进行age+10。直接调用graph.map-Vertices()方法并结合Scala的模式匹配对图中顶点的age属性进行转换操作,然后把转换操作后产生的新图中的顶点数据进行收集并输出到spark-shell控制台上。从输出结果中可以看出原来David的年龄是42岁,而转化后David的年龄由于增加了10岁变成了52岁,其他的人的年龄同理都增加了10岁。
 (https://www.xing528.com)
(https://www.xing528.com)

(2)边的转换操作:边的属性×2。调用graph.mapEdges()把每条边的属性值都乘以2,然后调用collect()方法收集每条边的数据并以“${e.srcId}to${e.dstId}att${e.attr}”的格式输出到控制台。从输出结果中可以看出原来顶点2到顶点1的属性值是7,而转化后由于乘以2变成了14,其他的边同理都变成了原来的2倍。


4.结构操作(Structural Operations)
(1)在这里的结构操作中,我们只演示根据条件产生一个图的子图的操作。首先我们调用graph.subgraph()并在subgraph()方法内部提供了一个函数来判断顶点的属性age>30,然后根据过滤后的结果产出一个新的子图subGraph。
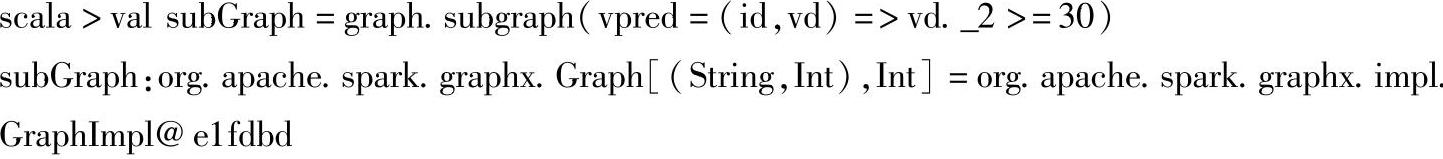
(2)调用产出的子图subGraph.vertices.collect()方法收集这个新图的顶点数据,然后调用数组的foreach()方法把结果输出到spark-shell控制台。从输出结果中可以看到顶点的数量原来的6个减少到4个。


(3)同样我们可以求出子图subGraph所有边,subGraph.edges.collect.foreach(e=>println(s"${e.srcId}to${e.dstId}att${e.attr}"))这行代码会先得出子图subGraph的边RDD,然后调用边RDD的collect收集数据,最终使用foreach()方法以“${e.srcId}to${e-.dstId}att${e.attr}”的格式把结果输出到spark-shell控制台上。从输出结果中我们发现边的数量同样减少了,由原来的8条边减为3条边。


5.连接操作(Join Operations)
(1)首先定义一个case class User,用来作为后面生成的新图的顶点属性类型。
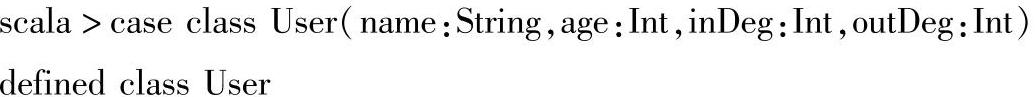
(2)创建一个新图initialUserGraph,顶点VD的数据类型为User,并通过graph的map-Vertices()方法做类型的转换操作。

(3)initialUserGraph与分别它的inDegrees(入度)、outDegrees(出度)进行outerJoin-Vertices操作(连接操作),并修改initialUserGraph中顶点属性的inDeg值、outDeg值,最后会生成一个连接操作后的新图userGraph。

(4)通过userGraph.vertices.collect.foreach(v=>println(s"${v._2.name}inDeg:${v._ 2.inDeg}这行代码我们可以在spark-shell控制台以“${v._2.name}inDeg:${v._2.inDeg outDeg:${v._2.outDeg}”的格式输出新生成的连接图的顶点属性。

(5)对于新生成的连通图userGraph,调用VertexRDD的filter()方法,过滤出入度(u.inDeg)和出度(u.outDeg)相同的顶点,然后把满足条件的顶点属性name输出到spark-shell控制台。从输出结果中看到满足条件的name只有David和Bob。

6.聚合操作(MapReduceTriplets、Collecting Neighbors)
(1)找出年纪最大的追求者。在做聚合操作时,我们会用到前面坐连接操作时生成的一个连接图userGraph。首先我们会调用userGraph.mapReduceTriplets()方法来生成一个Ver-texRDD对象,在mapReduceTriplets()方法有两个函数,一个负责将将源顶点的属性发送给目的顶点,一个是在目的顶点对收到的属性消息进行判断,最后得到的是edge.srcAttr.age 值最大的顶点属性。当然mapReduceTriplets()方法返回的VertexRDD中包含的是一组顶点,其中每个顶点包括顶点ID和顶点属性(edge.srcAttr.name,edge.srcAttr.age)。

(2)使用userGraph.vertices生成一个VertexRDD对象,然后使用这个对象和oldestFol-lower做左连接操作。在做左连接操作的过程中,会结合Scala语言的模式匹配对optOldest-Follower进行匹配,如果它满足case Some((name,age)),表明连接后的两个VertexRDD中存在oldestFollower(VertexRDD)中的顶点属性值,这时就会选择格式为s"${name}is the ol-dest follower of${user.name}."的值作为新生成的连接图的顶点属性值,否则顶点属性值为s"${user.name}does not have any followers."。最后还是把新生成的顶点属性值打印到spark-shell控制台上。从输出结果中我们看到“Bob is the oldest follower of David”这样的语句,它指的就是Bob所在的顶点有指向David所在的顶点的边,且边的属性值是所有指向David所在的顶点中最大的。

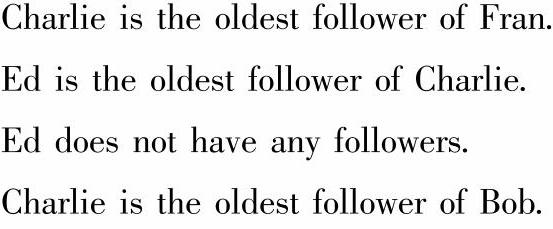
(3)找出追求者的平均年纪。首先也是通过调用userGraph.mapReduceTriplets()方法生成一个VertexRDD对象,其中VertexRDD对象是由一组顶点组成,每个顶点还是包括顶点ID和顶点属性(追求者的数量,总年龄),然后调用这个VertexRDD的mapValues()方法,对顶点属性进行转换,生成一个顶点属性为追求者的平均年纪的VertexRDD对象。

(4)最后还是要调用userGraph.vertices.leftJoin()方法使得userGraph的顶点和aver-ageAge进行左连接操作生成新的顶点属性值,然后把顶点属性值在spark-shell控制台打印出来。从输出结果中,我们可以看到每个顶点的追求者的平均年龄,而如果一个顶点没有追求者(指的是该顶点没有入度),如Ed所在的顶点,那么在左连接后产生的新图中,它的顶点属性就是“Ed does not have any followers.”。

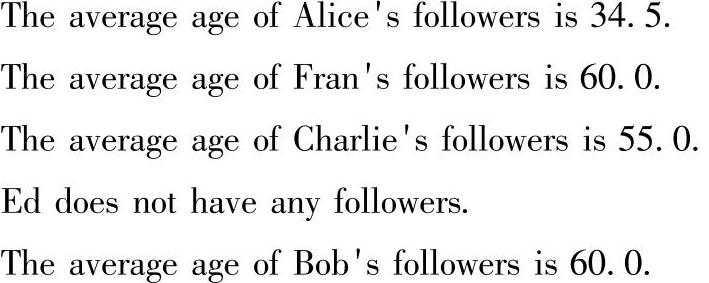
(5)找出顶点ID为5的顶点到图中各顶点的最短距离。首先我们定义一个顶点ID为5的源点,然后在调用graph.mapVertices()方法时会借助这个源点的ID是否与图中的某些顶点的ID相等来生成新的顶点属性,进而生成一个新的图initialGraph。

(6)调用initialGraph.pregel()方法来完成顶点ID为的顶点到各个顶点的最短距离的计算,其中参数Double.PositiveInfinity是一个初始化消息,参数(id,dist,newDist)=>math.min(dist,newDist)是一个顶点更新函数,参数triplet=>{……}是生成发送消息的函数,参数(a,b)=>math.min(a,b)是每个目的顶点上的聚合函数。最终会产生一个新的图sssp。


(7)最终调用println(sssp.vertices.collect.mkString("\n"))这行代码把图sssp的顶点收集后打印到spark-shell控制台上。在输出结果中可以看到顶点5到顶点4的最短距离是4,顶点5到顶点1的最短距离是5,大家可以把计算结果跟我们提供的Spark GraphX属性图的数据进行比较来验证我们是否求出了顶点5到各个顶点的最短距离。

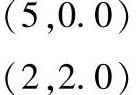
至此,我们已经结合Spark官方提供的Spark GraphX属性图进行了一系列的图的操作。在这里如果对图的操作方法的含义不太了解,可以翻看前面讲图的操作方法的定义部分。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。