



在Saprk Streaming中有一些基本概念,对基本概念的掌握会提高对Spark Streaming的理解,并将更容易地使用Spark Streaming。
1.链接
类似于Apache Spark,Spark Streaming也可以利用Maven仓库管理依赖。编写Spark Streaming程序的时候,需要将【例4-11】,【例4-12】所示的代码片段依赖信息添加到SBT或者Maven工程文件中。
【例4-11】Maven依赖信息。
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.10</artifactId>
<version>1.4.1</version>
</dependency>
【例4-12】SBT依赖信息。
libraryDependencies+="org.apache.spark"%"spark-streaming_2.10"%"1.4.1"
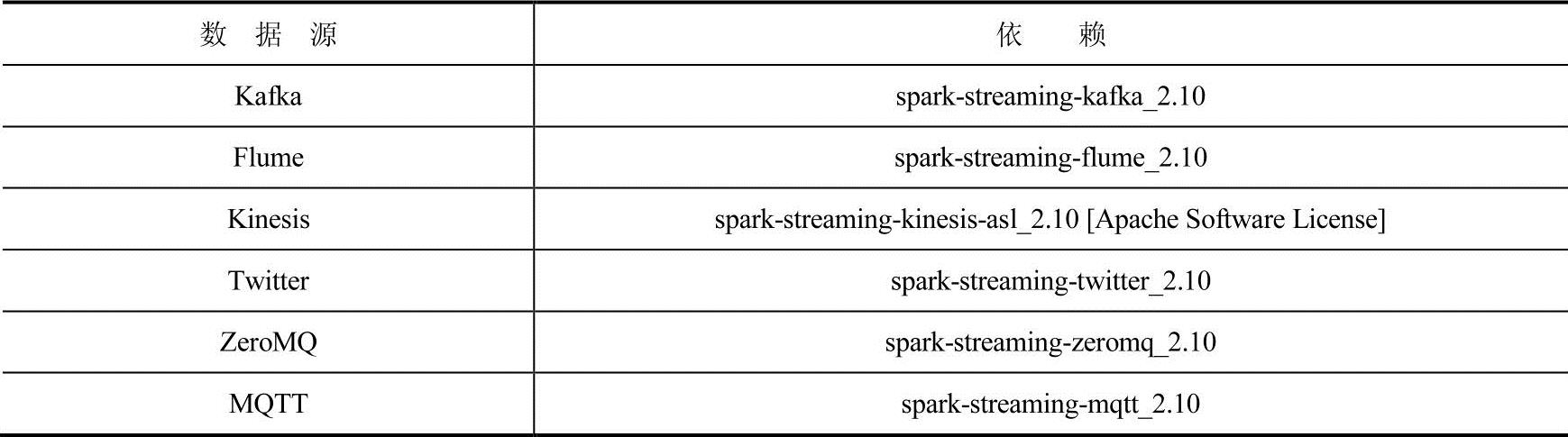
若需要从Kafka、Flume和Kinesis,这些Spark Streaming核心未提供相应API处理接口的数据源中读取数据,需要将相应的包添加到依赖中,包格式为spark-streaming-xyz-2.10。一些常用的依赖如表4-7所示。
表4-7 常用数据源对应依赖表
程序的最开始,需要创建一个StreamingContext对象作为Spark Streaming所有流数据操作的入口,在【例4-13】中,SparkConf的设置与Apache Spark一致,创建Streaming Context时候需要传入SparkConf对象,并设置批处理间隔时长。也可以利用已有的SparkContext对象创建StreamingContext对象。
【例4-13】创建StreamingContext对象。
import org.apache.spark.streaming._
val sc=... //已经存在的SparkContext
val ssc=new StreamingContext(sc,Seconds(1))
当一个StreamingContext对象创建完毕之后,流处理的流程如下。
1)定义输入源。
2)指定流计算所需要的指令。
3)调用StreamingContext的start方法开始接受和处理数据。
4)处理过程会持续直到SteamingContext的stop方法被调用。
此外还有如下一些个别需要注意的地方。
1)一旦SparkContext启动,就不能有新的DStream被配置或者添加到SparkContext中。2)一旦SparkContext停止,就不能重新启动。
3)一个JVM内同一时间只能有一个StreamingContext处于活跃状态。
4)若调用StreamingContext对象的stop方法,则SparkContext对象也会失效。如果只想关闭StreamingContext,则设置stop方法的可选参数为false。
5)一个SparkContext对象可用于创建多个StreamingContext对象,前提是上一个StreamingContext对象已经被关闭,并且SparkContext对象没有被关闭。
2.离散流(DStreams)
离散流DStream表示连续的数据流,在Spark Streaming内部,离散流由一系列连续的RDD组成,每个RDD都包含某个确定时间间隔的数据,如图4-4所示。
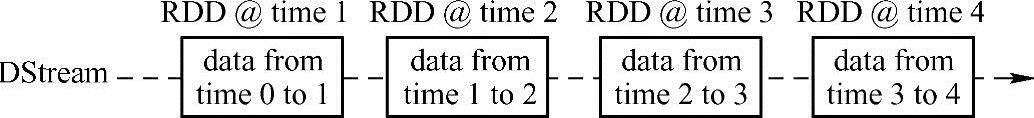
图4-4 离散流由多个连续的RDD组成
离散流的任何操作都转换为对离散流内部RDD的操作。flatMap转换操作会被应用于lines内部的所有RDD上,过程如图4-5所示。
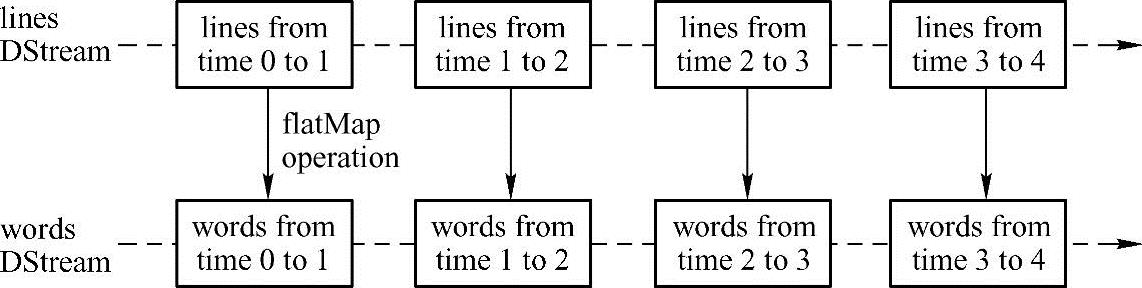
图4-5 flatMap操作被应用到每一个RDD之上
3.离散流(DStreams)输入操作
每个离散流的输入流都与一个Receiver对象相关联,Receiver负责从源中获取数据,并将数据写入内存中等待处理。
Spark Streaming拥有如下两类输入源。
● 基本源:StreamingContext中提供API接口,可直接读取的源,例如文件系统、套接字、Akka中的Actor等。
● 高级源:StreamingContext中未提供直接的API接口来读取数据的源,例如Kafka、
Flume、Kinesis等。
Spark Streaming允许实例化多个DStream对象,从而创建多个Receiver来同时接收多个数据流。由于Receiver需要在后台长期运行,因此会占用工作节点的一个核,这就需要保证已经为Spark Streaming应用程序分配足够多的CPU核心(如果是在本地运行,则此处是线程 数)。
还有以下几点需要注意。
1)如果分配给应用程序的CPU核心数目少于或者等于Receiver的数目,那么系统只能接收而不能处理数据。
2)当运行在本地时,如果设置主节点的URL地址为local的话,只会有一个本地CPU核运行任务,这会导致Receiver一直占用一个核心来接收数据,从而没有多余的核心来处理数据。
在入门实例中已经展示了从TCP套接字获取数据流的方法,此外,Spark Streaming还支持将文件系统和Akka actors作为输入源并用于创建DStream。
若将文件系统作为输入源,则得到的数据流为文件流(File Streams)。Spark Streaming可以从任何与HDFS API兼容的文件系统中读取数据,创建办法有如下3种。
● streamingContext.fileStream[KeyClass,ValueClass,InputFormatClass](dataDirectory)
● streamingContext.fileStream[KeyClass,ValueClass,InputFormatClass](dataDirectory)
● streamingContext.textFileStream(dataDirectory)
Spark Stream会一直监控dataDirectory目录,并且处理该目录下生成的任何文件,但需要注意以下几点。
1)所有文件都必须具有相同的数据格式。
2)dataDirectory目录下的所有文件都是通过移动或者重命名的方式被创建,移动和重命名的操作具备原子性。
3)一旦文件进入目录就不能发生改变,如果有新数据附加到已有文件后面,这部分新内容不会被程序读取。
对于比较简单的文本文件,建议使用StreamingContext的textFileSystem(dataDirectory)方法创建DStream,这种方法不需要运行Receiver,因此不需要分配内核。
若将Akka的actor作为数据源,则需要调用StreamingContext的actorSystem(actorProps, actorname)方法;若为了测试Spark Streaming应用程序,也可以将RDD队列作为数据流,通过调用StreamingContext的queueStream(queueOfRDDs)方法来创建基于RDD队列的DStream。
对于高级源,从源头创建DStream需要导入相应的第三方包。以导入Twitter的流数据为例,需要按照如下步骤。
1)依赖关联:添加spark-streaming-twitter_2.10到SBT或者Maven工程的依赖中。
2)程序编写:导入TwitterUtils类,调用TwitterUtils的createStream方法来创建DStream。
3)程序部署:将编写的程序以及其所有依赖打包成Jar包,部署程序。
4.离散流(DStream)转换操作
和RDD类似,离散流支持许多在RDD中能用的转换操作,一些常用的转换操作如表4-8所示。
表4-8 DStream常用转换操作
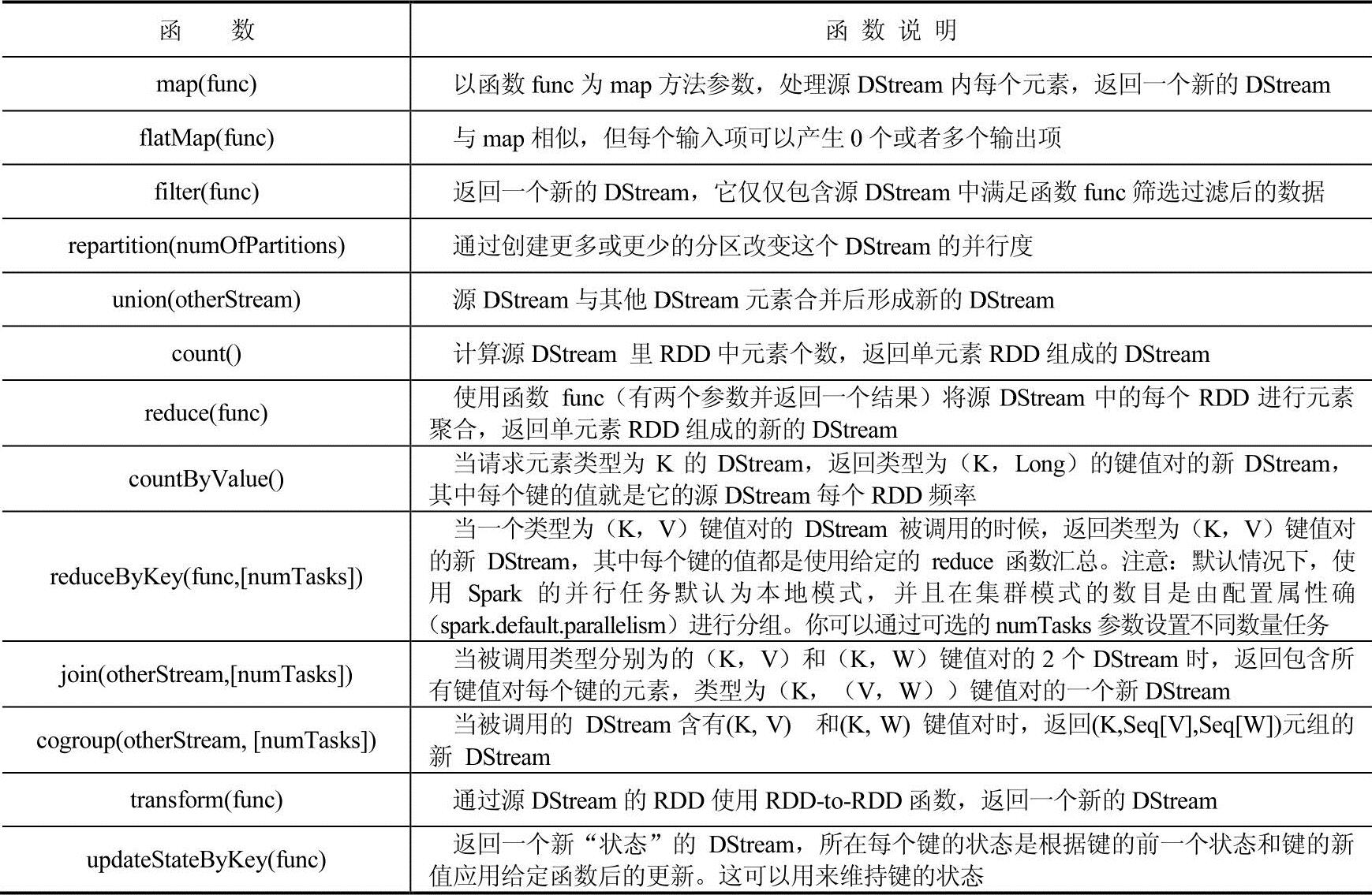
表4-8中最后的几个操作相对比较重要,在此对其进行具体解释。
(1)UpdateStateByKey操作(https://www.xing528.com)
updateStateByKey操作可以让开发者保持任意想要的状态,同时不断有新的信息进行更新。使用此功能必须做到以下两点。
1)定义状态——状态可以是任意的数据类型。
2)定义状态更新函数——用一个函数指定如何使用先前的状态和从输入流中的新值来更新状态。
例如:

这些代码将应用到包含单词的DStream,即在前面【例4-10】中出现的包含(word,1)的DStream对。
val runningCounts=pairs.updateStateByKey[Int](updateFunction_)
每一个单词都将调用更新函数,newValues具有序列1(从(word,1)键值对)且runningCount表示以前的计数。使用updateStateByKey需要注意先将checkpoint目录配置好,这将在checkpoint部分详细讲述。
(2)Transform操作
该转换操作允许在DStream上进行任意RDD到RDD的操作。它可以被应用于未在DStream API中开放的RDD操作,例如,在每批次的数据流与另一数据集的join操作不直接开放在DStream的API中,但是,可以轻松地使用tranform操作来做到这一点。例如如下代码中,通过连接预先计算的垃圾邮件信息的输入数据流,然后基于此做实时数据清理的筛选。

事实上,也可以在转换方法中使用机器学习和图形计算的算法。
(3)Window操作
最后,Spark Streaming还提供了窗口的计算,它允许通过滑动窗口对数据进行转换。图4-6阐述了这种滑动窗口的实现原理。
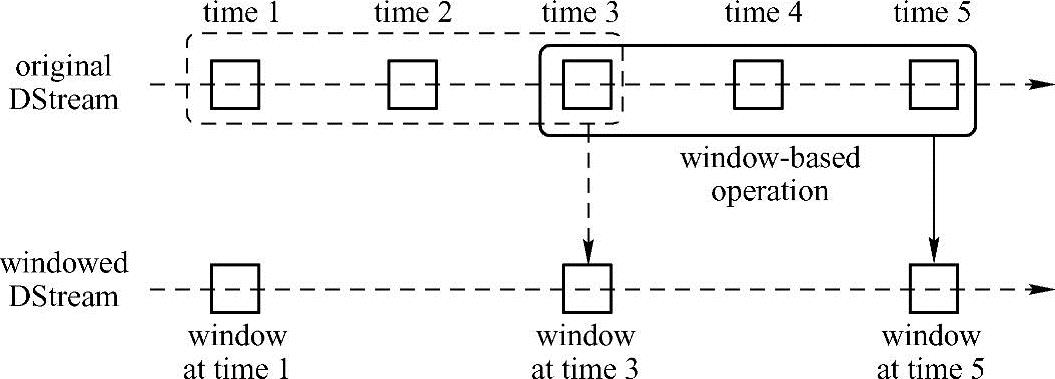
图4-6 滑动窗口示意图
如图4-6所示,窗口源DStream中滑动,合并和操作落入窗内的RDDs,产生窗口化的RDDs。在该图中可见,程序在3个时间单元的数据上进行窗口操作,并且每两个时间单元滑动一次。这表明窗口操作需要指定两个参数。
● window length-窗口持续时间。
● sliding interval-窗口操作之间的间隔。
这两个参数必须是源DStream的批次间隔的倍数。
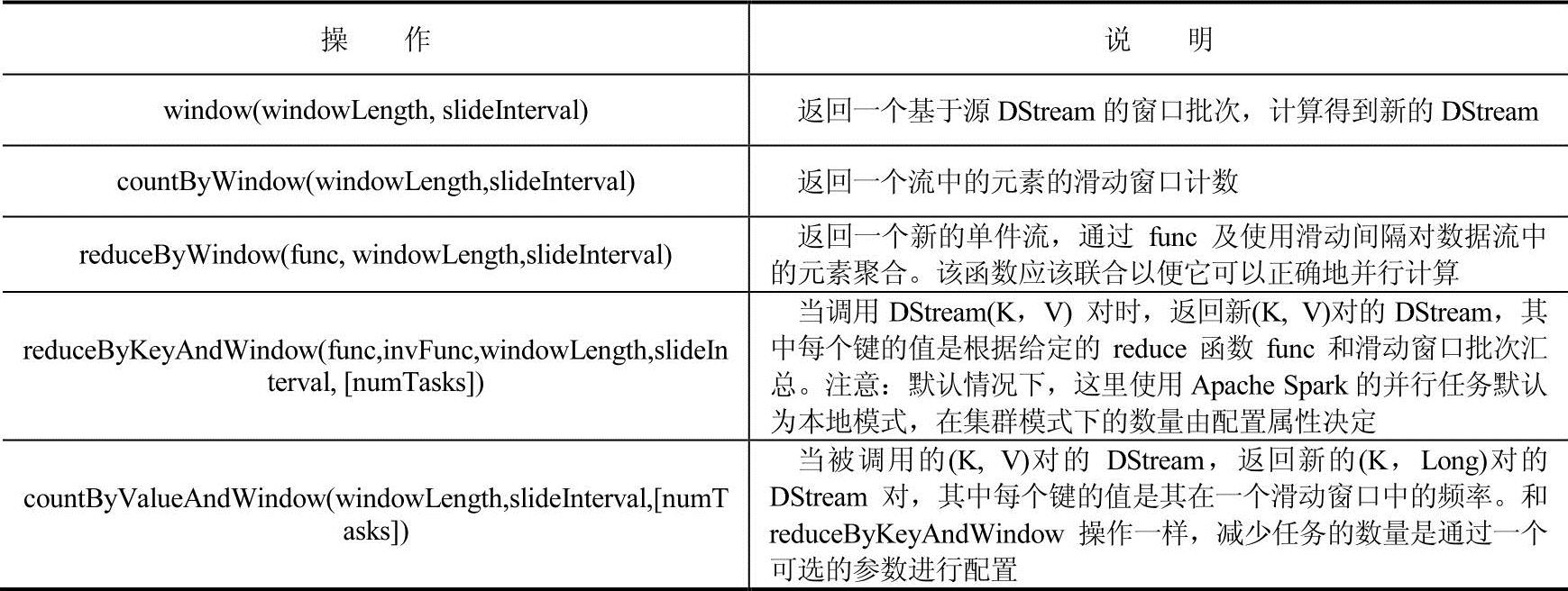
一些常见的窗口的操作如表4-9所示,所有这些操作的参数都包括windowLength和slideInterval。
表4-9 窗口常见操作
API文档中提供DStream转换的完整列表。对于Scala的API,可参考DStream和PairDStreamFunctions。对于Java的API,可参考JavaDStream和JavaPairDStream。
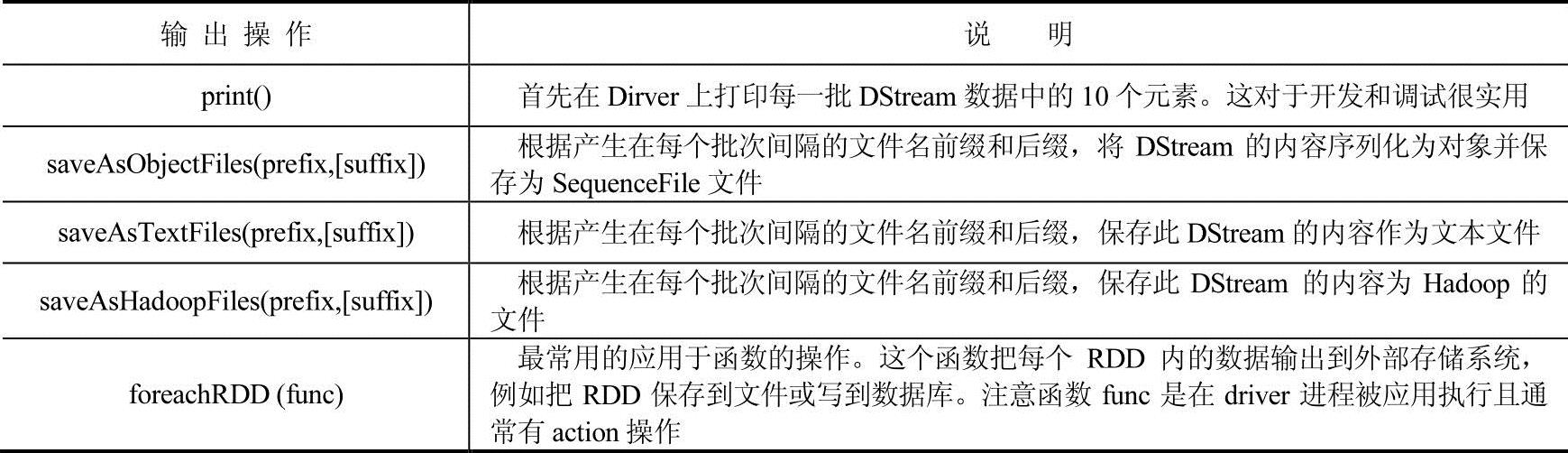
5.离散流(DStream)输出操作
输出操作允许DStream的数据被推送出外部系统,如数据库或文件系统。由于输出操作实际上使变换后的数据被外部系统使用,它们触发了所有DStream转换的实际执行(类似于RDDs操作),输出操作的定义如表4-10所示。
表4-10 DStream输出操作
6.DataFrame和SQL操作
使用DataFrames和SQL操作流数据,首先,必须通过StreamingContext正在使用的SparkContext对象来创建一个SQLContext,然后Spark Streaming才可以在驱动程序运行失败后重新启动。下面这个例子【例4-14】是通过DataFrames和SQL来对单词进行计数,每一个RDD都会转换为DataFrame,并注册为一个临时表然后执行SQL查询。
【例4-14】RDD和SQL操作示例。

可以在不同的线程中运行SQL语句去查询被注册为临时表的流式数据,也就是可以异步运行StreamingContext。但是,必须确保设置的StreamingContext能够保留住足够多的流数据以便查询可以运行,否则没有意识到异步查询的StreamingContext会在查询语句完成之前删除旧的流式数据。例如,如果想要查询最后一批数据,但是查询需要5分钟的时间才能够运行完,那么就需要对StreamingContext进行设置:streaming Context.remember (Minutes(5))。
7.MLlib操作
在使用Spark Streaming的过程中,还可以轻松地使用MLlib提供的机器学习算法。有一类流式机器学习算法(例如流线性回归,流KMeans等),这些算法可以同时从流数据以及应用在流数据上的模型中学习。除了这些,还有另一大类的机器学习算法,这些算法可以对离线的数据进行学习,然后将得到的数据模型应用在在线的流式数据处理中。更多细节请参见MLlib章节。
8.缓存与持久化
类似RDD,DStream还允许开发者把流的数据持久化到内存中。也就是说,在DStream中用persist方法将自动持久化DStream中的每一个RDD到内存中,如果在DStreams的数据将被计算多次,这是很有用的。对于像基于窗口的操作reduceByWindow和reduceByKeyAnd Window和基于状态的操作例如updateState ByKey,持久化操作是默认的,无需开发人员调用persist。
对于通过网络接收数据(如Kafka,Flume,Socket等)的输入数据流,默认持久化等级被设定为将数据复制到两个节点用于容错。注意,不像RDD,DStream的默认持久化等级将序列化数据到内存中。
9.检查点
一个Streaming应用必须保证7天的连续工作,所以必须能应对非应用逻辑出现的错误(如系统错误,JVM崩溃等)。Spark Streaming需要保存足够的信息到容错存储系统,这样在面对错误的时候能恢复数据。这里有两种类型的数据进行checkpoint操作。
(1)元数据
把定义着Streaming计算过程的内容保存在的容错系统(如HDFS)中,在节点运行Streaming应用失败后用来恢复数据。元数据包括以下内容。
1)配置文件——创造Streaming应用的配置文件。
2)DStream操作——定义Streaming应用的一系列操作集合。
3)不完全的批处理内容——在队列中但没有被完成的批处理。
(2)中间数据
把生成的RDD保存到可靠存储系统,这在一些状态转移的多个批数据处理结合过程中很有必要的。在容错处理的转换过程中,根据RDD依赖链进行RDD生成的时间会增加。为了避免这样的约束,周期性的checkpoint数据到可靠存储系统将显得十分重要。
1)何时启动checkpoint。checkpoint在下列需求中必须被启用:
● 状态变化的使用场景——如果updateStateByKey或者reduceByKeyAndWindow被使用,则必须为保存RDD的checkpoint信息设置chenkpoint目录。
● 运行应用的driver从错误中恢复——元数据被应用到进程信息恢复中。
注意,简单的应用无须启用checkpoint也可以使用。
2)如何配置checkpoint。Checkpointing(检查,即保存当前RDD运行的依赖信息到磁盘上)可以从可靠系统(如HDFS,S3等)中设置目录,通过使用streamingContext. checkpoint(checkpointDirectory)方法来完成,配置这样就可以使用如上所述的状态转移信息了。此外,当应用程序出现下面的两种情况时,如果想从驱动错误中恢复,则需要重写Streaming应用。● 程序第一次运行的时候,它会创建一个StreamingContext,建立起所有的Streams然后启用start。
● 程序在出错之后被重启动的时候,它会从checkpoint目录中的checkpoint数据中重新创建StreamingContext。
【例4-15】StreamingContext的使用示例。


10.应用部署
Spark Streaming应用程序可以与任何其他的Spark应用部署在集群上。使用高级源(如Kafka,Flume,Twitter)的应用程序需要将其链接的位置和依赖打包,例如,使用应用程序TwitterUtils将必须包括spark-streaming-twitter_2.10和其所有相关依赖。
如果正在运行的Spark Streaming应用程序需要升级,那么有下面两种机制。
1)升级后的Spark Streaming应用程序启动之后与现有运行中应用程序并行运行。一旦新的程序正常运行之后,旧的程序就可以停用。请注意,这种方式适合于支持数据发送到两个目的地的数据源来完成。
2)现有的应用程序正常关闭
并确保已接收的数据在关闭前被完全处理。升级后的应用程序可以启动,并从之前程序停止的同一点开始处理。注意,这需要数据源(如Kafka、Flume)在应用停止和升级应用且未启动之前把输入的数据存入缓存中。
11.应用监控
当用StreamingContext时,Spark Web UI显示了一个额外的Streaming选项卡,用于显示有关运行数据的接收器信息(接收器是否处于活动状态,收到的记录数量,接收错误等)和完成的批次(批次处理时间,排队时延等)等统计信息。这可以用于监测Streaming应用程序的进度。
Web UI中的两个指标尤为重要:处理时间和调度延迟(批量处理统计下)。第一个是要处理的每个批次数据的时间,第二个是在batch队列中等待先前批次的处理结束时间。
如果批次处理时间比批次间隔多或排队延迟不断增加,则说明该系统是无法处理且落后于正在生成的批次。在这种情况下,可以考虑减少批次处理时间。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。