



RDD的操作算子除了单值型还有键值对(Key-Value)型。这里开始介绍键值对型的算子,主要包括groupByKey、combineByKey、reduceByKey、sortByKey、cogroup和join,如表3-5所示。
表3-5 键值对型Transformation算子

1.groupByKey
类似groupBy方法,作用是把每一个相同Key的Value聚集起来形成一个序列,可以使用默认分区器和自定义分区器,但是这个方法开销比较大,如果想对相同Key的Value聚合或求平均,则推荐使用aggregateByKey或者reduceByKey。方法源码实现如下。

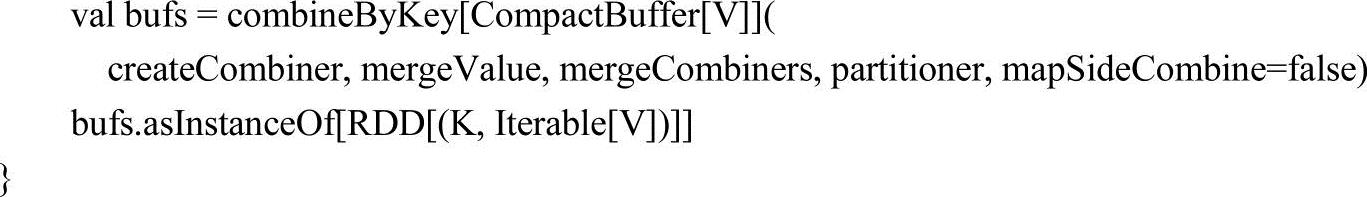
【例3-20】groupByKey方法应用样例。
val a=sc.parallelize(List("mk","zq","xwc","fjg","dcp","snn"),2)
val b=a.keyBy(x=>x.length)//keyBy方法调用map(x=>(f(x),x))生成键值对
b.groupByKey.collect
res6:Array[(Int,Iterable[String])]=Array((2,CompactBuffer(mk,zq)),(3,CompactBuffer(xwc,fjg,dcp,snn)))
这个例子先创建包含List集合对象的RDD,然后使用keyBy方法生成Key-Value键值对,然后调用groupByKey方法将相同Key的Value聚合,最后调用collect方法以数组形式输出,如图3-7所示。

图3-7 groupByKey方法应用样例
2.combineByKey
combineByKey方法能高效地将键值对形式的RDD相同Key的Value合并成序列形式,用户能自定义RDD的分区器和是否在map端进行聚合操作。方法源码实现如下。


【例3-21】combineByKey方法应用样例。

在使用zip方法得到键值对序列c后调用combineByKey方法,把相同Key的Value合并到List中。这个例子中使用3个参数的重载方法,该方法第一个参数createCombiner,作用是把元素V转换到另一类型元素C,该例子中使用的参数是List(_),表示将输入的元素放在List集合中;第二个参数mergeValue的含义是把元素V合并到元素C中,在该例子中使用的是x:List[String],y:String)=>y::x,表示将y字符串合并到x链表集合中;第三个参数mergeCombiners的含义是将两个C元素合并,在该例子中使用的是x:List[String],y:List[String]=x:::y,表示把x链表集合中的内容合并到y链表集合中。
3.reduceByKey
使用一个reduce函数来实现对相同Key的Value的聚集操作,在发送结果给reduce前会在map端执行本地merge操作。该方法的底层实现就是调用combineByKey方法的一个重载方法。方法源码实现如下。

【例3-22】reduceByKey方法应用样例。
● val a=sc.parallelize(List("dcp","fjg","snn","wc","zq"),2)
val b=a.map(x=>(x.length,x))
b.reduceByKey((a,b)=>a+b).collect
res22:Array[(Int,String)]=Array((2,wczq),(3,dcpfjgsnn))
● val a=sc.parallelize(List(3,12,124,32,5),2)
val b=a.map(x=>(x.toString.length,x))(https://www.xing528.com)
b.reduceByKey(_+_).collect
res24:Array[(Int,Int)]=Array((2,44),(1,8),(3,124))
这个例子先用map方法映射出键值对,然后调用reduceByKey方法对相同Key的Value值进行累加。第一个例子是使用的字符串,故使用聚合相加后是字符串的合并;第二个例子使用的是数字,结果是相应的相同Key的Value数字相加。
4.sortByKey
这个函数会根据Key值对键值对进行排序,如果Key是字母,则按字典顺序排序,如果Key是数字,则从小到大排序(或从大到小),该方法的第一个参数控制是否为升序排序,当为true时是升序,反之则为降序。方法源码实现如下。

【例3-23】sortByKey方法应用样例。
val a=sc.parallelize(List("dog","cat","owl","gnu","ant"),2)
val b=sc.parallelize(1 to a.count.toInt,2)//a.count得到单词的字母个数
val c=a.zip(b)
c.sortByKey(true).collect
res74:Array[(String,Int)]=Array((ant,5),(cat,2),(dog,1),(gnu,4),(owl,3))
c.sortByKey(false).collect
res75:Array[(String,Int)]=Array((owl,3),(gnu,4),(dog,1),(cat,2),(ant,5))
这个例子先通过zip方法得到包含键值对的变量c,然后演示了sortByKey方法中参数为true和false时的计算结果。本例中的Key是字符串,故可以看出当Key为true时,结果是按Key的字典顺序升序输出,反之则为降序输出结果;当Key为数字的时候,则按大小排列。
5.cogroup
cogroup方法是一个比较高效的函数,能根据Key值聚集最多3个键值对的RDD,并把相同Key值对应的Value聚集起来。方法源码实现如下。


【例3-24】cogroup方法应用样例。

例子中有两个小例子,依次是单个参数和两个参数的情况,使用cogroup方法对单个RDD和两个RDD进行聚集操作。
6.join
对键值对的RDD进行cogroup操作,然后对每个新的RDD下Key的值进行笛卡尔积操作,再对返回结果使用flatMapValues方法,最后返回结果。方法源码实现如下。

【例3-25】join方法应用样例。

这个例子先构造两个包含键值对元素的变量b和d,然后调用join方法,得到join后的结果。根据源码实现,join方法本质是cogroup方法和flatMapValues方法的组合,其中cogroup方法得到的是聚合值,flatMapValues方法实现的是笛卡尔积,笛卡尔积的过程在各个分区内进行,如例子中的Key等于2分区,wc与(wc,zq)求笛卡尔积,得到(2,(wc,wc))和(2,(wc,zq))的结果。样例的实现过程如图3-8所示。
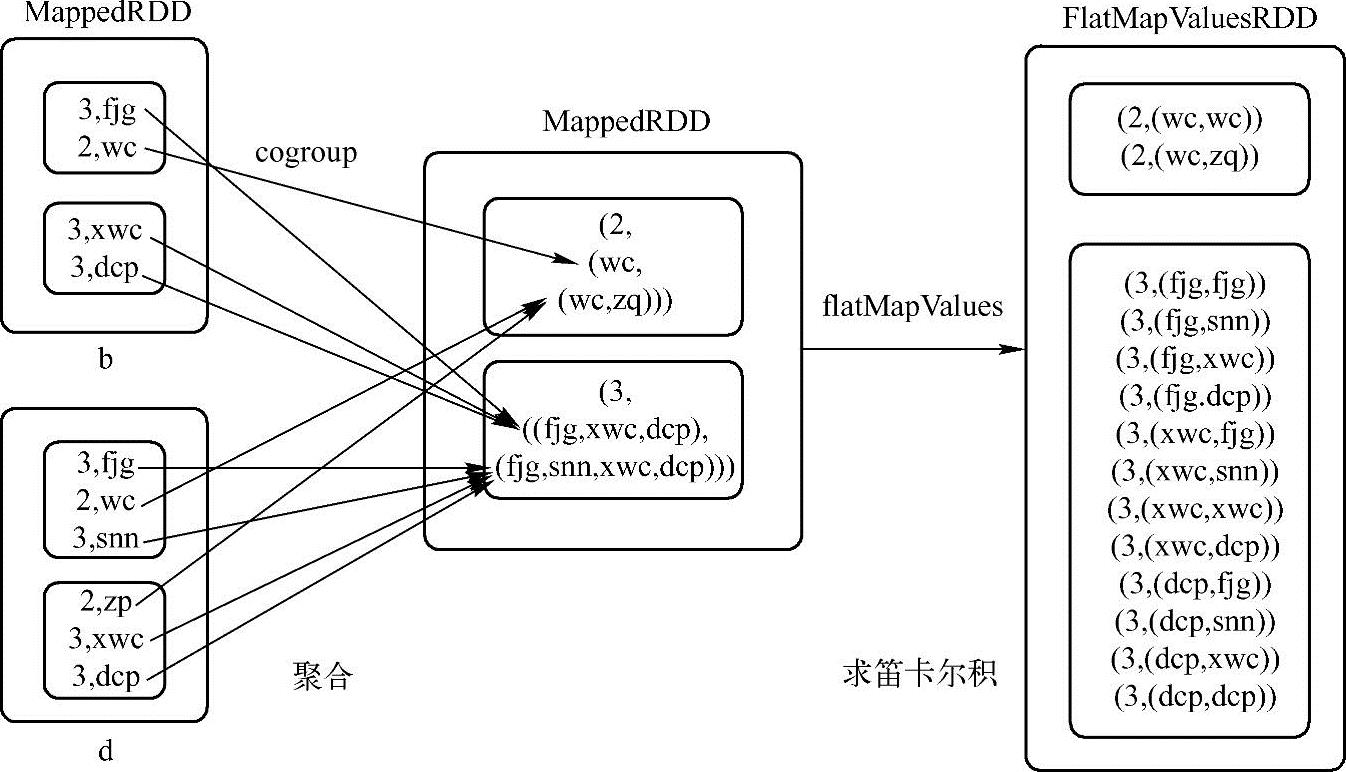
图3-8join方法应用样例
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。