



当Spark的计算模型中出现Action算子时才会执行提交作业的runJob动作,这时会触发后续的DAGScheduler和TaskScheduler工作。这里主要讲解常用的Action算子,有collect、reduce、take、top、count、takeSample、saveAsTextFile、countByKey、aggregate,具体方法和定义如表3-6所示。
表3-6 Action算子
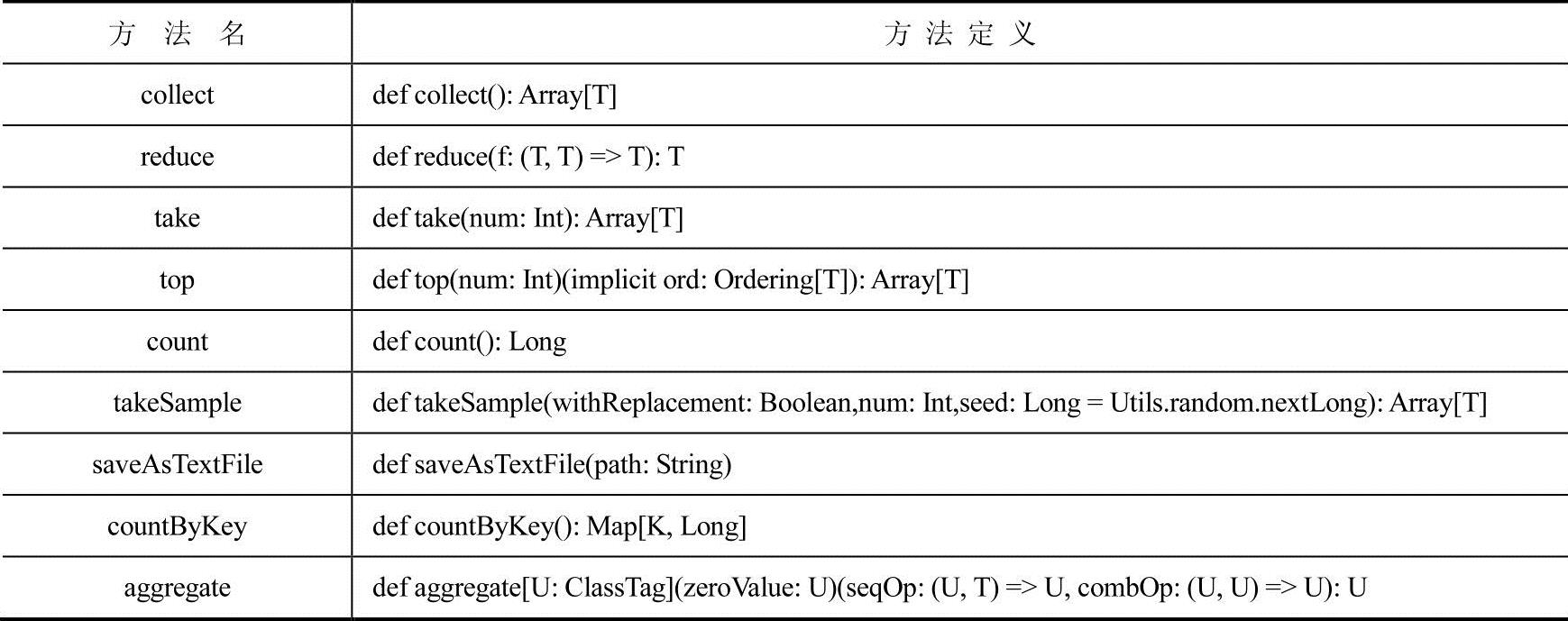
1.collect
collect方法的作用是把RDD中的元素以数组的方式返回。方法源码实现如下。
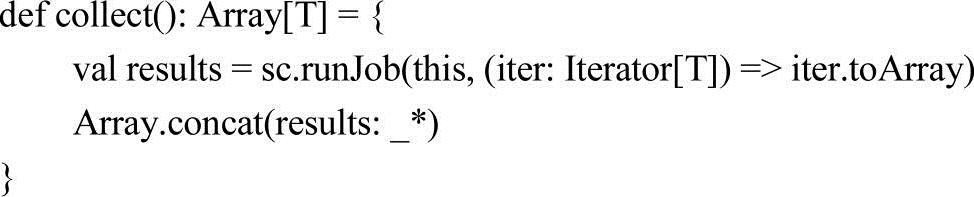
【例3-26】collect方法应用样例。
val c=sc.parallelize(List("a","b","c","d","e","f"),2)
c.collect
res29:Array[String]=Array(a,b,c,d,e,f)
这个例子直接把RDD中的元素转换成数组返回。
2.reduce
reduce方法使用一个带两个参数的函数把元素进行聚集,返回一个元素结果,注意该函数中的二元操作应该满足交换律和结合律,这样才能在并行系统中正确计算。方法源码实现如下。

【例3-27】reduce方法应用样例。
val a=sc.parallelize(1 to 10)
a.reduce((a,b)=>a+b)
res41:Int=55
这个例子使用简单的函数将输入的元素相加,过程是先输入前两个元素使其相加,然后将得到的结果与下一个输入元素相加,依次规则计算出所有元素的和。
3.take
take方法会从RDD中取出前n[2]个元素。方法是先扫描一个分区,之后从分区中得到结果,然后评估得到的结果是否达到取出元素个数,如果没达到则继续从其他分区中扫描获取。方法源码实现如下。

【例3-28】take方法应用样例。
● val b=sc.parallelize(List("a","b","c","d","e"),2)
b.take(2)
res18:Array[String]=Array(a,b)
● val b=sc.parallelize(1 to 100,5)
b.take(30)
res6:Array[Int]=Array(1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,
25,26,27,28,29,30)
这两个例子分别演示了字母和数字的情况,其实工作原理都相同,即从分区中按先后顺序取元素。
4.top
top方法会利用隐式排序转换方法(见实现源码中implicit方法)来获取最大的前n个元素。方法源码实现如下。
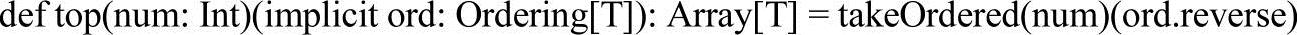

【例3-29】top方法应用样例。
val c=sc.parallelize(Array(1,3,2,4,9,2,11,5),3)
c.top(3)
res10:Array[Int]=Array(11,9,5)
例子显示了top的使用方法,很简洁,直接输入元素个数作为参数就能得到前k个元素的值。
5.count
count方法计算并返回RDD中元素的个数。方法源码实现如下。(https://www.xing528.com)

【例3-30】count方法应用样例。
val c=sc.parallelize(Array(1,3,2,4,9,2,11,5),2)
c.count
res3:Long=8
6.takeSample
takeSample方法返回一个固定大小的数组形式的采样子集,此外还把返回的元素顺序随机打乱,方法的3个参数含义依次为是否放回数据、返回取样的大小和随机数生成器的种子。方法源码实现如下。

【例3-31】takeSample方法应用样例。
val x=sc.parallelize(1 to 100,2)
x.takeSample(true,30,1)
res13:Array[Int]=Array(72,37,96,47,40,96,57,100,8,44,82,11,32,47,99,94,37,97,52,
41,100,78,93,11,6,100,75,14,47,16)
这个例子直接使用takeSample方法,得到30个固定数字的样本,采取有放回抽样的方式。
7.saveAsTextFile
saveAsTextFile方法把RDD存储为文本文件,一次存一行。方法源码实现如下。

【例3-32】saveAsTextFile方法应用样例。

8.countByKey
类似count方法,不同的是countByKey方法会根据相同的Key计算其对应的Value个数,返回的是map类型的结果。方法源码实现如下。
def countByKey():Map[K,Long]=self.mapValues(_=>1L).reduceByKey(_+_).collect().toMap
【例3-33】countByKey方法应用样例。
val a=sc.parallelize(List((1,"bit"),(2,"xwc"),(2,"fjg"),(3,"wc"),(3,"wc"),(3,"wc")),2) a.countByKey
res3:scala.collection.Map[Int,Long]=Map(1->1,2->2,3->3)
这个例子先构造键值对变量a,然后使用countByKey方法对相同Key的Value进行统计,过程是先调用mapValue方法把Value映射为1,再调用reduceByKey方法得到相同到Key对应的Value个数。
9.aggregate
aggregate方法先将每个分区里面的元素进行聚合,然后用聚合函数将每个分区的结果和初始值(zero Value)进行聚合操作。这个函数最终返回的类型不需要和RDD中元素的类型一致。
aggregate有两个函数seqOp和combOp,这两个函数都是输入两个参数,输出一个参数,其中seqOp函数可以看成是reduce操作,combOp函数可以看成是第二个reduce操作(一般用于聚合各分区结果到一个总体结果)。由定义可以看出,combOp操作的输入和输出类型必须一致。方法源码实现如下。

【例3-34】aggregate方法应用样例。

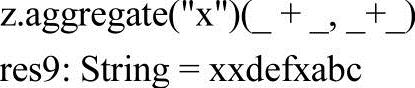
在Spark中一个分区对应一个task,从源码来看,zeroValue参与每个分区的seqOp(reduce)方法和最后的combOp(第二个reduce)方法,先对每个分区求reduce,在该例子中是对3个分区分别求Max操作,得到分区最大值,得到的结果参与combOp方法,即把各分区的结果和zeroValue相加,最后得到结果值,从前两个例子可以看出这个操作先分后总的思想。
后面两个例子使用的是字符串,与aggregate方法的思路一样,先对各分区求seqOp方法然后再使用combOp方法把各分区的结果聚合相加,得到最终结果。
10.fold
fold方法与aggregate方法原理类似,区别就是少了一个seqOp方法。fold方法是把每个分区的元素进行聚合,然后调用reduce(op)方法处理。方法源码实现如下。

【例3-35】fold方法应用样例。

这个例子中的使用方式与aggregate方法非常相似,注意,zeroValue参与所有分区计算。fold计算保证每个分区的独立计算,它与aggregate最大的区别是aggregate对不同分区提交的最终结果定义了一个专门的comOp函数来处理,而fold方法是采用一个方法来处理aggregate的两个方法的过程。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。