



单值型的算子就是输入为单个值形式,这里主要介绍map、flatMap、mapPartitions、union、cartesian、groupBy、filter、distinct、subtract、foreach、cache、persist、sample以及takeSample方法,如表3-4中列出了各个方法的简要概述。
表3-4 单值型Transformation算子

(续)

1.map
对原来每一个输入的RDD数据集进行函数转换,返回的结果为新的RDD,该方法对分区操作是一对一的。方法源码实现如下。
defmap[U:ClassTag](f:T=>U):RDD[U]=newMappedRDD(this,sc.clean(f))
【例3-4】map方法应用样例。

这个例子中map方法从a中依次读入一个单词,然后计算单词长度,把最后计算的长度赋给b,然后因为a和b的长度相同,使用zip方法将a、b中对应元素组成K-V键值对形式,最后使用Action算子中的collect方法把键值对以数组形式输出,如图3-3所示。图3-3中的map方法在1.4版后输出的是MapPartitionsRDD,而不再有MappedRDD类,但为了照顾不同读者,这里还是使用老版本的写法。下文的flatMapValues方法输出结果在老版本中为Flat Map ValuesRDD类,也在1.4版后改为MapPartitionsRDD。
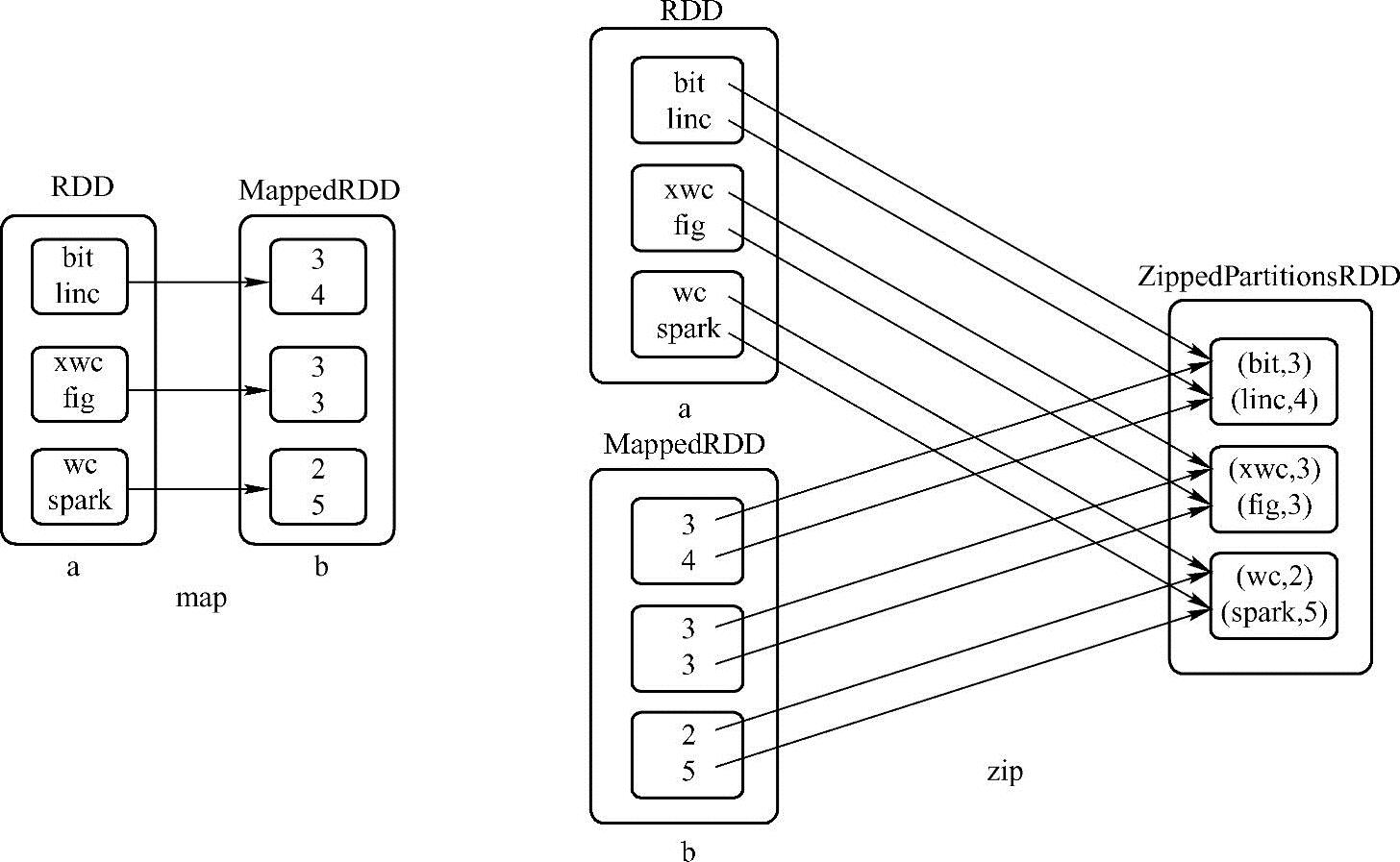
图3-3 map方法应用样例
2.flatMap
flapMap方法与map方法类似,但是允许在一次map方法中输出多个对象,而不是map中的一个对象经过函数转换生成另一个对象。方法源码实现如下。
def flatMap[U:ClassTag](f:T=>TraversableOnce[U]):RDD[U]=new FlatMappedRDD(this,sc.clean(f))
【例3-5】flatMap方法应用样例。
val a=sc.parallelize(1to 10,5) //生成从1到10的序列,5个分区
a.flatMap(num=>1 to num).collect //方法的作用是把每一个num映射到从1到num的序列
res47:Array[Int]=Array(1,1,2,1,2,3,1,2,3,4,1,2,3,4,5,1,2,3,4,5,6,1,2,3,4,5,6,7,1,2,3,4, 5,6,7,8,1,2,3,4,5,6,7,8,9,1,2,3,4,5,6,7,8,9,10)
这个例子先得到从1到10的序列,然后调用flatMap方法对输入的num依次生成从1到num的序列,最后使用collect方法转换成数组输出。
3.mapPartitions
mapPartitions是map的另一个实现。map的输入函数应用于RDD中每个元素,而mapPartitions的输入函数作用于每个分区,也就是把每个分区中的内容作为整体来处理。方法源码实现如下。

【例3-6】mapPartitions方法应用样例。

如图3-4,这个例子是先得到从1到9的序列,因为有3个分区,所以每个分区数据分别是(1,2,3),(4,5,6)和(7,8,9),然后调用mapPartitions方法,因为Scala是函数式编程,函数能作为参数值,所以mapPartition方法输入参数是myfunc函数。myfunc函数的作用是先构造一个空list集合,输入单元素集合iter,输出双元素Tuple集合,把分区中一个元素和它的下一个元素组成一个Tuple。因为每个分区中最后一个元素没有下一个元素,所以(3,4)和(6,7)不在结果中。
mapPartitions还有其他的类似实现,比如mapPartitionsWithContext,它能把处理过程中的一些状态信息传递给用户指定的输入函数,此外还有mapPartitionsWithIndex,它能把分区中的index信息传递给用户指定的输入函数,这些其他类似的实现都是基于map方法,只是细节不同,这样做更方便使用者在不同场景下的应用。
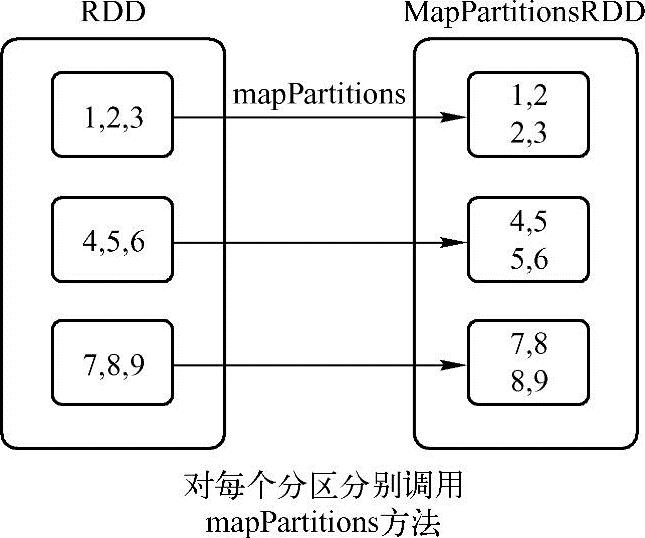
图3-4 mapPartitions方法应用样例
4.mapPartitionWithIndex
mapPartitionWithIndex方法与mapPartitions方法功能类似,不同的是mapPartitionWith-Index还会对原始分区的索引进行追踪,这样就能知道分区所对应的元素,方法的参数为一个函数,函数的输入为整型索引和迭代器。方法源码实现如下。

【例3-7】mapPartitionWithIndex方法应用样例。

这个例子中先得到一个名为的x序列,然后调用mapPartitionsWithIndex方法,参数为myfunc函数,这个函数把输入通过map方法映射为分区索引加值的形式。结果中的“0,1”表示分区下标0和第一个输入值1,后面依次输出其他分区和对应的值,说明分区数是从下标0开始的。
5.foreach
foreach方法主要是对每一个输入的数据对象执行循环操作,该方法常用来输出RDD中的内容。
方法源码实现:

【例3-8】foreach方法应用样例
val c=sc.parallelize(List("xwc","fjg","wc","dcp","zq","snn","mk","zl","hk","lp"),3)
c.foreach(x=>println(x+"are from BIT"))
xwc are from BIT
fjg are from BIT
wc are from BIT
dcp are from BIT
zq are from BIT
ssn are from BIT
mk are from BIT
zl are from BIT
hk are from BIT
lp are from BIT
这个方法比较直观,直接对c变量中的每一个元素对象使用println函数,打印对象内容。
6.foreachPartition
foreachPartition方法的作用是通过迭代器参数对RDD中每一个分区的数据对象应用函数。mapPartitions方法与foreachPartition方法的作用非常相似,区别在于使用的参数是否有返回值。方法源码实现如下。

【例3-9】foreachPartition方法应用样例。
val b=sc.parallelize(List(1,2,3,4,5,6,7,8,9),3)
b.foreachPartition(x=>println((a,b)=>x.reduce(a+b)))
6
15
24
这个例子是将序列b中的每一个元素进行reduce操作,对每个分区中输入的每一个元素累加,例如对于分区0,输入1和2相加等于3,然后把上个结果3与下一个输入3相加就等于6,其他分区的运算与该分区一样。
7.glom
作用类似collect,但它不是直接将所有RDD直接转化为数组形式,glom方法的作用是将RDD中分区数据组装到数组类型RDD中,每一个返回的数组包含一个分区的所有元素,按分区转化为数组,最后有几个分区就返回几个数组类型的RDD。方法源码实现如下。

【例3-10】glom方法应用样例
val a=sc.parallelize(1 to 99,3)
a.glom.collect
res5:Array[Array[Int]]=Array(Array(1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33),Array(34,35,36,37,38,39,40,41,42,43,44,45,46,47,48,49,50,51,52,53,54,55,56,57,58,59,60,61,62,63,64,65,66),Array(67,68,69,70,71,72,73,74,75,76,77,78,79,80,81,82,83,84,85,86,87,88,89,90,91,92,93,94,95,96,97,98,99))
这个例子很简洁,在执行glom方法后就调用collect方法获得Array数组并输出,可以看出a.glom方法输出的是三个数组组成的RDD,其中每个数组代表一个分区数据。
8.union
union方法(等价于“++”)是将两个RDD取并集,取并集的过程中不会把相同元素去掉。union操作是输入分区与输出分区多对一模式。方法源码实现如下。

【例3-11】union方法应用样例。
val a=sc.parallelize(1 to 4,2)(https://www.xing528.com)
val b=sc.parallelize(2 to 4,1)
(a++b).collect
res4:Array[Int]=Array(1,2,3,4,2,3,4)
这个例子先创建2个RDD变量a和b,然后对a与b使用union方法,返回两个RDD并集的结果,如图3-5所示。
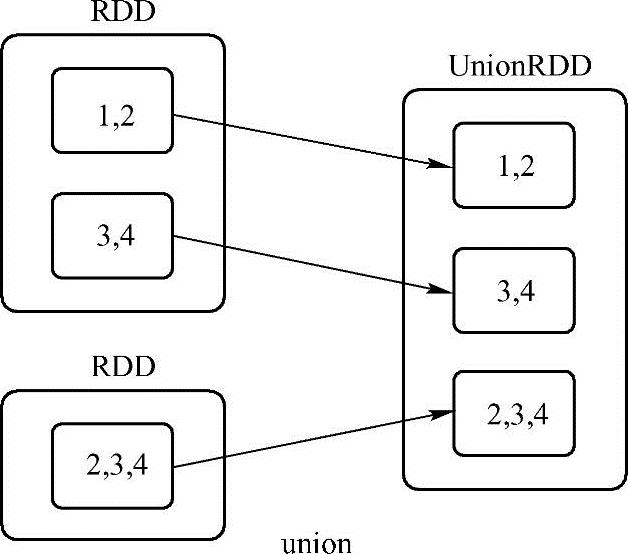
图3-5 union方法应用样例
9.cartesian
计算两个RDD中每个对象的笛卡尔积(例如第一个RDD中的每一个对象与第二个RDD中的对象join连接),但使用该方法时要注意可能会出现内存不够的情况。方法源码实现如下。


【例3-12】cartesian方法应用样例。
val x=sc.parallelize(List(1,2,3),1)
val y=sc.parallelize(List(4,5),1)
x.cartesian(y).collect
res0:Array[(Int,Int)]=Array((1,4),(1,5),(2,4),(2,5),(3,4),(3,5))
例子中x是第一个RDD,其中的每个元素都跟y中元素进行连接,如果第一个RDD有m个元素,第二个RDD中元素n个,则求笛卡尔积后总元素为m×n个,本例结果为6个,如图3-6所示。
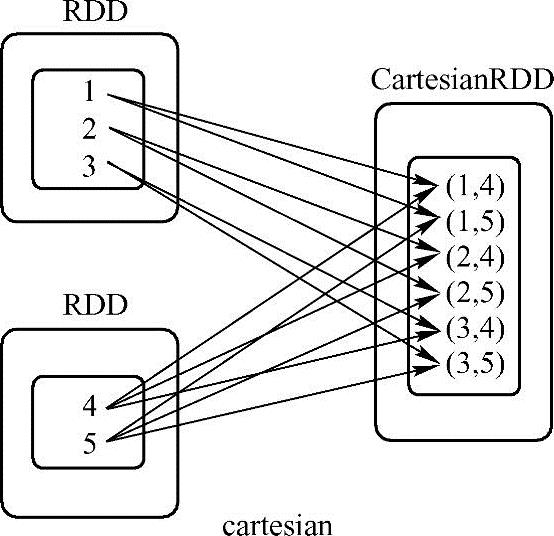
图3-6 cartesian方法应用样例
10.groupBy
groupBy方法有3个重载方法,功能是将元素通过map函数生成Key-Value格式,然后使用reduceByKey方法对Key-Value对进行聚合,方法源码实现如下。

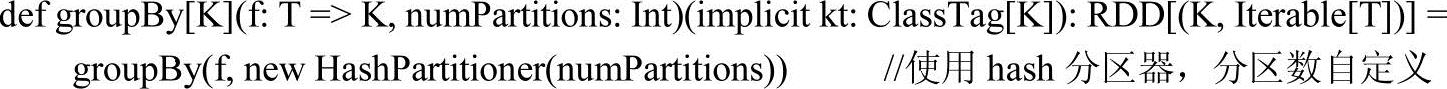
【例3-13】groupBy方法应用样例。

第一个例子中是单个参数,调用groupBy方法,结果集的Key只有两种,即even和odd,然后对相同的Key进行聚合得到最终结果。第二个例子和第三个例子本质一样,只是使用的重载方法不同。
11.filter
filter方法是对输入元素进行过滤,参数是一个返回值为boolean的函数,如果函数对输入元素运算结果为true,则通过该元素,否则就将该元素过滤,不能进入结果集。方法源码实现如下。def filter(f:T=>Boolean):RDD[T]=new FilteredRDD(this,sc.clean(f))
【例3-14】filter方法应用样例。

第一个和第二个例子比较好理解,因为a中元素都是整型,可以顺利进行比较,但第三个例子会报错,因为a中有部分对象不能与整数比较,使用Scala中的偏函数可以解决混合数据类型的问题。
12.distinct
distinct方法是将RDD中重复的元素去掉,只留下唯一的RDD元素。方法源码实现如下。def distinct():RDD[T]=distinct(partitions.size)
def distinct(numPartitions:Int)(implicit ord:Ordering[T]=null):RDD[T]=
map(x=>(x,null)).reduceByKey((x,y)=>x,numPartitions).map(_._1)
【例3-15】distinct方法应用样例。
● val c=sc.parallelize(List("Gnu","Cat","Rat","Dog","Gnu","Rat"),2)
c.distinct.collect
res6:Array[String]=Array(Dog,Gnu,Cat,Rat)
● val a=sc.parallelize(List(1,2,3,4,5,6,7,8,9,10))
a.distinct(2).partitions.length
res16:Int=2
● a.distinct(3).partitions.length
res17:Int=3
这个例子就是把RDD中的元素map为Key-Value对形式,然后使用reduceByKey将重复的Key合并,也就是把重复元素删除,只留下唯一的元素。此外distinct有一个重载方法需要一个参数,这个参数就是分区数numPartitions,从例子中可以看出使用带参的distinct方法不仅能删除重复元素,而且还能对结果重新分区。
13.subtract
subtract方法就是求集合A-B的差,即把集合A中包含集合B的元素都删除,结果是剩下的元素。方法源码实现如下。

【例3-16】subtract方法应用样例。
val a=sc.parallelize(1 to 9,3)
val b=sc.parallelize(1 to 3,3)
val c=a.subtract(b)
c.collect
res3:Array[Int]=Array(6,9,4,7,5,8)
这个例子就是把a中包含b中的元素都删除掉,底层实现使用subtractByKey,也就是根据键值对中的Key来删除a中包含的b中的元素。
14.persist,cache
cache方法顾名思义,就是缓存数据,其作用是把RDD缓存到内存中,以方便下一次计算时被再次调用。方法源码实现如下。
def cache():this.type=persist()
【例3-17】cache方法应用样例。
val c=sc.parallelize(List("a","b","c","d","e","f"),1)
c.cache
res11:c.type=ParallelCollectionRDD[10]at parallelize at<console>:21
这个例子就是直接把RDD缓存在内存中。
15.persist
persist方法的作用是把RDD根据不同的级别进行持久化,通过参数指定持久化级别,如果不带参数则为默认持久化级别,即只保存到内存,与cache等价。
【例3-18】persist方法应用样例。
val a=sc.parallelize(1 to 9,3)
a.persist(StorageLevel.MEMORY_ONLY)
例子中,使用persist方法,指定持久化级别为MEMORY_ONLY,该级别等价于cache方法。
16.sample
sample方法的作用是随机的对RDD中的元素采样,获得一个新的子集RDD。根据参数能指定是否放回采样、子集占总数的百分比和随机种子。方法源码实现如下。

【例3-19】sample方法应用样例。
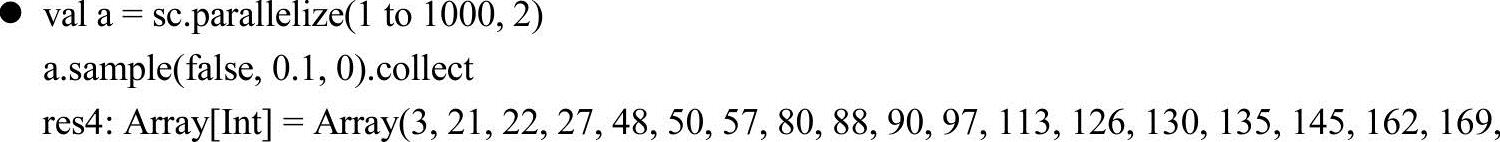

上述例子中Sample方法的第一个参数withReplacement为true时使用放回抽样(泊松抽样[1]),为false时使用不放回抽样(伯努利抽样),第二个参数fraction是百分比,第三个参数seed是种子,也就是随机取值的起源数字。从例子中还看出当选择放回抽样时,取出的元素中会出现重复值。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。