



上述的DSN结构在最近的研究中已经被推广到它的张量版本,我们称之为张量深度堆叠网络(Tensor Deep Stacking Network,TDSN)[180,181]。在并行化学习方面,它和DSN具有相同的扩展性,但是它通过提供更高阶的特征交互,对DSN进行了推广。
在堆叠过程实现方面,TDSN的结构和DSN是非常相似的。也就是说,TDSN的模块使用和DSN相似的方法进行堆叠形成深度结构。而DSN和TDSN的主要不同在于每个模块是如何构建的。在DSN中,一个隐层只由一套隐单元组成,如图6.2的左侧图所示。和DSN相比,TDSN的每个模块中包含两个独立的隐层,如图6.2中间和右侧的两幅图所示,其中使用“隐层1”和“隐层2”表示两个独立的隐层。因为隐层的不同,上层的权值向量,如图6.2中的“U”从DSN中的一个二维数组变成了TDSN中的一个三维数组的张量(tensor),如图6.2中间图所示。
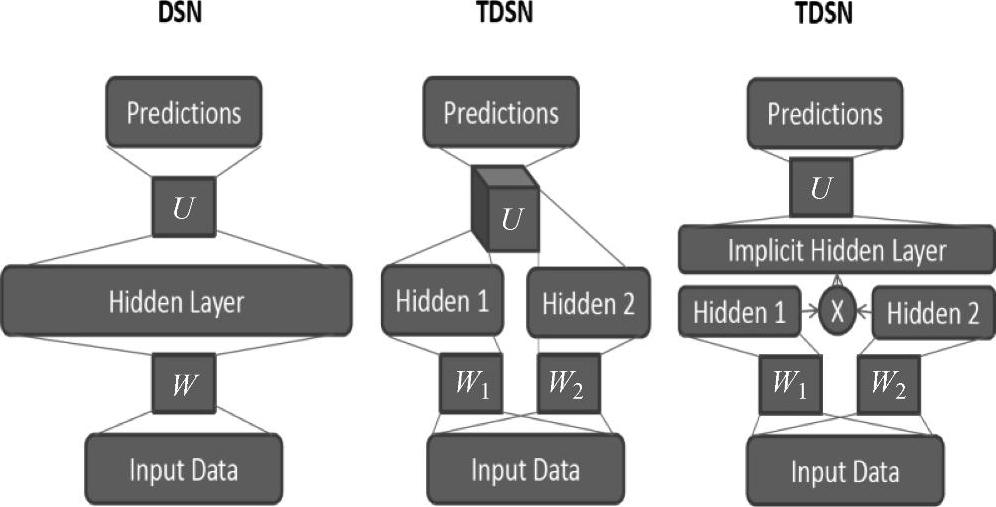
图6.2
图6.2为由一个模块组成的DSN(左图)和TDSN的对比。右面两图是TDSN模块的两种等效的形式。(参考文献[180],@IEEE)
图中词语翻译对照表
张量U是三向连接的,分别连接预测层和两个独立的隐层。TDSN的一个等价形式如图6.2中右侧图所示,将两个独立的隐层进行外积得到间接隐层(图中的间接隐层Implicit Hidden Layer),产生的大向量包含两个隐层的所有可能的成对的元素乘积。这样便又把张量U变成了矩阵,它的维数满足两点:1)和预测层的大小相同;2)是两个隐层的乘积的大小。这种等价形式能够使DSN中学习U的凸优化方法运用到张量U的学习中。更重要的是,通过外积构建规模较大的间接隐层,允许了高阶隐层的特征交互。
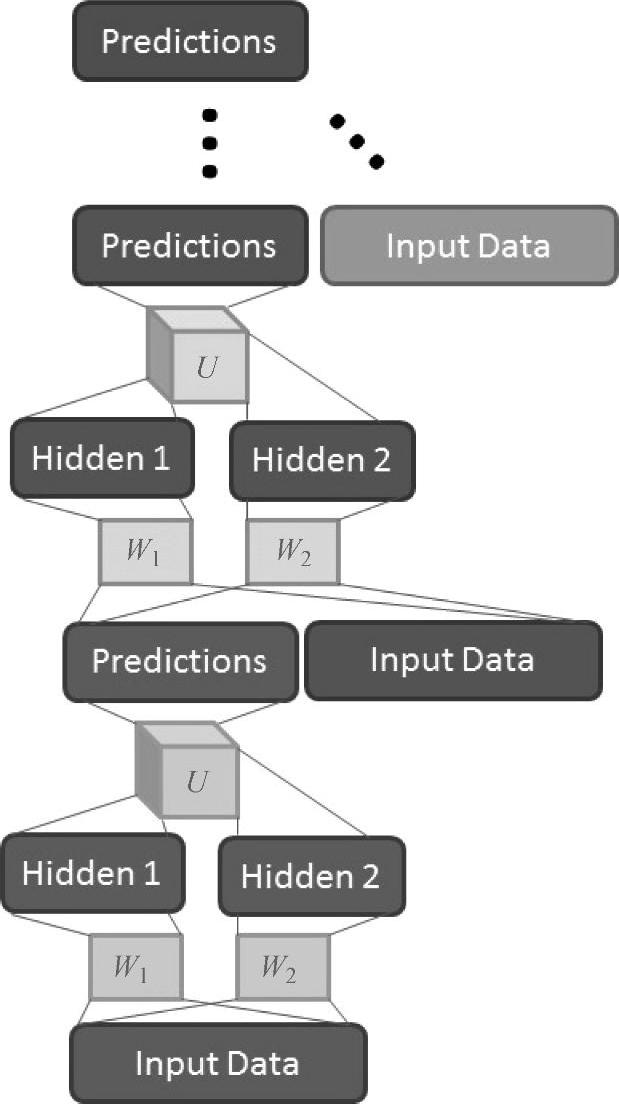
使用与DSN相似的方法,即将各种不同的向量进行拼接,将TDSN模块堆叠组成一个深度结构。图6.3和图6.4通过两个例子说明TDSN的堆叠方法。值得注意的是,对于DSN,将隐层和输入(见图6.4)拼接的堆叠是很困难的,因为在实际应用中,隐层单元的数量是非常大的。
 (https://www.xing528.com)
(https://www.xing528.com)
图6.3
图6.3中通过拼接预测层向量和输入向量堆叠TDSN模块。(参考文献[180],@IEEE)
图6.4中通过拼接两个隐层向量和输入向量实现TDSN模块的堆叠。
图中词语翻译对照表

图6.4
图中词语翻译对照表

免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。