



【摘要】:Spark SQL支持从各种数据源加载文件构建DataFrame,以及将DataFrame保存到各种数据源中。在进行数据源集成之前,先对Spark SQL的数据源进行分析,下面是从源码角度,对内置的数据源、数据源的查找两个方面进行分析。图3.11 Spark SQL内置的数据源类另外,通过数据源的查找的源码可以看出,查找时可以指定数据源类名的全路径的前缀。可以通过继承特质RelationProvider来自定义数据源类来扩展Spark SQL,现有的继承类如图3.12所示。图3.12 Spark SQL数据源的DefaultSource类
通常在企业中使用的数据有多种格式,因此需要支持多种数据来源的处理,将不同数据源集成到企业统一的大数据平台下。Spark SQL支持从各种数据源加载文件构建DataFrame,以及将DataFrame保存到各种数据源中。
在进行数据源集成之前,先对Spark SQL的数据源进行分析,下面是从源码角度,对内置的数据源、数据源的查找两个方面进行分析。
查看源码,可以从任何一个加载数据源的接口触发,最后找到解析数据源的代码。这里数据源的源码在ddl.scala文件中,相关代码如下所示。
1.构建数据源的源码

可以看到,这里Spark SQL内置的数据源支持缩写方式,包含“jdbc”“json”和“parquet”这三种,对应类如图3.11所示。
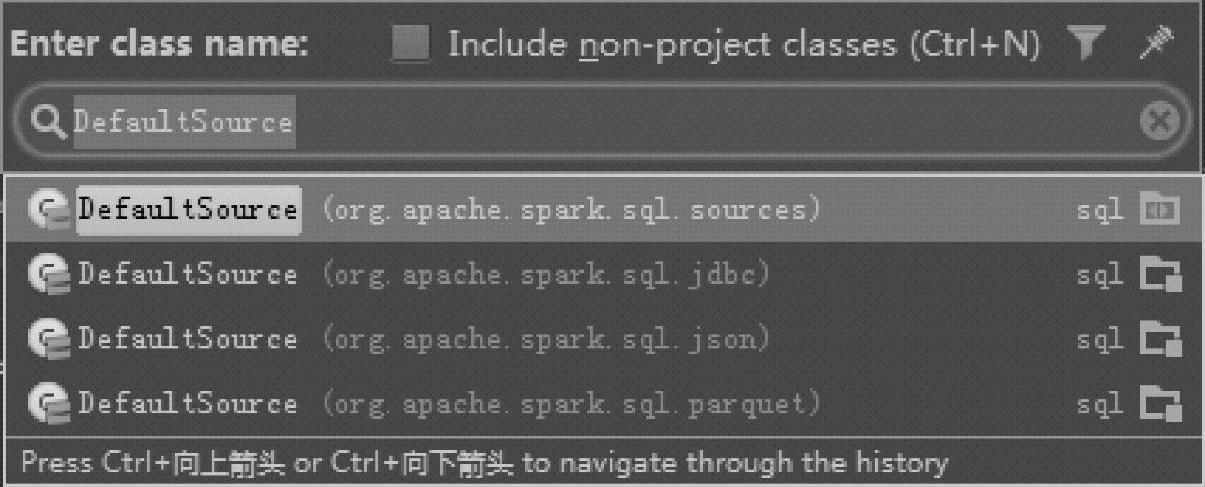
图3.11 Spark SQL内置的数据源类
另外,通过数据源的查找的源码可以看出,查找时可以指定数据源类名的全路径的前缀。(https://www.xing528.com)
2.查找数据源的源码


这里可以看到,当查找数据源时,会从内置支持是三种的数据源中先进行查找,查找失败时,以输入的数据源类路径加类名“.DefaultSource”构建出数据源实例。
可以通过继承特质RelationProvider来自定义数据源类来扩展Spark SQL,现有的继承类如图3.12所示。
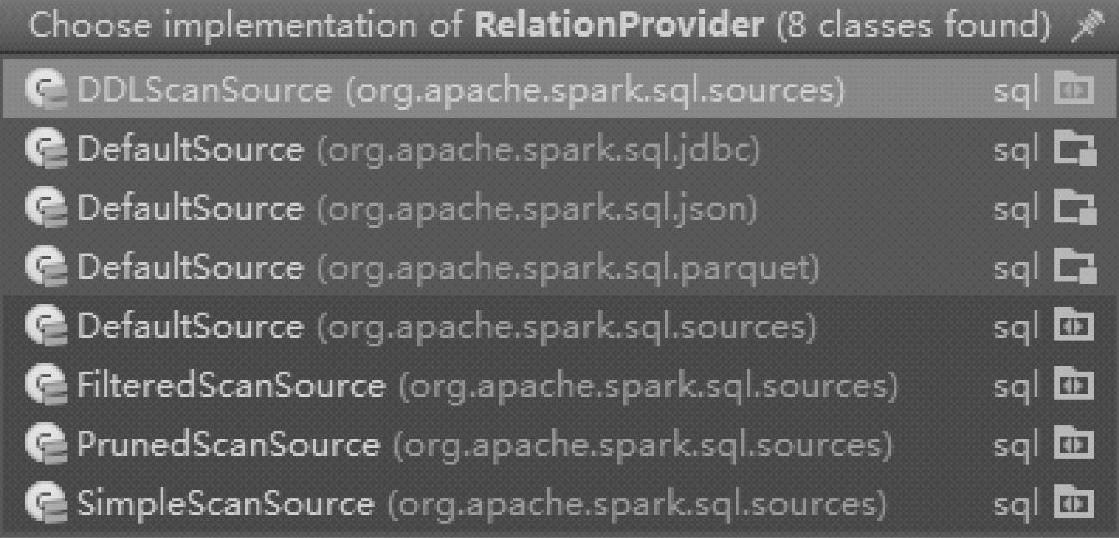
图3.12 Spark SQL数据源的DefaultSource类
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。