



SparkSQL发展历程图如图1-2所示。
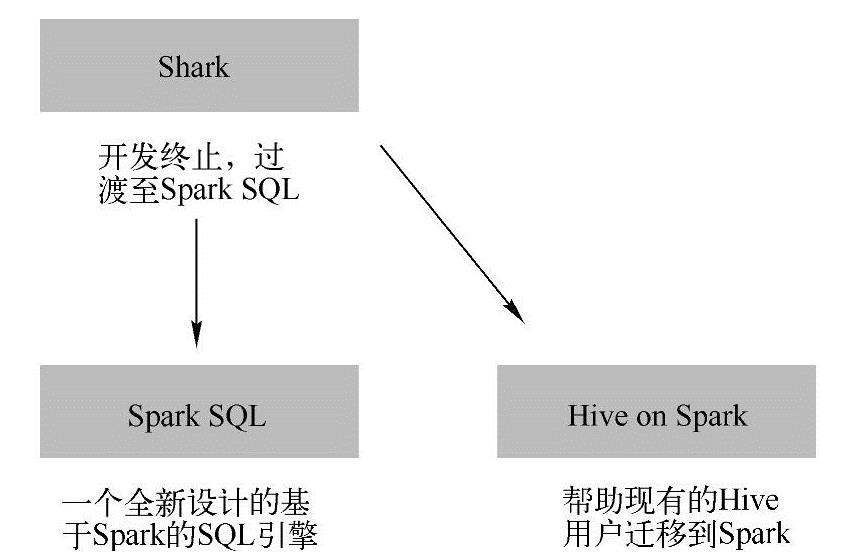
图1-2 Spark SQL发展历程图
SparkSQL是从Shark发展而来的,2014年7月1日的Spark Summit上,Databricks宣布终止对Shark的开发,转向到Spark SQL上。Databricks表示,Spark SQL将涵盖Shark的所有特性,用户可以从Shark 0.9进行无缝的升级。同时Databricks推出Spark SQL和Hiveon Spark。其中Spark SQL是为Spark设计的一代新的SQL引擎,作为Spark生态中的一员继续发展,而不再受限于Hive,只是兼容Hive;而Hive on Spark是将Spark作为一个替代执行引擎提供给Hive的,从而为已经存在的Hive用户提供了一个迁往Spark的途径。
下面简单地介绍一下Shark及Shark项目终止的原因。(https://www.xing528.com)
Shark发布时,Hive可以说是SQL on Hadoop的唯一选择,负责将SQL编译成可扩展的MapReduce作业。鉴于Hive的性能及与Spark的兼容性,Shark项目由此而生。
Shark通过Hive的HQL(Hibernate Query Language)解析,把HQL翻译成Spark上的RDD操作,然后通过Hive的元数据获取数据库里的表信息,实际HDFS上的数据和文件,会由Shark获取并放到Spark上运算。
Shark的最大特性就是速度快以及与Hive的完全兼容,且可以在Shell模式下使用API,把HQL得到的结果集继续在Scala环境下运算,支持自己编写简单的机器学习或简单分析处理函数,对HQL结果进一步分析计算。
但是Shark更多的是对Hive的改造,替换了Hive的物理执行引擎,因此会有一个很快的速度。然而,不容忽视的是,Shark继承了大量的Hive代码,因此给进一步对其优化和维护带来了大量的麻烦。随着性能优化和先进分析整合的进一步加深,基于MapReduce设计的部分无疑成为整个项目的瓶颈。因此,为了更好地发展,给用户提供一个更好的体验,Databricks宣布终止Shark项目,从而将更多的精力放到Spark SQL上。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。