



Spark SQL对SQL语句的处理和关系型数据库对SQL语句的处理采用了类似的方法,首先会将SQL语句进行解析(Parse)形成一个树(Tree),在后续的如绑定、优化等处理过程都是对Tree的操作,而操作的方法是采用Rule,通过模式匹配,对不同类型的结点采用不同的操作。Spark的查询优化器是Catalyst,负责处理查询语句的解析、绑定、优化、物理计划等整个过程,Catalyst是与Spark解耦的一个独立库,是一个SQL的执行计划生成和优化框架,作为Spark SQL最核心的部分,其性能优劣将影响整体的性能。下面我们整体上来分析一下Spark SQL的运行架构。
1.TreeNode体系
Tree的具体操作是通过TreeNode(树结点)来实现的。TreeNode是Catalyst执行计划的数据结构,是一个树状结构,Logical Plans(逻辑执行计划)、Expressions(表达式)、Physi-cal Operators(物理算子)都可以使用TreeNode来表示,TreeNode具备一些scala collection的操作能力和树遍历能力。这棵树一直在内存里维护,不会dump到磁盘以某种格式的文件存在,且无论在Analyzer后的逻辑执行计划阶段还是optimizer后的逻辑执行计划阶段,树的修改是以替换已有结点的方式进行的。
TreeNode内部带一个children:Seq[BaseType]方法,可以返回一系列子结点。TreeNode提供UnaryNode,BinaryNode,LeafNode三种特性,在这里可以理解为TreeNode被细分成了三种类型的Node:其中UnaryNode表示一元结点,即只有一个子结点;BinaryNode表示二元结点,即有左右子结点的二叉结点;LeafNode表示叶子结点,没有子结点的结点。针对不同的结点,TreeNode提供了不同的操作方法,对UnaryNode可以进行Limit、Filter等操作;对BinaryNode可以进行Join、Union等操作;对于LeafNode主要进行用户命令类操作,如Set Command等。
对Tree的遍历操作,主要是借助各个TreeNode之间的关系,使用transformDown操作、transformUp操作将Rule应用到给定的树段,并对匹配结点实施转换的方法(使用的是Tree-Node结点中的transform方法),其中transformDown是默认的前序遍历;也可以使用trans-formChildrenDown、transformChildrenUp对一个给定的结点进行操作,通过迭代将Rule(规划)应用到该结点以及子结点。
TreeNode有两个子类继承体系,QueryPlan和Expression。QueryPlan下面的两个子类分别是LogicalPlan(逻辑执行计划)和SparkPlan(物理执行计划)。QueryPlan内部带有output:Seq[Attribute]、transformExpressionDown、transformExpressionUp等方法,它的主要子类体系是LogicalPlan,它在Catalyst优化器里有详细实现。LogicalPlan内部带一个reference:Set[Attrib-ute]方法,主要方法为resolve(name:String):Option[NamedeExpression],用于分析生成对应的NamedExpression。对于SparkPlan,即物理执行计划,需要用户在系统中自己实现(Spark-SQL项目中)。LogicalPlan本身也有许多具体子类,分为UnaryNode、BinaryNode、LeafNode三类,具体在org.apache.spark.sql.catalyst.plans.logical路径下。
Expression是表达式体系,指不需要执行引擎的计算,而可以直接计算或处理的结点,包括Cast操作、Projection操作、四则运算、逻辑操作符运算等。具体可以参考org.apache. spark.sql.catalyst.expressions包下的类。
2.Rules体系
Rule[TreeType<:TreeNode[_]]是一个抽象类,子类需要复写apply(plan:TreeType)方法来制定处理逻辑。Rule的定义可以在org.apache.spark.sql.catalyst.rules包下查看。对于Rule的具体实现是通过RuleExecutor完成的,凡是需要处理执行计划树(Analyze过程、Optimize过程、SparkStrategy过程),实施规则匹配和结点处理的,都需要继承RuleExecutor[TreeType]抽象类。
在RuleExecutor的实现子类(如Analyzer和Optimizer)中会定义Batch、Once和Fixed-Point这三个样例类的实例对象。其中每个Batch代表着一套规则,这样可以简便地、模块化地对Tree进行transform操作;Once和FixedPoint是配备的策略,可以通过策略的配置来对Tree进行一次操作或多次的迭代操作(如对某些Tree进行多次迭代操作的时候,达到FixedPoint迭代次数或达到前后两次的树结构没有变化才停止操作)。RuleExecutor内部提供了一个Seq[Batch]属性,里面定义的是该RuleExecutor的处理逻辑,具体的处理逻辑由具体Rule子类实现。最后,RuleExecutor的apply(plan:TreeType):TreeType方法会按照batch的顺序和batch内的Rules顺序,对传入的plan里的结点迭代处理。
对于Rule的使用拿个简单的例子做展示,在Analyzer过程中处理由解析器(SqlParser)生成的LogicPlan Tree的时候,就定义了多种Rule应用到LogicPlan Tree上(如图6-3所示)。
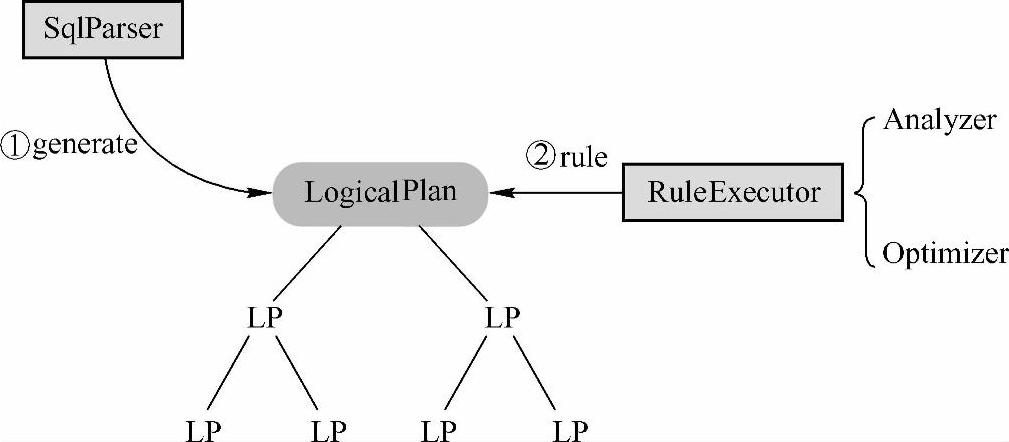
图6-3 SQL on Spark
具体在Rule Executor工作的过程,Analyzer过程中使用了自己定义的多个batch,如MultiInstanceRelations、Resolution、Check Analysis、AnalysisOperators;每个batch又由不同的rule构成,如Check Analysis由CheckResolution、CheckAggregation构成;每个rule又有自己相对应的处理函数;同时要注意的是,不同的rule使用次数是不同的:如MultiInstanceRela-tions这个batch中rule只应用了一次(Once),而AnalysisOperators这个batch中rule应用了多次(fixedPoint=FixedPoint(50),也就是说最多应用50次,除非前后迭代结果一致退出)。在整个sql语句的处理过程中,Tree和Rule相互配合,完成了解析、绑定(在SparkSQL中称为Analysis)、优化、物理计划等过程,最终生成可以执行的物理计划。(https://www.xing528.com)
3.Catalyst优化器
现在已经知道Catalyst是Spark SQL最重要的查询引擎,是Spark SQL最核心的部分。在介绍Catalyst之前,我们先看一下Spark SQL由哪些模块组成(参见图6-4所示的Spark 1.2.0的源码)。
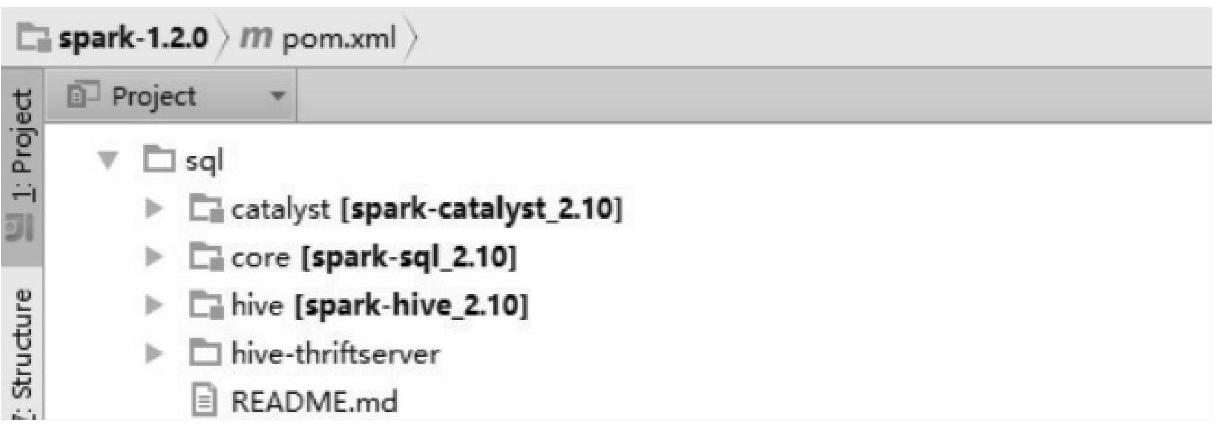
图6-4 Spark SQL源码中的四大模块
从图6-4中可以看出Spark SQL 1.2.0总体上由Catalyst、core、hive、hive-thriftserver四个模块组成,其中catalyst负责处理查询语句的整个处理过程,包括解析、绑定、优化、物理计划等;core负责处理数据的输入输出,从不同的数据源获取数据(如RDD、Parquet文件、JSON文件等),然后将查询结果输出成SchemaRDD;hive负责对hive处输入的数据进行处理;hive-thriftserver提供CLI和JDBC/ODBC接口。在这四个模块中,处于核心地位的就是Catalyst,下面可以通过Catalyst的架构图(如图6-5所示)来分析一下Catalyst的一些主要组件的功能以及SQL语句通过Catalyst进行查询的运行流程。
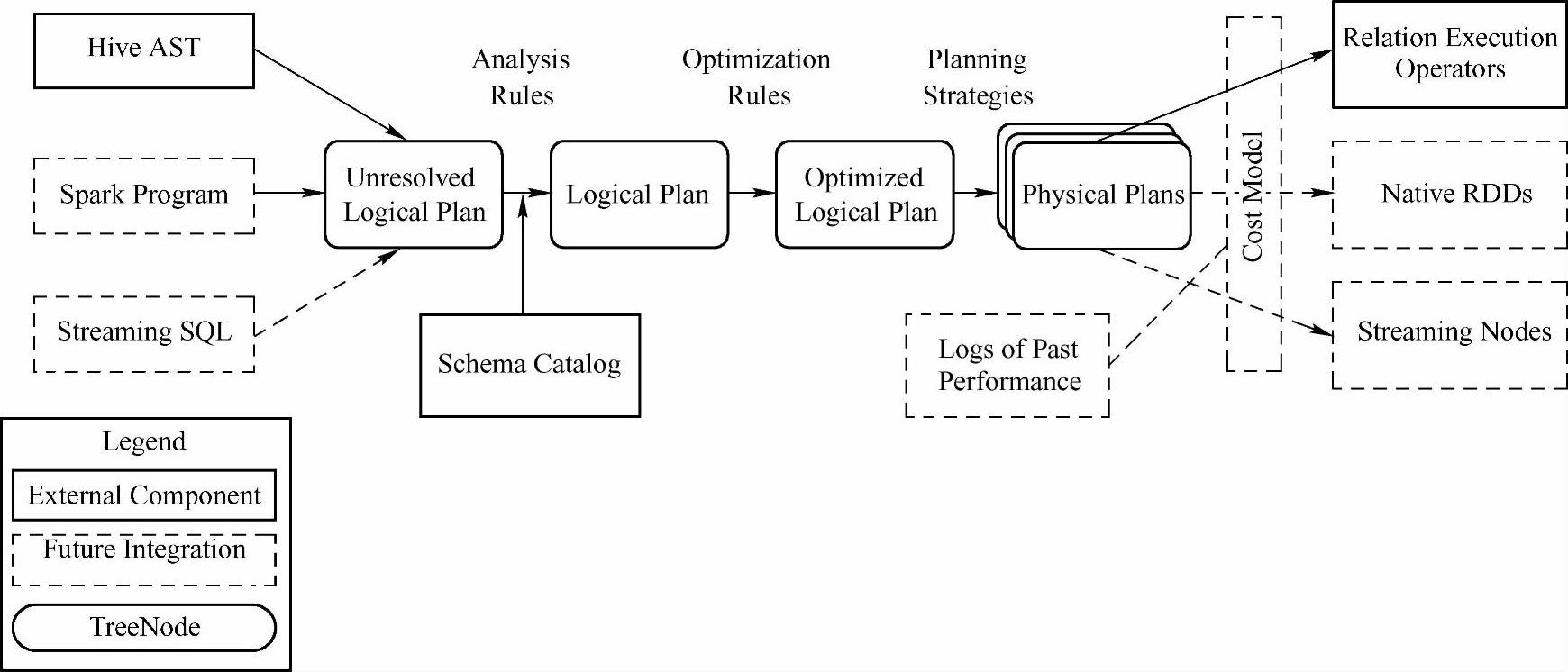
图6-5 Catalyst的架构图
从图6-5我们应该很容易地知道在Spark SQL中SQL语句查询时Catalyst的运行流程。步骤如下:
(1)将sql语句通过解析(SqlParse)生成Unresolved逻辑计划(包含UnresolvedRela-tion、UnresolvedFunction、UnresolvedAttribute),然后在不同阶段使用不同的Rule应用到这个逻辑计划上,通过转换完成各个组件的功能。对于命令,会生成一个叶子结点;对于SQL语句,由lexical的Scanner来扫描输入、分词、校验,如果符合语法就生成LogicalPlan语法树,不符合则会提示解析失败。
(2)Analyzer使用Analysis Rules,配合数据元数据(如Hive metastore、Schema cata-log),完善Unresolved LogicalPlan的属性而转换成Resolved LogicalPlan。具体流程是实例化一个SimpleAnalyzer,定义一些Batch,然后遍历这些Batch,在Rule Executor的环境下,执行Batch里面的Rules,每个Rule会对Unresolved Logical Plan进行Resolve,有些可能不会一次解析出,需要多次迭代,直到达到FixedPoint迭代次数或达到前后两次的树结构没变化才停止操作。比较常用的Rules有ResolveReferences、ResolveRelations、StarExpansion、Global-Aggregates、typeCoercionRules和EliminateAnalysisOperators。ResolveRelations、ResolveFunc-tions等调用了Catlog这个对象。Catlog对象里面维护着一个tableName、Logical Plan的Hash-Map结果。通过这个Catlog目录来寻找当前表的结构,从而从中解析出这个表的字段。
(3)Optimizer使用Optimization Rules,将Analyzer LogicalPlan的Logical Plan和Expression进行合并、列裁剪、过滤器下推等优化工作后生成Optimized LogicalPlan。对Logical Plan进行转换trans-form时采用先序遍历(pre-order),而对Expression transform的时候采用后序遍历(post-order)。
(4)Planner使用Planning Strategies,对optimized LogicalPlan进行转换(transform),生成可以执行的物理计划。
到这里,我们就对Spark SQL的运行架构做了一个整体的说明,在后面的章节会结合源码对Spark SQL的SQL查询执行流程做深度的分析。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。