



(一)研究样本选取
知识经济时代的到来为我国高新技术企业跨越式发展提供了宝贵的契机,其中东部地区作为我国主要经济发达地区之一,高新技术企业的知识管理能力和双元创新发展具有一定的引领作用和代表性,为了有效验证两者之间的理论关系假设,本次实证检验选取了长三角地区部分高新技术企业为样本。
(二)数据来源
鉴于相关统计年鉴和统计数据库没有专门的数据对本研究提供支持,因而本研究数据收集主要源于企业现场调研现场发放纸质问卷、辅以问卷星、电子邮件、电话以及QQ网络调研等方式,并确保纸质问卷与电子问卷内容完全一致。同时,为了保证研究数据来源的广泛性和准确性,调研对象覆盖基层、中层和高层管理者或技术骨干等。本次共发放问卷385份,回收有效问卷297份,回收有效率77.1%。
(三)样本有效性检验
1.信度检验
信度即可靠性,它是指采用同样的方法对同一对象重复测量时所得结果相一致的程度。从另一方面来说,信度就是指测量数据的可靠程度。信度指标多以相关系数表示,大致可分为三类:稳定系数(跨时间的一致性),等值系数(跨形式的一致性)和内在一致性系数(跨项目的一致性)。信度分析的方法主要有以下三种:
重测信度法。这一方法是用同样的问卷对同一组被调查者间隔一定时间重复施测,计算两次施测结果的相关系数。显然,重测信度属于稳定系数。重测信度法特别适用于事实式问卷,如性别、出生年月等在两次施测中不应有任何差异,大多数被调查者的兴趣、爱好、习惯等在短时间内也不会有十分明显的变化。如果没有突发事件导致被调查者的态度、意见突变,这种方法也适用于态度、意见式问卷。由于重测信度法需要对同一样本试测两次,被调查者容易受到各种事件、活动和他人的影响,而且间隔时间长短也有一定限制,因此,在实施中有一定困难。
复本信度法。即让同一组被调查者一次填答两份问卷复本,计算两个复本的相关系数。复本信度属于等值系数。复本信度法要求两个复本除表述方式不同外,在内容、格式、难度和对应题项的提问方向等方面要完全一致,而在实际调查中,很难使调查问卷达到这种要求,因此,采用这种方法者较少。
折半信度法。即将调查项目分为两半,计算两半得分的相关系数,进而估计整个量表的信度。折半信度属于内在一致性系数,测量的是两半题项得分间的一致性。这种方法一般不适用于事实式问卷(如年龄与性别无法相比),常用于态度、意见式问卷的信度分析。在问卷调查中,态度测量最常见的形式是Likert5级量表。进行折半信度分析时,如果量表中含有反意题项,应先将反意题项的得分作逆向处理,以保证各题项得分方向的一致性,然后将全部题项按奇偶或前后分为尽可能相等的两半,计算二者的相关系数(rhh,即半个量表的信度系数),最后用斯皮尔曼-布朗(Spearman-Brown)公式:
求出整个量表的信度系数(ru)。
α信度系数法。Cronbach α信度系数是目前最常用的信度系数,其公式为:
其中,K为量表中题项的总数,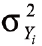 为第i题得分的题内方差,
为第i题得分的题内方差,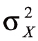 为全部题项总得分的方差。从公式中可以看出,α系数评价的是量表中各题项得分间的一致性,属于内在一致性系数。这种方法适用于态度、意见式问卷(量表)的信度分析。通常Cronbach α系数的值在0和1之间。如果α系数不超过0.6,一般认为内部一致信度不足;达到0.7-0.8时表示量表具有相当的信度,达0.8-0.9时说明量表信度非常好。
为全部题项总得分的方差。从公式中可以看出,α系数评价的是量表中各题项得分间的一致性,属于内在一致性系数。这种方法适用于态度、意见式问卷(量表)的信度分析。通常Cronbach α系数的值在0和1之间。如果α系数不超过0.6,一般认为内部一致信度不足;达到0.7-0.8时表示量表具有相当的信度,达0.8-0.9时说明量表信度非常好。
本文采用α信度系数法进行数据信度的校验,运行数据分析软件SPSS21.0计算出各变量的Cronbach α系数,结果如表3-1所示。
表3-1 信度校验
由表3-1可知,各变量的Cronbach α值均大于0.7,说明变量具有较好的信度。
2.效度检验(https://www.xing528.com)
效度(Validity)即有效性,它是指测量工具或手段能够准确测出所需测量的事物的程度。效度分为三种类型:内容效度、准则效度和结构效度。
内容效度。又称表面效度或逻辑效度,它是指所设计的题项能否代表所要测量的内容或主题。对内容效度常采用逻辑分析与统计分析相结合的方法进行评价。逻辑分析一般由研究者或专家评判所选题项是否“看上去”符合测量的目的和要求。统计分析主要采用单项与总和相关分析法获得评价结果,即计算每个题项得分与题项总分的相关系数,根据相关是否显著判断是否有效。若量表中有反意题项,应将其逆向处理后再计算总分。
准则效度。又称为效标效度或预测效度。准则效度分析是根据已经得到确定的某种理论,选择一种指标或测量工具作为准则(效标),分析问卷题项与准则的联系,若二者相关显著,或者问卷题项对准则的不同取值、特性表现出显著差异,则为有效的题项。评价准则效度的方法是相关分析或差异显著性检验。在调查问卷的效度分析中,选择一个合适的准则往往十分困难,使这种方法的应用受到一定限制。
结构效度。是指测量结果体现出来的某种结构与测值之间的对应程度,分为聚合效度和区分效度两类。聚合效度,又称收敛效度,强调那些应属于同一因子(指标)下的测量项,测量时确实落在同一因子下面。区分效度,强调本不应该在同一因子(指标)下的测量项,测量时确实不在同一因子下面。
一般认为,效度分析最理想的方法是利用因子分析测量量表或整个问卷的结构效度。在因子分析的结果中,用于评价聚合效度的主要指标有平均方差提取值(AVE)、综合可靠度(CR)和因子负荷,如果每个因子的AVE值大于0.5并且CR值大于0.7,则说明具有良好的聚合效度,同时一般还要求每个测量项对应的因子载荷系数(factor loading)值大于0.6;用于评价区分效度的主要指标有AVE根号值和相关系数,如果每个因子的AVE根号值均大于“该因子与其他因子的相关系数最大值”,此时则具有良好的区分效度。
本书采用验证性因子分析法(CFA)进行效度分析,结果如表3-2和3-3所示。
表3-2 验证性因子分析结果
表3-3 相关系数
续表
由表3-2可以看出,各测量项目的因子负荷均大于0.6,各变量的平均方差提取值(AVE)均大于50%,各变量的综合信度(CR)均大于0.7的标准值,因此变量具有较高的聚集效度。同时,由表3-3可知,除知识管理能力及其三个维度(知识获取能力、知识整合能力和知识创造能力)外,各变量的AVE平方根值均大于其所在行和列的相关系数,表明变量具有较好的区分效度。
3.共同方法偏差与多重共线性检验
共同方法偏差指的是因为同样的数据来源或评分者、同样的测量环境、项目语境以及项目本身特征所造成的预测变量与效标变量之间人为的共变。这种人为的共变对研究结果产生严重的混淆并对结论有潜在的误导,是一种系统误差。共同方法偏差在心理学、行为科学研究中特别是采用问卷法的研究中广泛存在。共同方法偏差的检验方法主要有两种。第一种:使用探索性因子分析(EFA)方法进行检验问题(也称作Harman单因子检验方法),即查看把所有量表项进行探索性因子分析时,如果只得出一个因子或者第一个因子的解释力(方差解释率)特别大,通常以50%为界,此时可判定存在同源方差(共同方法偏差),反之则说明没有共同方法偏差问题。第二种:使用验证性因子分析方法(CFA)进行分析;常见的做法为:将所有的测量项(即所有因子对应的测量量表题项)放在一个因子里面,然后进行分析,如果测量出来显示模型的拟合指标,比如卡方自由度比,RMSEA,RMR,CFI等无法达标,则说明模型拟合不佳,所有的测量项并不应该同属于一个因子,因而数据通过共同方法偏差检验,数据无共同方法偏差问题。
在进行线性回归分析时,容易出现自变量(解释变量)之间彼此相关的现象,称为多重共线性。适度的多重共线性不成问题,但当出现严重共线性问题时,会导致分析结果不稳定,出现回归系数的符号与实际情况完全相反的情况。本应该显著的自变量不显著,本不显著的自变量却呈现出显著性,这种情况下就需要消除多重共线性的影响。有多种方法可以检测多重共线性,较常使用的是回归分析中的VIF值,VIF值越大,多重共线性越严重。一般认为VIF大于10时,代表模型存在严重的共线性问题。
本书调研过程中,强调问卷匿名性,并针对回收问卷进行Harman单因子检验,结果显示第一个主成分解释的方差占总方差小于50%,说明不存在严重的同源偏差。
表3-3中,除了知识管理能力与它的三个维度之外,其他各变量之间的相关系数均低于0.7;下表3-4和表3-5显示,每个模型各变量之间的方差膨胀因子(VIF)的最大值为4.557,远低于临界值10,表明变量间不存在严重的多重共线性问题。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。