



通过下面这个案例展示Spark SQL的文本操作方式和DSL(Domain-Specific Language领域特定语言)的具体使用。
1.数据准备工作
(1)在进行SQL语句操作之前,我们把演示需要的数据上传到HDFS文件系统的data目录下,这里的数据是people.txt文件,里面的内容如下:

(2)启动HDFS,在Hadoop的$HOME/sbin目录下调用start-dfs命令。

(3)把/root/Downloads目录下的people.txt文件上传到HDFS的data目录下。
(4)在WebUI控制台查看HDFS文件系统中上传的文件,如图6-9所示。
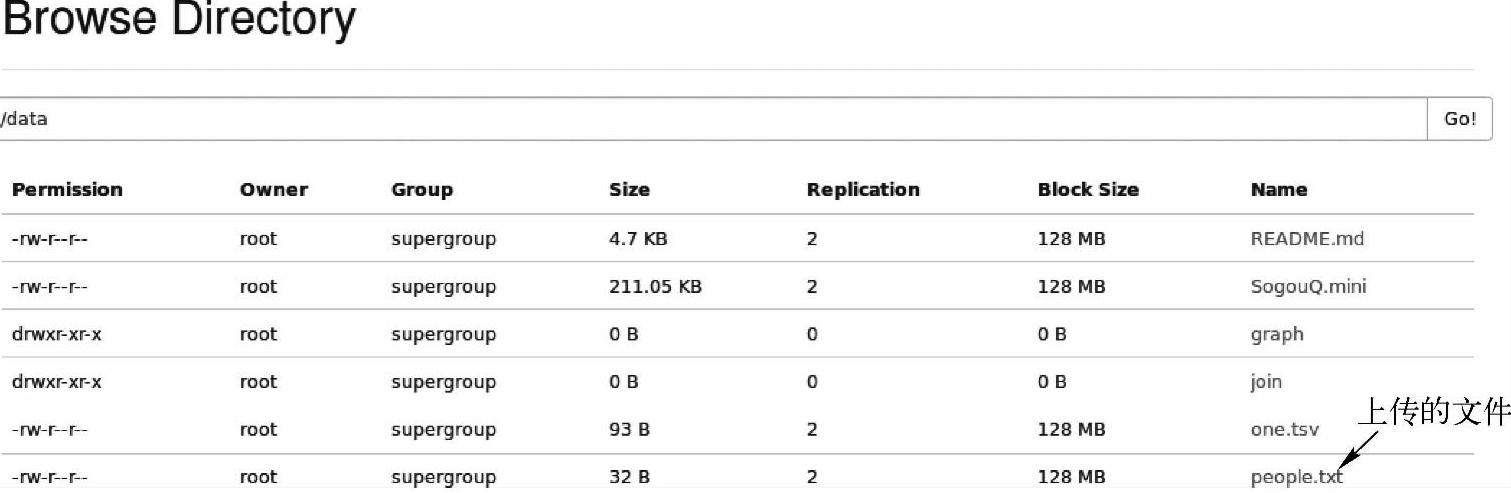
图6-9 上传people.txt文件到HDFS上
2.通过Spark SQL的SQL语句查询完整的代码
这里的语句查询演示采用的还是Spark官网提供的示例,具体代码如下

3.代码解析
(1)首先会初始化一个sqlContext,它是SQL语句查询的入口。
(2)importsqlContext._主要是为了把隐式函数createSchemaRDD引入上下文中,这样在后面就可以自动将生成的RDD隐式转换成SchemaRDD。(https://www.xing528.com)
(3)通过定义case class,可以反射推断出Schema,在RDD的transformation操作过程中使用case class可以通过隐式转换得到Person实例。
(4)people.registerAsTable("people")是把people注册成表,然后就可以在sqlContext下对表进行操作了。
(5)sqlContext.sql方法就是对表进行操作,最后调用collect方法触发作业的提交,并将sql方法的结果返回到driver。
4.代码运行情况
下面我们用spark-shell来运行上述代码,并查看运行情况。
(1)启动Spark Shell。
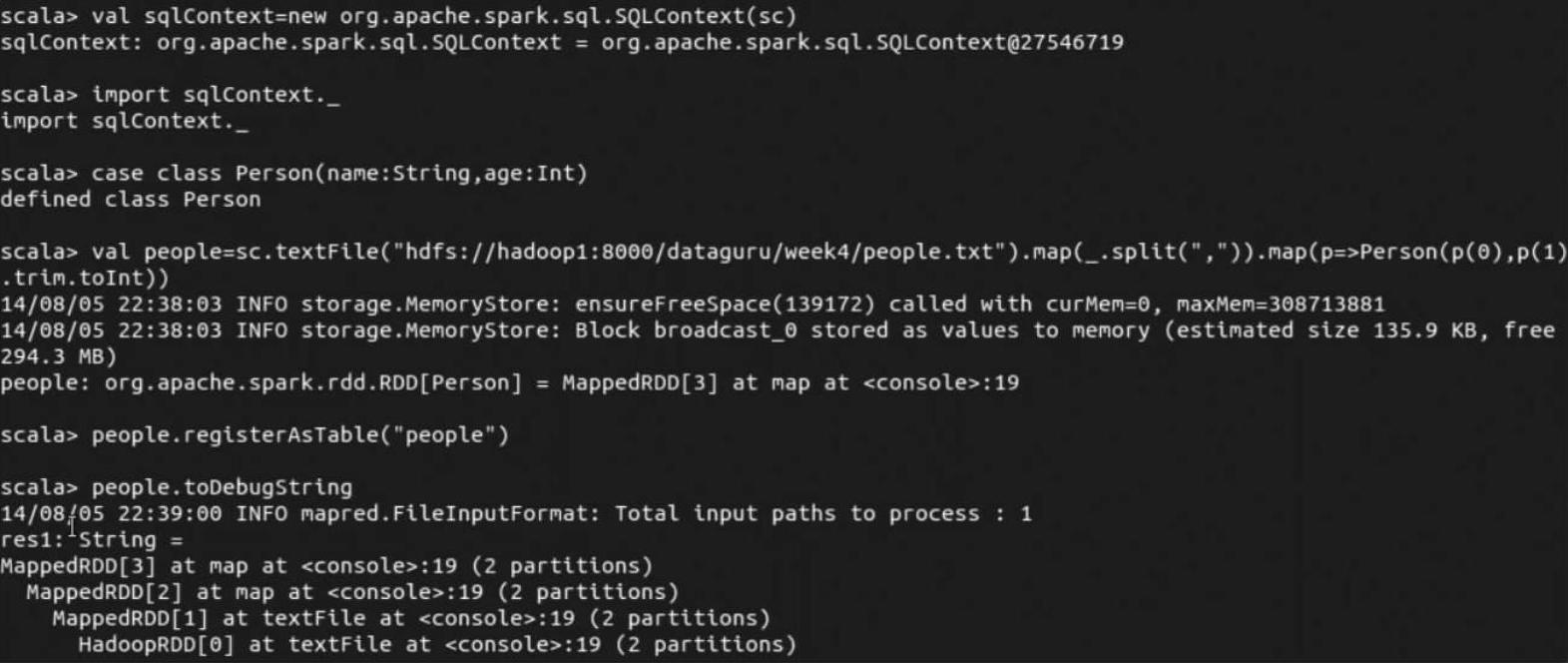
(2)把样例代码复制到spark-shell中执行,可以通过调用RDD的toDebugString方法来查看各个操作前后RDD之间的依赖关系。
(3)可以看到这时的teenagers已经是一个SchemaRDD了。
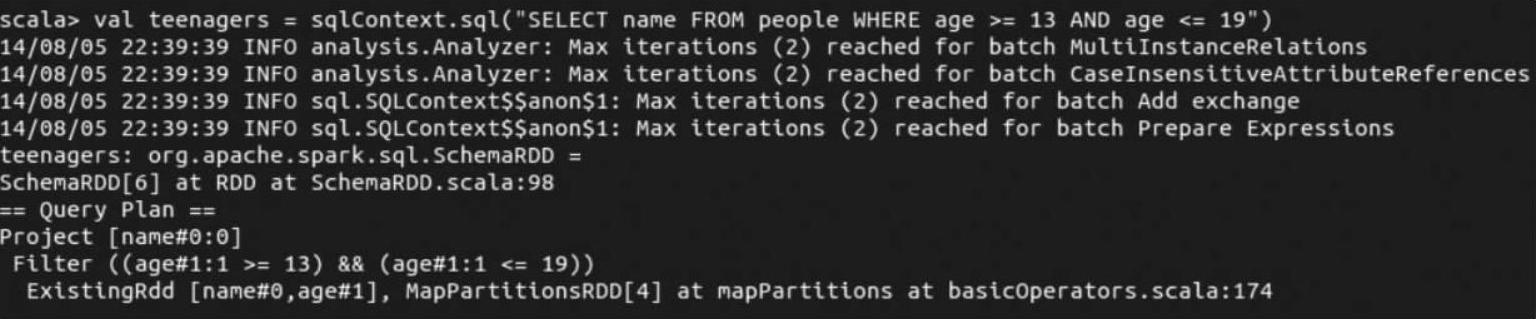
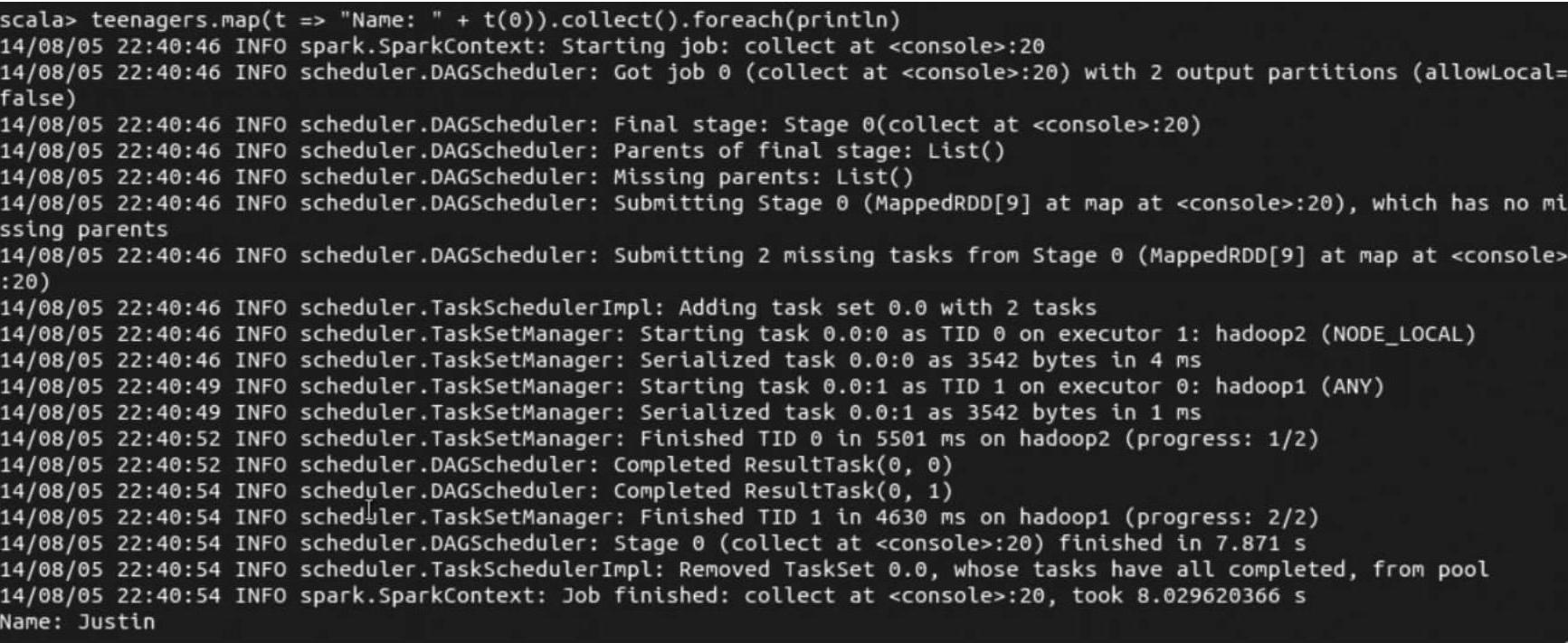
(4)通过collect这个action操作,触发了作业的提交,并将sql方法的结果返回到driver在最后我们可以看到运行结果。
(5)Spark SQL还为Spark应用开发人员提供了一系列的DSL(领域特定语言)。由于它以开发人员熟悉的SQL语义方式展现,提高了开发效率。下面我们简单演示一下它的使用,在spark-shell交互式界面输入:val teenagers_dsl=people.where(′age>=10).where(′age<=19).select(′name),然后输入:teenagers_dsl.map(t=>"name:"+t(0).collect().foreach(println)),然后Spark系统会直接执行。从运行结果中可以看到除了运行效率的差别,运行方式上和前面SQLContext提供的数据查询的API没什么区别。

免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。