



本节我们将讨论如何将第5.1节中介绍的RBM堆叠组成一个深度置信网络(Deep Belief Network,DBN),从而作为DNN预训练的基础模型。在进行细节的探究之前,我们首先要知道,由Hinton和Salakhutdinov在文献[163]提出的这种预训练过程是一种无监督的逐层预训练的通用技术,也就是说,不是只有RBM可以堆叠组成一个深度生成式(或判别式)网络,其他类型的网络也可以使用相同的方法来生成网络,比如Bengio等人在文献[28]中提出的自动编码器(autoencoder)的变形。
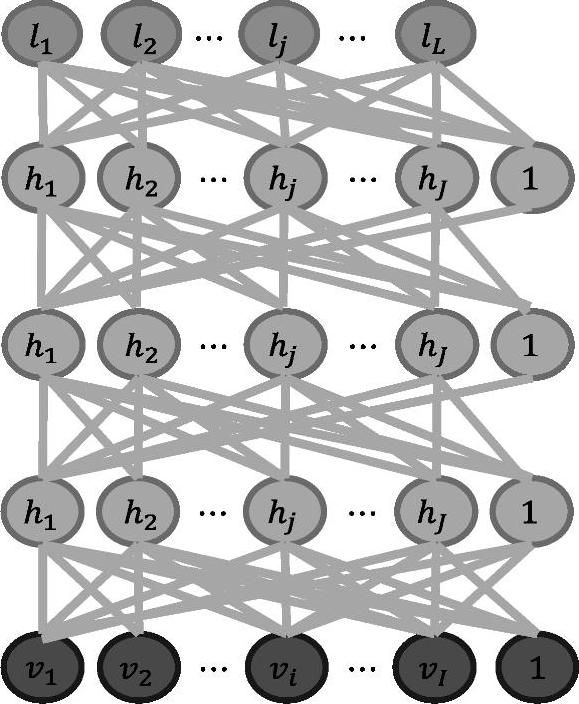
图5.2描述了一个逐层训练的例子,将一定数目的RBM堆叠组成一个DBN,然后从底向上逐层预训练。堆叠过程如下:训练一个高斯-伯努利RBM(对于语音应用使用的连续特征)或伯努利-伯努利RBM(对于正态分布或二项分布特征的应用,如黑白图像或编码后的文本)后,将隐单元的激活概率(activation probabilities)作为下一层伯努利-伯努利RBM的输入数据。第二层伯努利-伯努利RBM的激活概率作为第三层伯努利-伯努利RBM的可见输入数据,以后各层以此类推。关于这种有效的逐层贪婪学习策略的理论依据由文献[163]给出。已经表明,上述的堆叠过程提高了在构造模型下训练数据的似然概率的变分下限。也就是说,上述的贪婪过程达到了近似的最大似然学习。这个学习过程是无监督的,所以不需要标签信息。
当应用到分类任务时,生成式预训练可以和其他算法结合使用,典型的是判别式方法,它通过有效地调整所有权值来改善网络的性能。判别式精调(fine-tune)通常是在现有网络的最后一层上再增加一层节点,用来表示想要的输出或者训练数据提供的标签,它与标准的前馈神经网络(feed-forward neural network)一样,可以使用反向传播算法(back-propagation algorithm)来调整或精调网络的权值。DNN最后一层即标签层的内容,根据不同的任务和应用来确定。对于语音识别任务,如图5.2所示,最顶层节点“l1,l2,…,lj,…lL”可以表示音节(syllables)、音素(phones)、子音素(sub-phones)、音素状态(phones states)或者其他语音单元,这些单元都是基于HMM的语音识别系统中常见的。
上述生成式预训练应用在音素和语音识别中,要比随机初始化网络的效果要好,在第7章将会进行详细地讨论。研究也已经表明了其他种类的预训练策略的有效性。比如,在执行逐层贪婪训练时,可以在每一层的生成损失函数中增加一项(附加)判别项。如果不使用生成式预训练,只使用随机梯度下降方法来对随机初始化DNN进行判别式训练,那么结果表明,当非常仔细地选取初始权值并且谨慎地选择适合于随机梯度下降的“迷你批量”(mini-batch)的大小(例如:随着训练轮数增加大小),也将会获得很好的效果。“迷你批量”用于在收敛速度和噪声梯度之间进行折中。同时,在建立“迷你批量”时,对数据进行充分的随机化也是至关重要的。另外,很重要的一个发现是:从一个只含有一层隐层的浅层神经网络(shallow neural network)开始学习一个DNN是非常有效的。当这种方法用于训练区分式模型时(使用提前结束训练的策略以防止过拟合的出现),在第一个隐层和标签的softmax输出层之间插入第二个隐层,然后对扩展后的网络进行判别式训练,重复这个过程,直到隐层的层数达到要求,最后对整个网络应用反向传播来精调网络的权值。这种判别式预训练在实践中[324,419]取得了比较好的效果,特别是在有大量的训练数据的情况下效果更好。当训练数据不断增多时,即使不使用上述预训练,一些经过特别设计的随机初始化方法也能够取得很好的效果。
 (https://www.xing528.com)
(https://www.xing528.com)
图5.2 DBN-DNN结构
总之,无论是在大数据量还是小数据量的情况下,基于堆叠RBM的DBN预训练已经证明非常有效。另外,预训练的方法不是仅仅只有RBM和DBN方法,如除噪自动编码器(denoising autoencoders)也可以用来有效地估计数据的分布[30]。和RBM一样,除噪自动编码器也是一种利用采样的生成式模型。而与RBM不同的是,在训练过程中,我们可以获得目标函数梯度的无偏估计,而不再需要马尔可夫链蒙特卡罗(Markov Chain Monte Carlo,MCMC)或者变分估计。因此,可以像堆叠RBM预训练一样,首先逐层预训练去噪自动编码机,然后逐层堆叠,从而实现有效地逐层预训练。
另外,在许多深度学习的论文中,我们可以找到逐层预训练的一个通用框架,例如文献[2]的第二节,将RBM作为一种单层组成单元的特例进行了讨论。更普遍的预训练框架包括RBM/DBN以及其他无监督特征提取器,同时也包括了如何进行特征表示的无监督预训练,即在无监督预训练特征之后,单独训练一个分类器[215,216,217]。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。