



1.距离匹配法介绍
距离匹配法计算原理如下,首先按式(8-11)计算待测样本的新光谱。其中,xi为待预测的样本光谱;x-c为已知类别样本集的中心光谱;xcstd为已知类别样本集的准偏差光谱:

然后计算新光谱xinew中超过距离匹配限值的波长点所占的百分比,即该待测样本与已知类别的匹配值。距离匹配方法的匹配值范围是0~100,0表示最匹配。若有多个类别,则根据匹配值大小确定待测样本所属的最终类别。本实验采用TQAnalyst通用光谱分析软件进行距离匹配识别,距离匹配限值设定为5。
2.样品制备
从超市购买不同品牌(金龙鱼、福临门、鲁花等)、不同种类(大豆油、玉米油、橄榄油、葵花籽油等)纯食用油样本23份,调和食用油样本4份(金鼎调和油、金龙鱼橄榄调和油、金龙鱼调和油和鲁花调和油)。
从农贸市场购买的散装油,常温下色泽、状态与普通大豆油无异,无明显气味。且该样本的拉曼光谱与上述购买的食用油光谱相似。采用冰箱冷藏1~2h后,出现明显的白色凝固状。出现上述现象是由于该散装油中可能掺杂了棕榈油,或是由于掺杂了动物油脂所导致的,因此通过冷冻法可简易判断为问题油。以问题油为掺伪原料,分别制备掺伪样本。试验设计分两步走:一是制备简单背景下掺伪样本识别的可行性;二是模拟真实的掺伪情况,在复杂背景下制备掺伪样本。
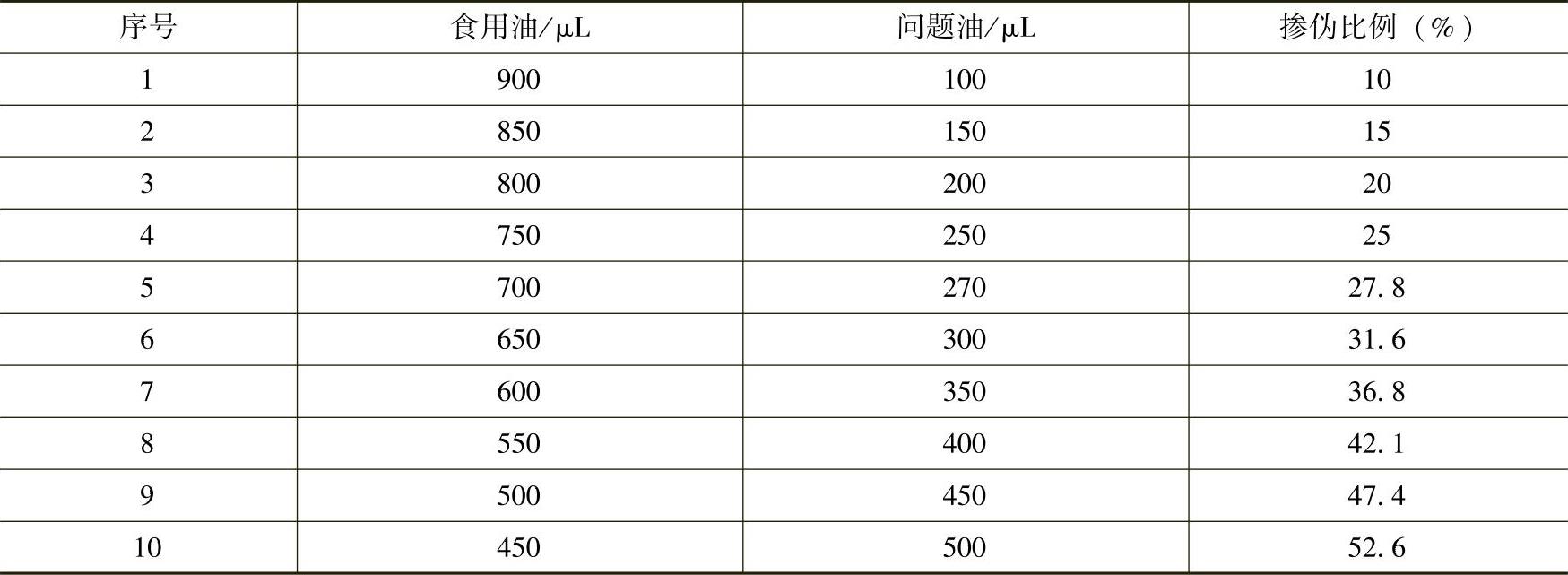
单一背景掺伪样本:以大豆油为背景制备样本33份,以玉米油为背景制备样本32份,共计65份掺伪样本。样本分布见表8-6。
表8-6 单一背景掺伪样本信息分布

复杂背景掺伪样本:以市售的金鼎调和油、金龙鱼橄榄调和油、金龙鱼调和油、鲁花调和油为背景各制备掺伪样本10份,共计40份。掺伪样本配置比例见表8-7。与表8-6中的掺伪比例相比,复杂背景下的掺伪样本的掺伪量明显下降,这也更符合实际遇到的食用油掺伪情况。
表8-7 复杂背景掺伪样本配制比例表
3.光谱采集
采用Thermo-fisher公司DXR激光显微拉曼光谱仪。光谱仪参数如下:780nm激光光源;奥林巴斯公司BX51研究级显微镜,10X目镜聚焦;拉曼位移范围为50~3300cm-1。采用金属制容器装样。每次测量前均用石油醚分析纯清洗金属质容器,避免样品间交叉污染。
样本集由23个纯食用油真实样本和65个单一背景的掺伪样本构成。拉曼光谱图一般都存在噪声和基线漂移等问题,因此光谱预处理在拉曼光谱分析中通常是有效和必要的。导数处理既可以消除基线偏移,还可以起到一定的放大和分离重叠信息的作用,但需要注意的是,在对光谱数据作微分处理时,由于噪声信号也被放大,因此通常在微分之前需要对光谱数据作平滑处理。本实验采用Norris Derivative滤波平滑方法和一阶导净化谱图,并采用了样条校正法进一步进行了基线校正。结果如图8-26所示,与原始谱图相比,处理后的光谱图谱峰更为清晰尖锐,且出现了更多的特征峰信息。
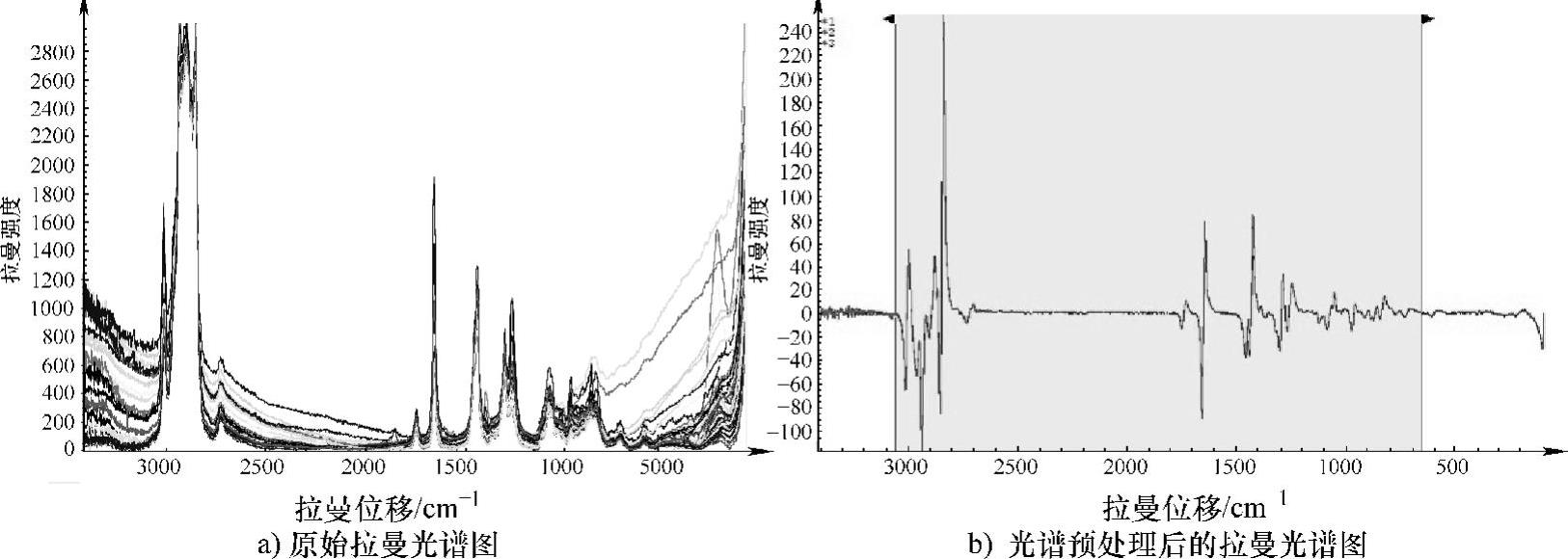
图8-26 光谱预处理
4.简单掺伪背景下的模型建立与测试(https://www.xing528.com)
(1)建模分析
按样本数3∶1随机划分建模集和校验集。建模集样本有67个(其中包含51个掺伪样本和16个纯食用油样本);校验集样本有21个(其中包含14个掺伪样本和7个纯食用油样本)。
将合格食用植物油样本设定为真样本,问题油掺杂样本设定为伪样本。采用距离匹配法验证建模集样本的归属,以待测样本与问题油样本集中心的距离匹配值为横坐标,待测样本与合格食用油样本集中心的距离匹配值为纵坐标构建待测样本的分布空间,如图8-27所示。其中,□代表了伪样本,△代表了真样本。只需比较每个样本的横坐标值(x)与纵坐标值(y)的大小即可判断出样本的归属,若x>y,即伪样本,反之为真样本。从图8-27中可以看出,真伪样本的识别率均达到了100%。
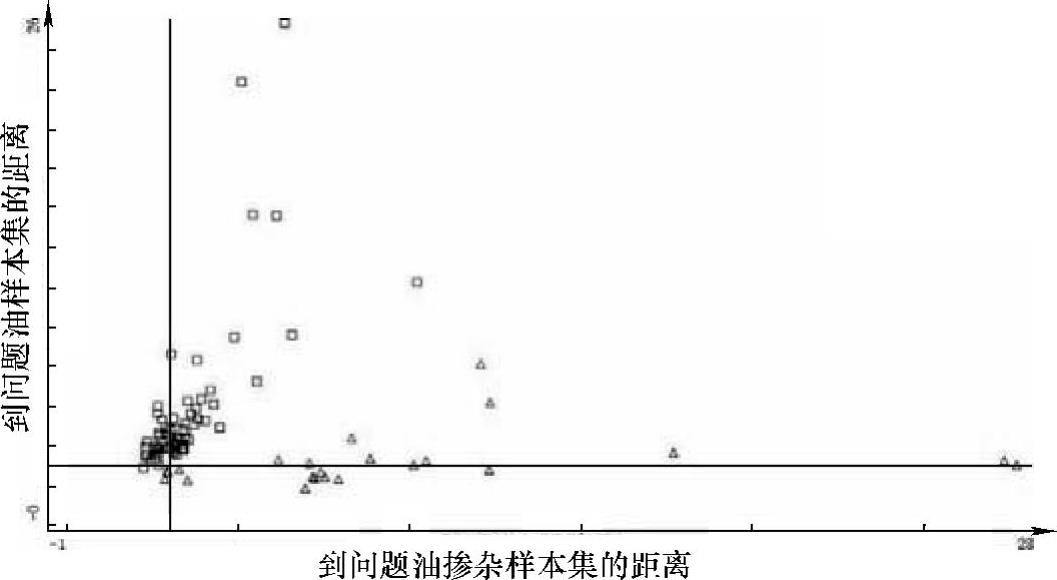
图8-27 建模集样本的距离匹配值分布图
(2)校验测试
校验集样本的预测结果见表8-8。其中1为掺伪样本,即伪样本,2为合格食用油样本,即真样本。真样本测试集中仅有一个样本被误判,真样本的识别率为85.7%。伪样本测试集中也仅有一个样本被误判,伪样本的识别率为94.1%,样本的总体识别率为91.7%。从试验结果看,采用拉曼光谱以及距离匹配法识别单一背景的掺伪样本具有较好的可行性。
表8-8 基于距离匹配法的掺伪定性识别结果
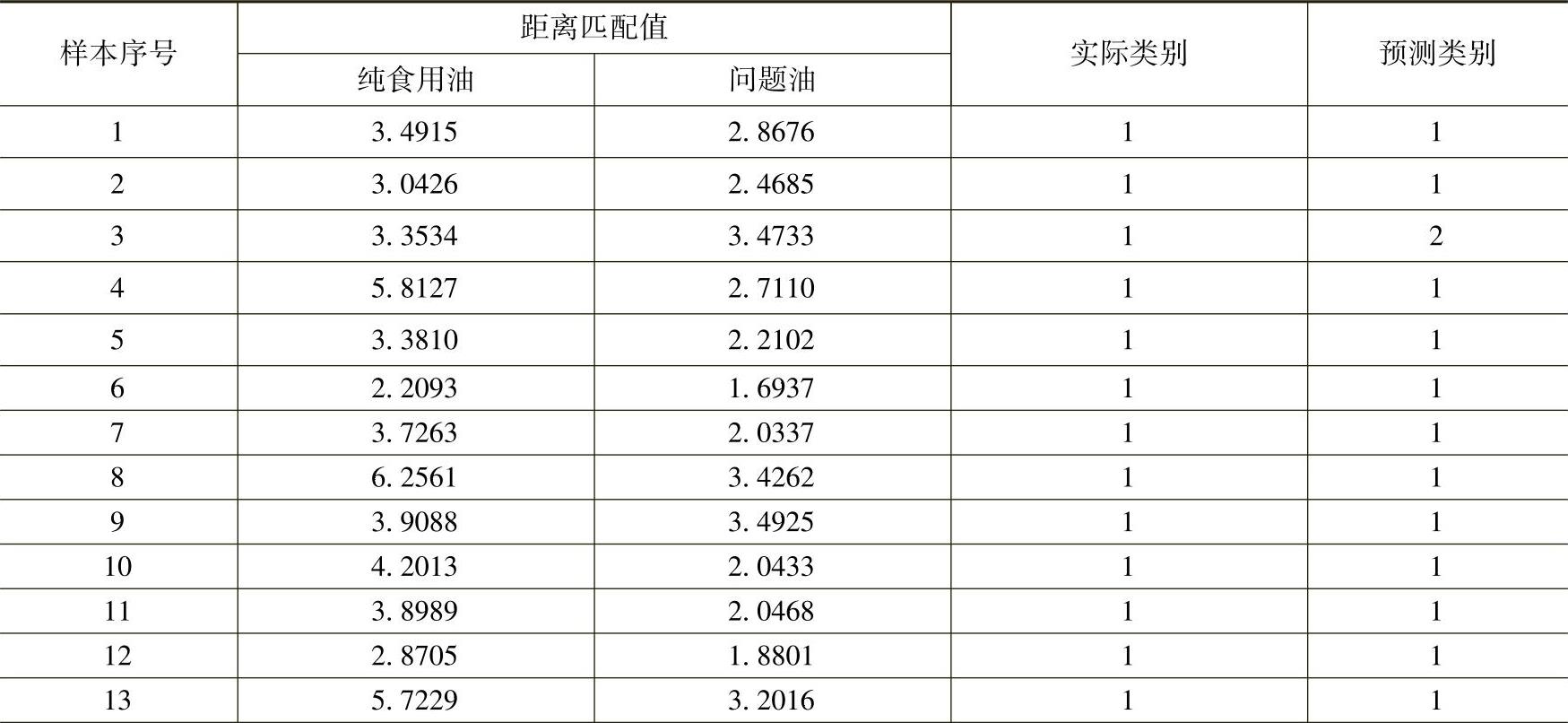
(续)
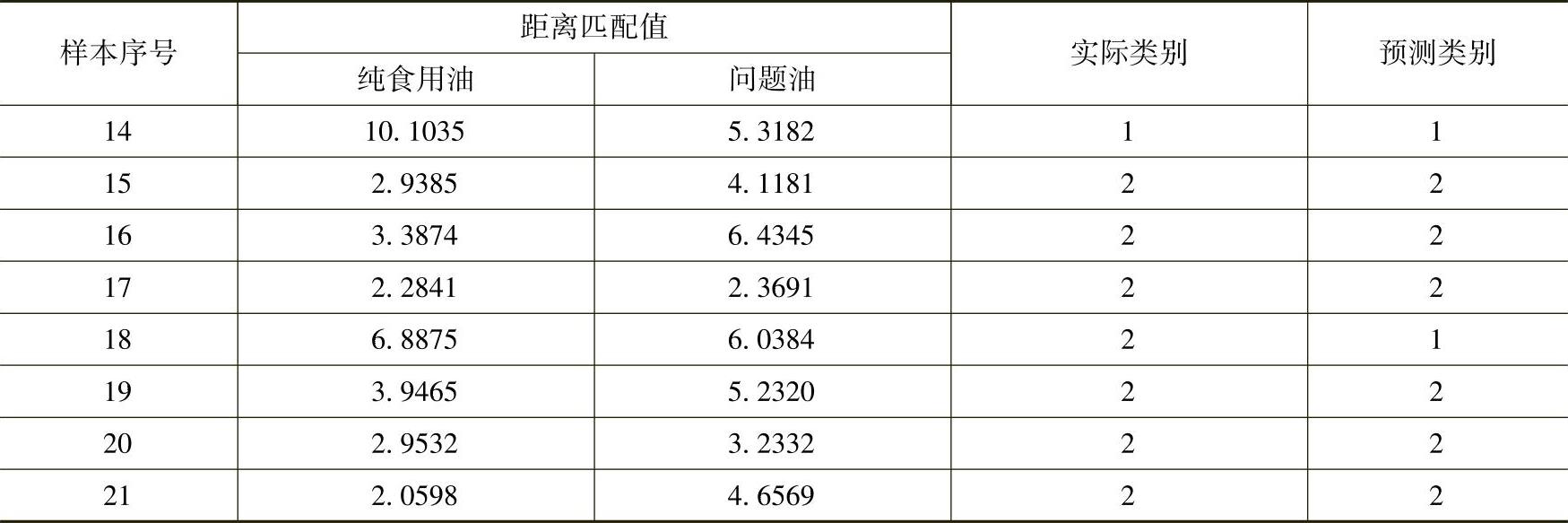
注:1为掺伪样本,2为纯食用油样本。
5.复杂掺伪背景下的模型建立与测试
样本集由27个食用油真实样本(23个纯食用油样本及4个作为背景的调和油样本)和40个复杂背景的掺伪样本构成。建模集和校验集个数约按3︰1划分,其中,随机选择以金鼎调和油为背景的掺伪样本3个、以金龙鱼橄榄调和油为背景的掺伪样本2个、以金龙鱼调和油为背景的掺伪样本3个、以鲁花调和油为背景的掺伪样本2个以及合格食用油样本8个,共计18个样本作为校验集,剩余49个样本作为建模集。
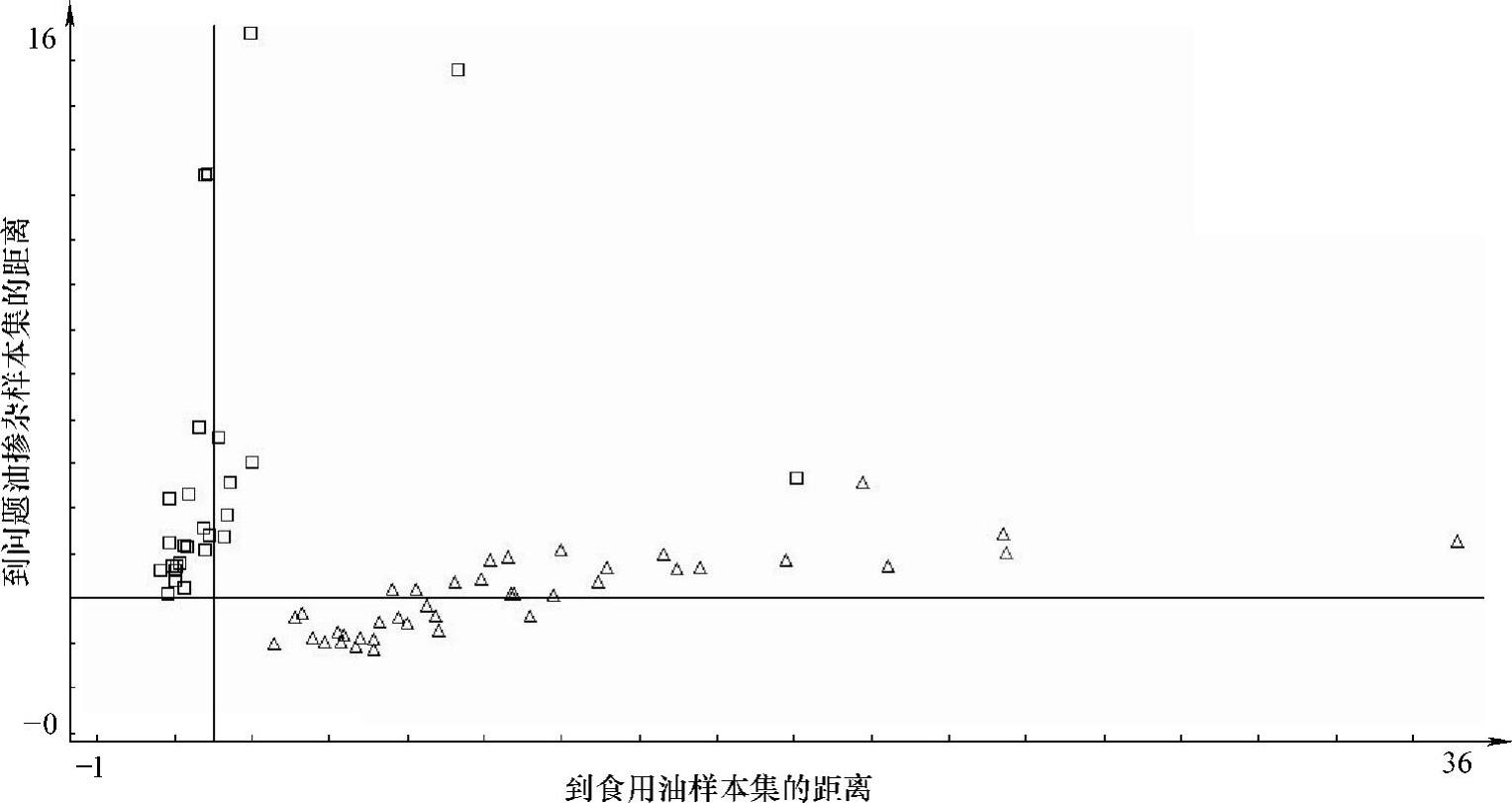
图8-28 复杂背景掺伪情况下的样本距离匹配图
参照上述分析步骤进行全谱建模和校验分析,比较了多种光谱平滑和求导(一阶和二阶)组合方法,最终确定Norris Derivative滤波平滑方法和一阶导净化谱图,并采用了样条校正法进一步进行了基线校正。在此基础上,采用全谱建模,伪样本识别率达到了100%(10/10),而真样本中始终有两个样本被误判,真样本的识别率为75%(2/8),样本的总体识别率为88.9%(16/18)。
试验进一步尝试选取了多个含有特征峰的波段进行建模比较,最终确定了726.44~1812.16cm-1建模。建模和校验结果如图8-28所示。其中,□代表了伪样本,△代表了真样本。根据试验结果,蓝色所示建模集样本均能被正确识别,而紫色所示的校验集样本中,伪样本识别率达到了100%(10/10),而真样本识别率中有一个样本被误判,则真样本的识别率为87.5%(7/8)。样本的总体识别率为94.4%(17/18)。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。