



13.3.3.1 实验数据简介
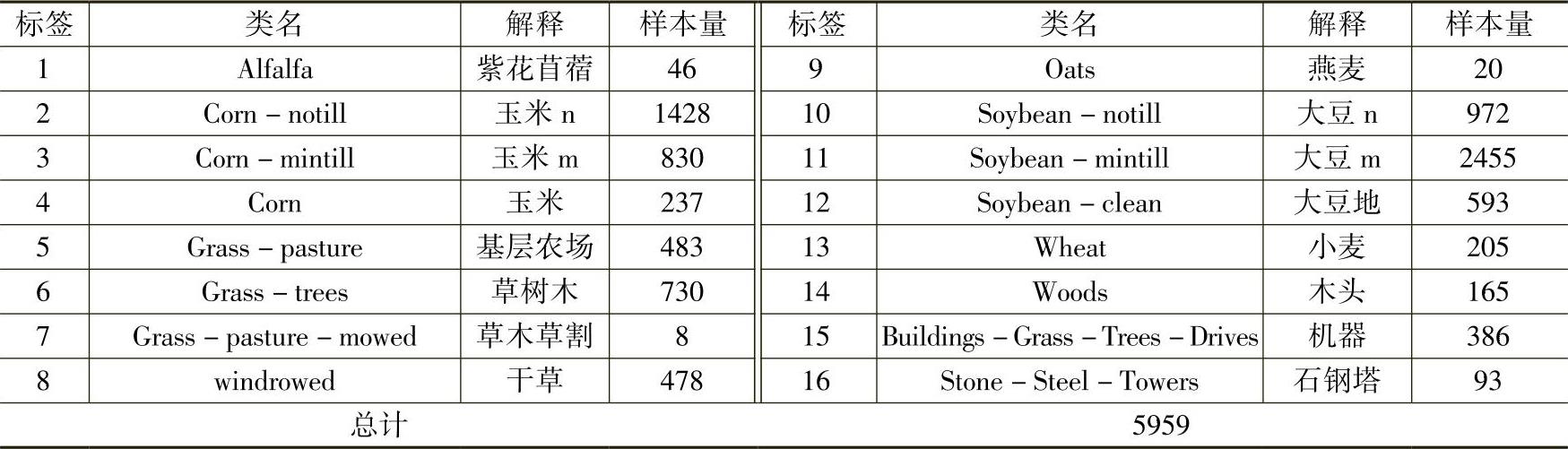
本实验用到的高光谱数据库为Indian Pines。此数据库场景的拍摄内容为位于美国的印第安纳州西北部的Indian Pines测试区域,地表覆盖类型混合了林地、道路、农田、房屋建筑等。标记的样本分布不均衡,并且部分类别样本较少。各种农作物基本都处于生长初期,对地表的林冠覆盖程度只有5%,裸地和作物残渣对植被像元分类影响明显。Indian Pines图像大小为145×145像素,波长范围为0.4~2.5μm,220个波段,空间分辨率为20m,去除坏波段和水体吸收的波段,试验中使用200个波段,如图13-23所示:图13-23a表示Indian Pines数据灰度图像;图13-23b表示其对应的地面真值。此场景中主要内容为自然制备,其中60%以上为农业场景,30%以上为森林场景和其他常年自然植被,共包含地物信息16类,见表13-1。
13.3.3.2 建立CNN模型
1.数据预处理
Indian Pines共10249个样本,首先选出标签不为0的数据,然后将数据按照各属性归一化到0~1。样本维度为200,将其转变为二维数组20×10,随机选取80%作为训练,20%作为测试。标签1~16采用one-hot编码,例如1(1000000000000000)、2(0100000000000000),以此类推。

图13-23 Indian Pines数据及地面真值
表13-1 Indian Pines数据含有的类别及样本数量
 (https://www.xing528.com)
(https://www.xing528.com)
2.CNN模型的参数设置
CNN模型的参数选取见表13-2。
表13-2 CNN模型参数选取

3.实验结果
按照表13-2所设置的参数,CNN模型对Indian Pines进行实验,分类的准确率为91.4%。
4.模型对比
采用SVM模型做对比,损失函数采用e-SVR,核函数中的degree设置(针对多项式核函数)设置为2,n-fold交互检验模式中的n设置为2,其余参数均为默认参数。实验分类准确率为89.5%。通过对比可以看出,CNN模型的分类准确率高,所以CNN模型更好。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。