



Deb和他的学生们于2002年提出了一种基于精英策略的非劣分类遗传算法(NSGA-Ⅱ)。在大多数方面,该算法与初始的NSGA没有太多的相似性。他们为了强调它的起源以及起源的地位而采用了NSGA-Ⅱ这个名字。在NS-GA-Ⅱ中,首先用种群规模大小为N的父代种群Pt产生种群规模大小为N的子代种群Qt,并将两个种群合并在一起形成大小为2N的种群Rt=Pt∪Qt。然后使用非劣分类排序将整个种群Rt分等级。尽管与只对Qt进行非劣分类相比,它需要做更多的工作,但是它允许在整个子代和父代进行全局的非劣检验。一旦结束非劣分类,新种群Pt+1由N个不同的非劣等级的个体填充。填充过程从最高非劣等级开始,接着是第二非劣等级,依此类推。NSGA-II的算法框图如图4-2所示。
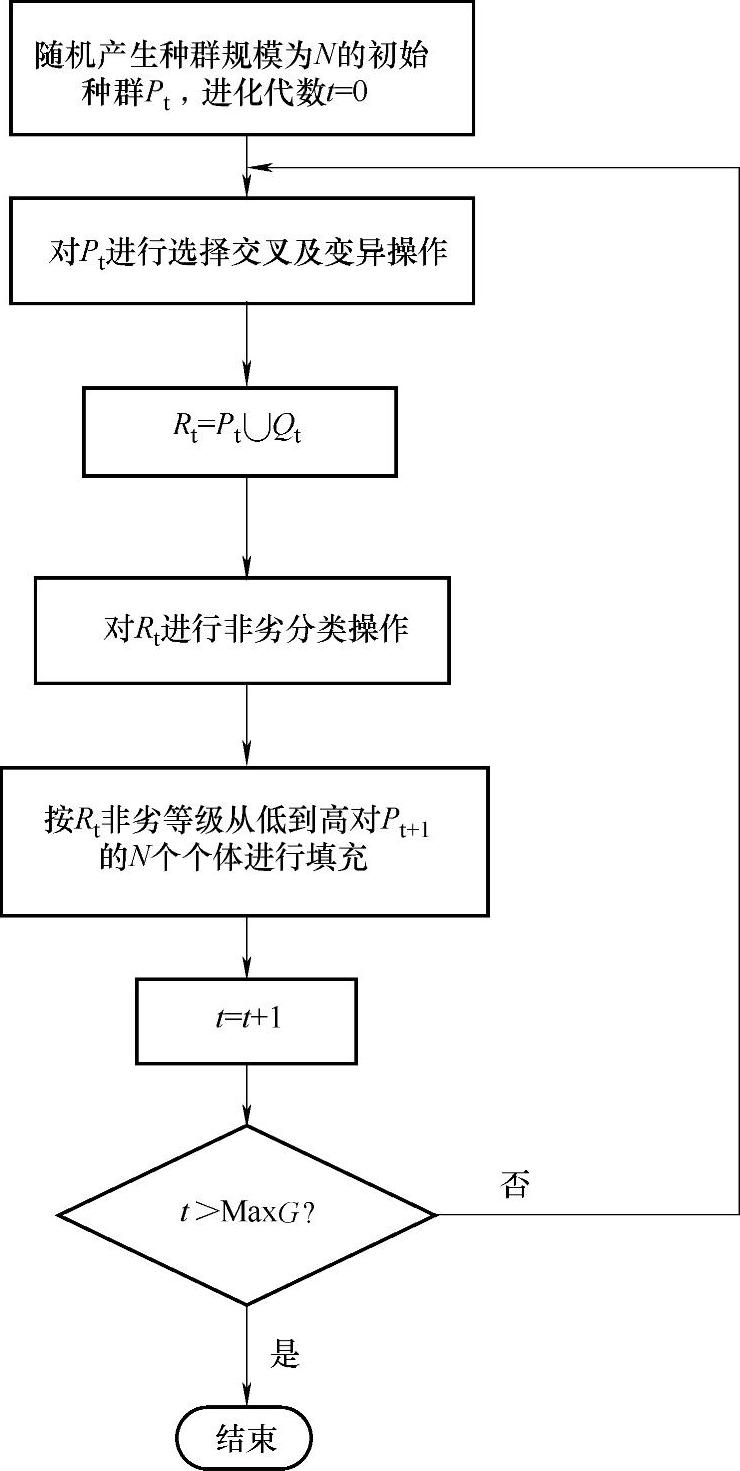
图4-2 NSGA-Ⅱ算法框图
由于整个种群Rt的种群大小为2N,新种群Pt+1的N个位置不能容纳所有的非劣等级。当考虑被允许的最后一个等级中的解时,该非劣等级可能存在比新种群剩下位置更多的个体。在这种情况下,使用密度估计的方法从最后一等级选择位于该等级较稀疏区域的个体填充满新种群。这里着重要指出的是Rt的非劣分类过程和种群Pt+1的填充过程可以一起执行。这样,对每一个非劣等级先看它的大小,看它是否能被新种群容纳,如果不能,那么就不必再进行非劣分类,这样能减少该算法的运行时间。首先,建立一个随机的种群规模大小为N的初始种群P0并初始化进化代数计数器t=0。然后对种群Pt进行遗传操作产生子代种群Qt,将Pt和Qt合并产生Rt,并对具有2N规模的种群Rt进行非劣分类操作,并生成下一代种群Pt+1(流程见图4-3),进化代数计数器t加1并判断t是否大于最大进化代数MaxGen。如果是,那么该算法结束;否则,继续进化。如此循环,直到进化到指定的最大进化代数。
在图4-3中,首先获取Rt中的第一非劣等级个体集,判断并决定该非劣等级能否全被新种群容纳。如果能,将该非劣等级的所有个体填充到新种群中,继续判断下一非劣等级能否全被新种群容纳。如此反复,直到不能容纳该非劣等级的所有个体,假设为第i+1级。对最后不能被完全容纳的非劣组中的个体求其拥挤距离,并选择分布最广的N-Pt+1个个体填充新种群。
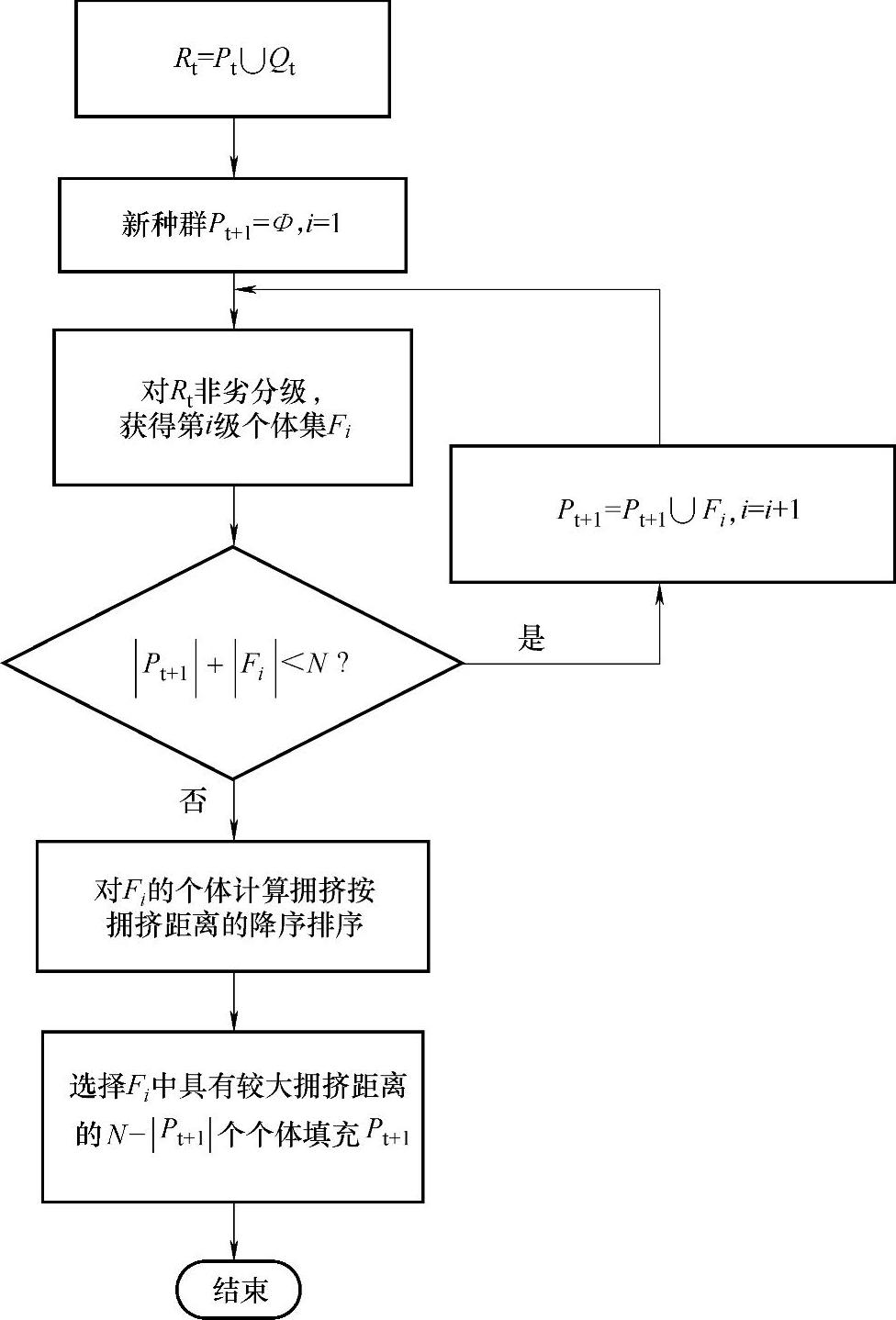
图4-3 由父代和子代种群生成下一代新种群框图
下面介绍该算法中所使用的快速非劣分类方法、拥挤距离尺度、拥挤选择算子,以及基于实数编码的SBX交叉和变异算子。
1.快速非劣分类方法
为了对具有N个个体的种群按照Pareto等级进行分类,每个个体都要与种群中的所有个体进行比较来决定它是否被支配。对于每个个体来说比较的时间复杂度是O(MN),其中M是目标数。持续这个过程,直到从所有个体中找到处于第一非劣等级中的个体,总的时间复杂度是O(MN2)。在这一步,第一非劣等级中的所有个体被寻找到,为了找到随后各等级中的个体,重复上面过程。可以断定,在最坏情况下(每个等级的非劣解集中仅有一个解),这种算法如不采用保留策略,时间复杂度为O(MN3),而NSGA-Ⅱ中所采用的非支配分类方法所需处理时间最大为O(MN2)。下面将介绍这种方法(假设p,q分别表示种群的个体):
首先,对于每一个个体计算两个量:①np,支配p的个体的个数;②Sp,p支配的一组解。这两个量的计算时间为O(MN2)。随后,将所有ni=0的解放入解F1中。对于当前解集F1中的p,观察它的Sp集,将Sp集中每个q的nq减1,完成上述步骤后,如果支配q的解个数nq=0,这也就意味着q是仅次于第一等级的个体。此时把q放入F2中,重复上述过程,最终将所有的个体按照Pareto等级分为多个等级。其中F1中的解是最好的,也就是前面所提到的精英解集,它只支配解而不被其他任何解支配;F2中的个体只被F1中的解支配,不被其他解支配,依次类推。每次迭代时间为O(N),由于最多有N个解集,那么最坏情况下这个循环的时间为O(N2)。总时间复杂度为O(MN2)+O(N2)或O(MN2)。
2.拥挤距离
种群中某个个体i的拥挤距离di是一个在个体i周围不被种群中任何其他的个体所占有的搜索空间的度量。为了估计种群中某个个体i周围个体的密度,取个体i沿着i所在的Pareto Front Line的两边邻近的两个个体(i-1),(i+1)的M个目标的水平距离之和来刻画数量di,称为拥挤距离。拥挤距离的求解如图4-4。下面给出拥挤距离的求解算法:
第一步:对该层(等Pareto排序值)的所有点排序,排序结果如图4-4所示。
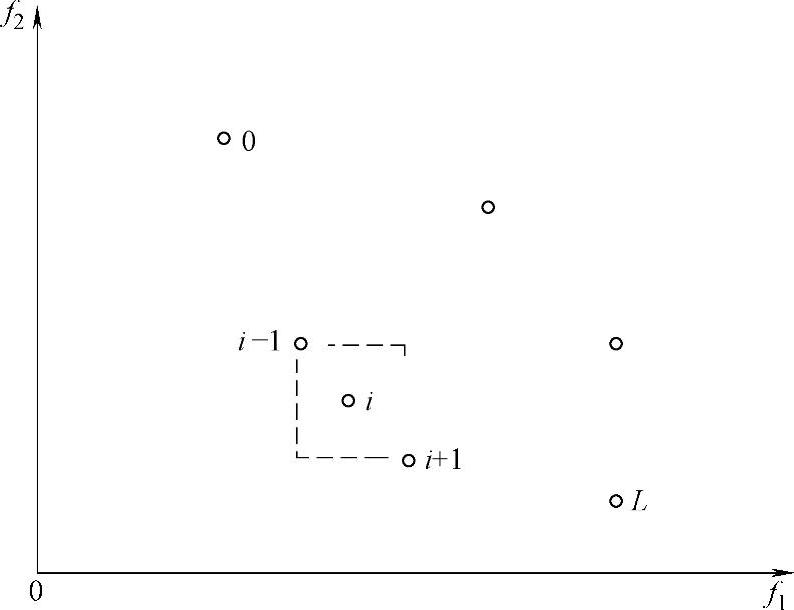
图4-4 拥挤距离计算示意图
对于两个目标函数值的而言,先选择其中一个目标函数,然后按照该目标函数值从小到大的顺序进行排列,按式(4-16)计算距离,进而可以用下面的第三步计算拥挤距离,直到累积完所有的目标函数。
第二步:每个点的拥挤距离di初始化为0。
第三步:设fm为目标函数,m=0,1,2,…,M。设d0=dL=∞,端点设置成无穷大保证了端点一定会被选择到下一代中,并且对其他所有个体i=1,2,…,L-1分配:

式中,di表示第i个个体的拥挤距离;fim+1和fim-1分别表示第i+1、i-1个个体的第m个目标函数值。
3.拥挤选择算子
在NSGA-Ⅱ中,定义拥挤比较算子≻n,假设i、j分别表示种群P中的两个个体。如果满足下面任何一个条件:
1)irank<jrank;
2)irank=jrank,并且di>dj;则称i≻nj,即个体i优于个体j。
在个体选择时,这样定义有如下好处:
1)第一个条件确保被选择的个体属于较优的非劣等级。
2)第二个条件有利于当节点均处于同一非劣等级时,可以根据拥挤距离选择位于较不拥挤区域的个体(有较大的拥挤距离的个体)。这样有利于在联赛选择和新种群填充阶段保持种群的多样性,同时也就是说经过足够多进化代数后能使最优点集均匀分布在Optimal Pareto Front Line上。
这里,描述一下在Deb提供的NSGA-Ⅱ的C语言原代码的选择子函数,首先随机产生两个0~1之间均匀分布的随机数,然后将这两个随机数与种群规模N相乘并取整,得到两个随机的个体,然后按照上面的拥挤选择算子,如此反复,选出N个较优的个体参与下面的SBX交叉以及变异操作。当然,这选出的种群存在许多重复的个体。
为方便下面的描述,在此做以下约定:
1)假定在Xf中第k个变量的取值上下限为Uk和Lk,k=1,2,…,n,即xk∈[Lk,Uk],k=1,2,…,n;
2)用rand()表示产生0~1之间均匀分布的随机数;
3)用i、j表示上面通过拥挤选择算子产生的两个较优的个体(因为随机性,这两个个体可能是同一个个体);
4)pc表示交叉概率,pm表示变异概率;
5)ηc表示自定义的交叉算子参数,并且ηc∈[0.5,100];
6)ηm表示自定义的变异算子参数,并且ηm∈[1,500];
7)rnd、α、β、γ是实变量,childki表示由i产生的新节点的第k个分量值大小;(https://www.xing528.com)
8)max(a,b)表示a与b中的最大值,min(a,b)表示a与b中的最小值。
4.基于连续实数变量编码的SBX交叉算子
在NSGA-Ⅱ中,Deb采用了SBX交叉算子,可从Deb提供的C语言源代码中提取了SBX交叉算子。对于该SBX交叉算子的描述如下:
rnd=rand()
if 1 rnd<Pc then/∗通过交叉算子产生后代∗/
rnd=rand()
if 2 rnd<=0.5 then/∗第k个分量通过交叉算子产生后代(概率为0.5是因为该分量要么变化要么不变化,各占一半的概率)∗/
if 3|x jk-x jk|>10-6 then/∗两个个体在第k个分量处距离相差较大∗/
令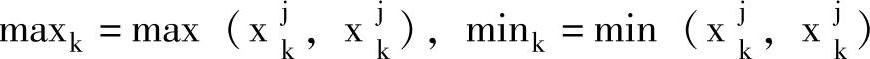
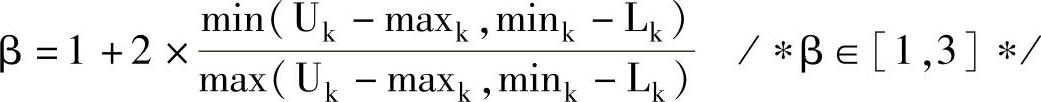
β=1/β/∗β∈[1/3,1]∗/
α=2-β1+η/∗α大概在1到1.5之间∗/
rnd=rand()
If 4 rnd≤1/α then
α=α×rnd/∗使α在0到1之间∗/
Else
α=1/(2-α×rnd)/∗使α大于1∗/
End if 4
γ=α1/(1+η)/∗使γ在1左右摆动∗/
Else/∗两个个体之间距离差非常小∗/
γ=1
End if 3
/∗下面是通过交叉算子产生的编号为i,j的后代∗/
child ik=min {max(0.5×(maxk+mink)-γ×(maxk-mink),Lk),Uk},k=1,2,3,…,n
child jk=min {max(0.5×(maxk+mink)-γ×(maxk+mink),Lk),Uk},k=1,2,3,…,n
Else/∗不通过交叉算子产生后代,由父代直接产生∗/
child ik=x jk,k=1,2,3,…,n
child jk=x jk,k=1,2,3,…,n
End if 2
Else/∗不通过交叉操作产生后代,由父代直接产生∗/
child ik=x jk,k=1,2,3,…,n
child jk=x jk,k=1,2,3,…,n
End if 1
从上面表达式可以看出,通过SBX交叉算子,子代可以在i节点和j节点所确定的箱内及箱外部附近随机游荡。不足之处在于它引入了一个人为的调节因子ηc来确定搜索空间的大小。
而且,若i节点和j节点所确定的箱空间比较小,则全局搜索能力就非常的弱。特别当它们都不处于第一层的Pareto Front Line上时,因为交叉算子本身是反映全局搜索能力的,所以此时对寻找Pareto Optimal Front Line的作用就非常小。另一方面,如果i节点或j节点有一个就位于全局最优的Pareto Front Line上,交叉的结果可能会极大偏离Pareto Front Line上,并且这种可能性在前期的概率极大,因为通过拥挤选择算子得到的子代获得位于Pareto Front Line上(或附近)的节点的概率非常高(但前期在Pareto Front Line附近的节点非常有限),所以这种一个节点位于Pareto Front Line附近,而另一个节点远离Pareto Front Line的情况就非常普遍,这样就不能充分利于Pareto Front Line附近节点的信息,前期极大地降低了收敛速度。也就是说,SBX交叉算子收敛速度太慢;但是SBX交叉算子适合用于后期(即经过有限代操作之后,当种群都是精英解时,若箱比较小,得到的子代也位于Pareto Front Line附近,若箱比较大,也有助于提高最优Pareto集的多样性,所以在后期交叉算子宜采用SBX)。
因此,非常有必要改进前期的交叉算子,以利用较高的优先级节点(即rank值比较低的节点)。而后期采用SBX,提高Pareto最优解集的多样性(即使结果更均匀分布在最优Pareto Front Line上)。这样前期提高收敛速度,后期提高解的多样性,就从整体上提高了算法的性能。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。