



Hive是分布式数据仓库,同时又是查询引擎,所以Spark SQL取代的只是Hive查询引擎,在企业实际生产环境下,Hive+Spark SQL是目前最为经典的数据分析组合,Hive本身就是一个简单单机版本的软件,主要负责:
1)把HQL翻译成Mapper-Reducer-Mapper的代码,并且可能产生很多MapReduce的Job。
2)把生产的MapReduce代码及资源打成JAR包,并自动发布到Hadoop集群中运行。
Hive本身的架构如图1-3所示。
Hive架构主要有下面4个部分组成:
1)驱动程序(Driver):负责编译、优化、执行。
Hive的入口是Driver,执行的SQL语句首先提交到Driver,然后调用编译器(Com-piler)解释驱动,最终解释成MapReduce任务执行,最后将结果返回。Driver调用编译器处理HiveQL(Hive SQL),可能是一条DDL、DML或查询语句。编译器将字符串转化为策略(Plan)。策略仅由元数据操作和HDFS操作组成,元数据操作只包含DDL语句,HDFS操作只包含LOAD语句。具体流程为:解析→语义分析→逻辑策略生成→优化→执行。
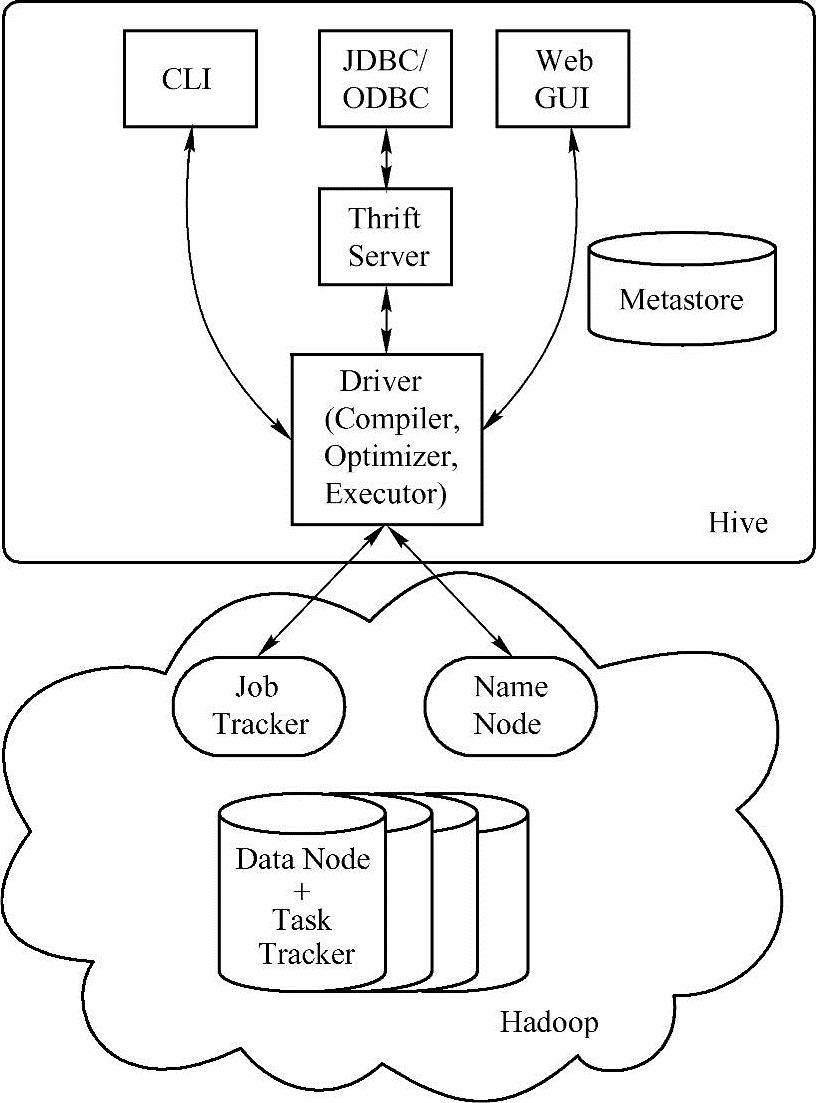
图1-3 Hive架构(https://www.xing528.com)
2)3种服务模式:Hive驱动对外提供了3种服务模式,分别是:
●CLI:即Hive命令行模式,通过命令行终端来直接操作Hive。
●Web GUI:即Hive的Web模式,通过浏览器来访问Hive。
●Hive的远程服务模式:通过Thrift Server的支持,远程Client程序可以通过JDBC/OD-BC方式来访问连接Hive,这也是程序员最需要的方式。
3)Metastore:元数据存储。
Hive将元数据存储在RDBMS中,一般常用MySQL和Derby。默认情况下,Hive元数据保存在内嵌的Derby数据库中,只能允许一个会话连接,只适合简单的测试。实际生产环境中不适用,为了支持多用户会话,则需要一个独立的元数据库,使用MySQL作为元数据库,Hive内部对MySQL提供了很好的支持。
4)Hadoop:Hadoop是Hive的运行基石。
Hive安装依赖Hadoop的集群,Hive运行在Hadoop上,用HDFS进行存储,利用Ma-pReduce进行计算。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。