



Spark SQL网站搜索综合实战案例实现用户每天搜索前3名的商品排名统计,具体实现步骤如下:
1)从Spark读入用户搜索日志记录,根据项目需求进行ETL数据清洗。在实际生产应用场景中,过滤条件可能非常复杂,对过滤以后的目标数据进行特定条件的查询,查询条件可能也非常复杂。在本综合实战案例中,我们使用广播变量,将广播变量分发到各个Execu⁃tor中进行查询过滤,使用RDD的filter操作,过滤出使用苹果手机搜索网站商品的用户搜索记录。
2)对用户登录网站的渠道将通过苹果手机登录的记录过滤以后,我们对目标数据构建Key-Value类型的RDD(date#Item#userID,1L),Key值为日期、商品及用户ID使用#连接的拼接字符串,Value值计数为1,使用reduce ByKey操作,统计Key值的汇总计数,即每用户在每天点击搜索每商品的总次数。
3)对reduceByKey以后的数据记录拆分重新组拼,拆分获取字段Date、UserID、Item,然后组拼加上汇总统计的搜索次数count,组成包含Date、UserID、Item、count的Json字符串,构造DataFrame。
4)在Spark SQL注册临时表,使用窗口函数row_number统计出每用户搜索每商品的前3名。
5)Spark SQL网站搜索结果持久化:可以通过RDD直接操作Mysql,把结果直接放入生产系统数据库DB中,通过Java EE、Web页面进行可视化展示,提供市场营销人员、仓储调度系统、快递系统、管理决策人员使用。也可以放在Hive中,通过Java EE使用JDBC连接访问Hive;也可以就放在Spark SQL中,通过Thrift Server提供Java EE使用;这里我们以JSON格式保存到磁盘文件系统中。
本案例的具体实现如下:
1)查询每天每用户点击某商品的次数。
●初始化Java Spark Context及Hive Context。通过sc.textFile加载用户搜索数据日志文件。
●使用广播变量device Broadcast,将要过滤的用户终端类型(安卓、苹果、平板)进行广播,使用filter方法进行过滤。
●查询每天每用户点击某商品的次数。对每行的数据按"\t"进行分割,将日期、商品、用户ID组成Key值,每次计数为1次,生成key-Value键值对(date#Item#userID,1)。即每天每用户点击某商品的次数计数为1。
代码如下:


2)统计每用户在每天点击搜索每商品的总次数。
●使用reduceByKey方法将用户每天点击商品的次数汇总累加。统计出每天用户搜索每商品的搜索次数累计值。
●将统计结果拼接成JSON格式。
代码如下:


3)在Spark SQL中注册临时表,使用窗口函数row_number统计出用户搜索每商品的前3名。
●调用sc.parallelize方法创建userLogsInformationsRDD,使用sqlContext.read().json加载Json数据,构建DataFrame userLogsInformationsDF。(https://www.xing528.com)
●将DataFrame注册成为临时表userlogsInformations。
●使用SQL窗口函数:以子查询的方式完成目标数据的提取,在目标数据内使用窗口函数row_number进行分组排序。
(1)先进行子查询sub_userlogsInformations,根据用户ID分组,按照搜索次数降序排序,查询出用户ID,商品ID,搜索次数,排名;
(2)然后从子查询sub_userlogsInformations查询,查询排名前3名的用户ID,商品ID,搜索次数。
代码如下:

sqlContext.sql(sqlText)使用开窗函数查询每用户搜索每商品的前3名的数据记录,打印输出userLogsHotResultDF。userLogsHotResultDF.show()运行结果如下。
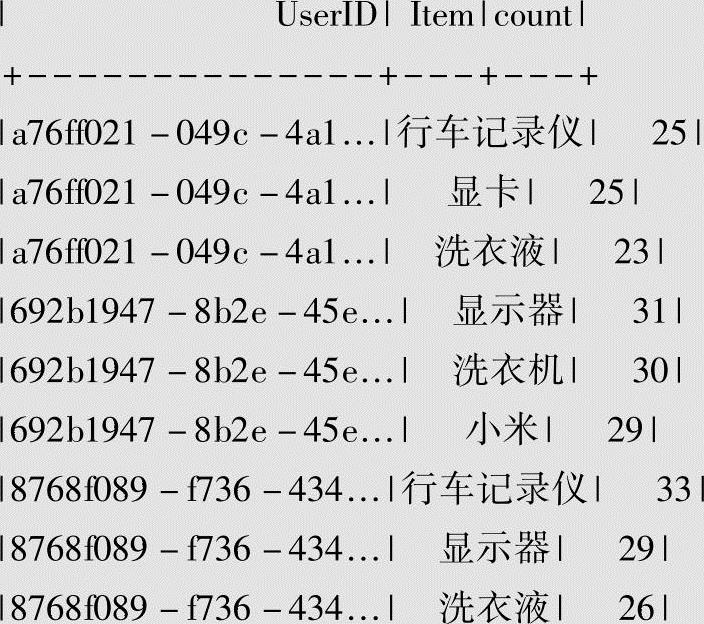
4)将结果以JSON格式保存到磁盘文件。
将每用户搜索每商品的前3名的数据保存到本地磁盘文件G:/Spark SQLData/Result.json,查看window系统中的G:/Spark SQLData/Result.json目录,目录里面已经生成一批小文件。文件格式包括_SUCCESS,._SUCCESS.crc,.part-r-00000-c4 e7 c8 c9-d08 a-443d-9238-e1 a13ba1 cee1.crc(类似多个文件),part-r-00018-70d42435-fd8 c-409 c-882 f-3 c4 f0727d392(类似多个文件)。查看其中一个用户搜索商品的前3名的数据结果文件,如part-r-00186-c4 e7 c8 c9-d08 a-443d-9238-e1 a13ba1 cee1的文件内容,显示用户7371b4bd-8535-461 f-a5 e2-c4814b2151 e1的搜索前三名的商品为“显卡”,计数35次;“洗衣机”,计数32次;“休闲鞋”计数29次,查询结果如下。

5)在Spark Web UI页面中查看程序运行情况。
SparkSQLUserlogsHot.Java使用Spark以本地Local模式运行,在Spark SQLUserlog⁃sHot类的末尾加上while(true){}循环语句,这样Spark SQLUserlogsHot.Java程序一直运行,就可以登录Spark web页面http://127.0.0.1:4040查看Spark SQLUserlogsHot应用运行情况。
登录Spark Web UI页面http://127.0.0.1:4040/jobs/,查询页面显示如图8-3所示。
登录Spark Web UI页面http://127.0.0.1:4040/SQL/,查询SQL页面。点击Detail列表“==Parsed Logical Plan==”项中右侧的[+details]键,可查看Parsed Logical Plan的详细内容,里面包括Spark SQL的Parsed Logical Plan、Analyzed Logical Plan、Optimized Logical Plan、Physical Plan的执行情况。如图8-4所示。
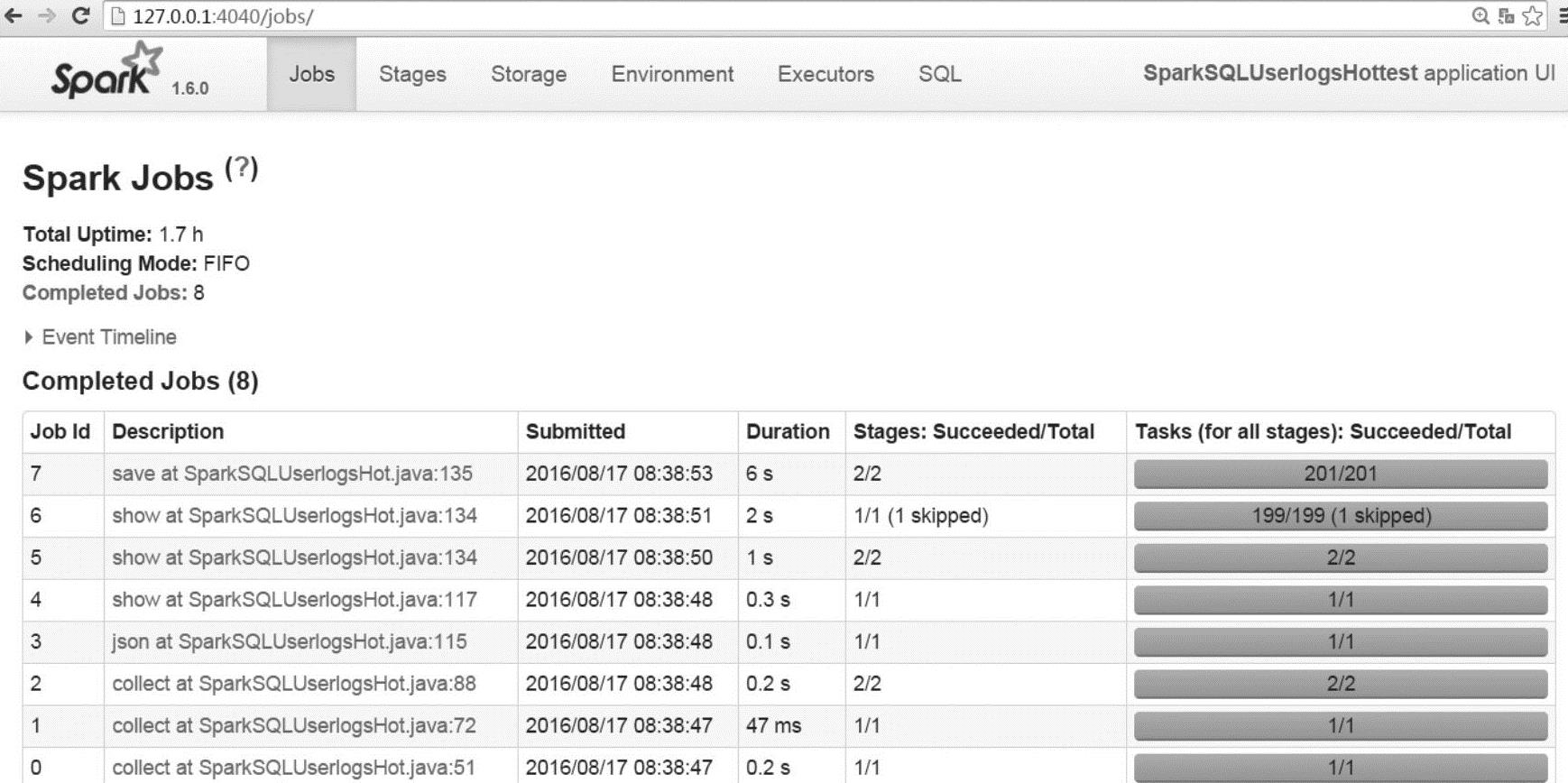
图8-3 Spark Web UI页面
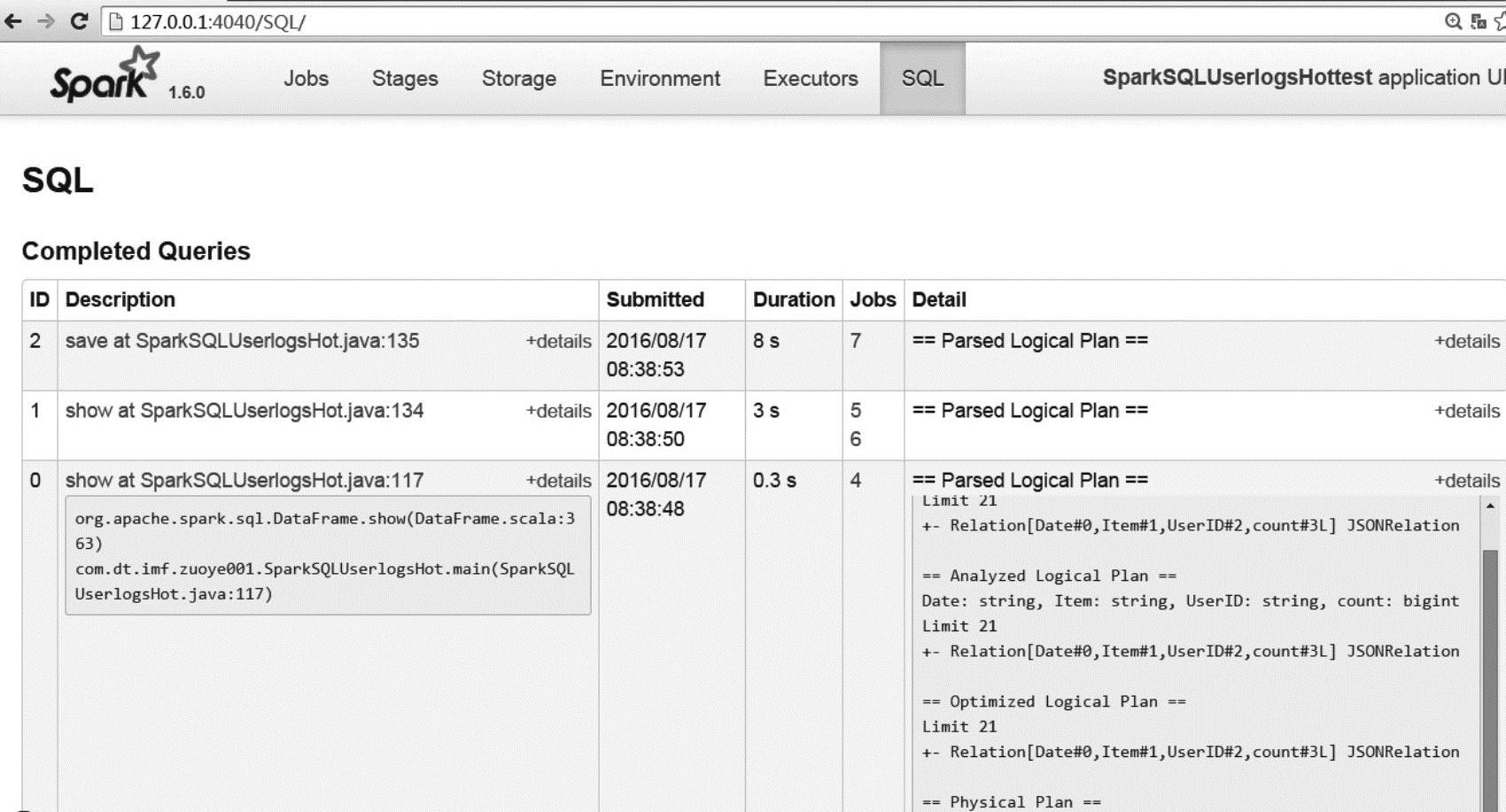
图8-4 Spark SQL页面
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。