



下面将进入本节的核心Apriori算法的程序设计部分。但在利用Apriori算法完成程序前,首先需要了解JPetStore中订单数据是如何存储的,这是我们完成后续工作的基础。
JPetStore中的商品订单使用了非常典型的订单设计,分为订单主表Orders和订单明细表Lineitem。它们的数据库结构如图6-10所示。
由上图可以看出订单主表Orders主要由订单号orderId和一些基础订单信息组成,而订单明细表LineItem主要由订单号orderId、订单明细号linenum、商品号itemid、购买数量Quantity、单价unitprice组成。相信读者会发现订单明细表LineItem很像6.2.2节中提到的顾客购物清单,而唯一的区别则是JPetStoreBI数据库中的一个订单是由多行LineItem记录构成的,而顾客购物清单则只是一条记录,因此锁定LineItem表为本次商品关联度数据分析的对象。
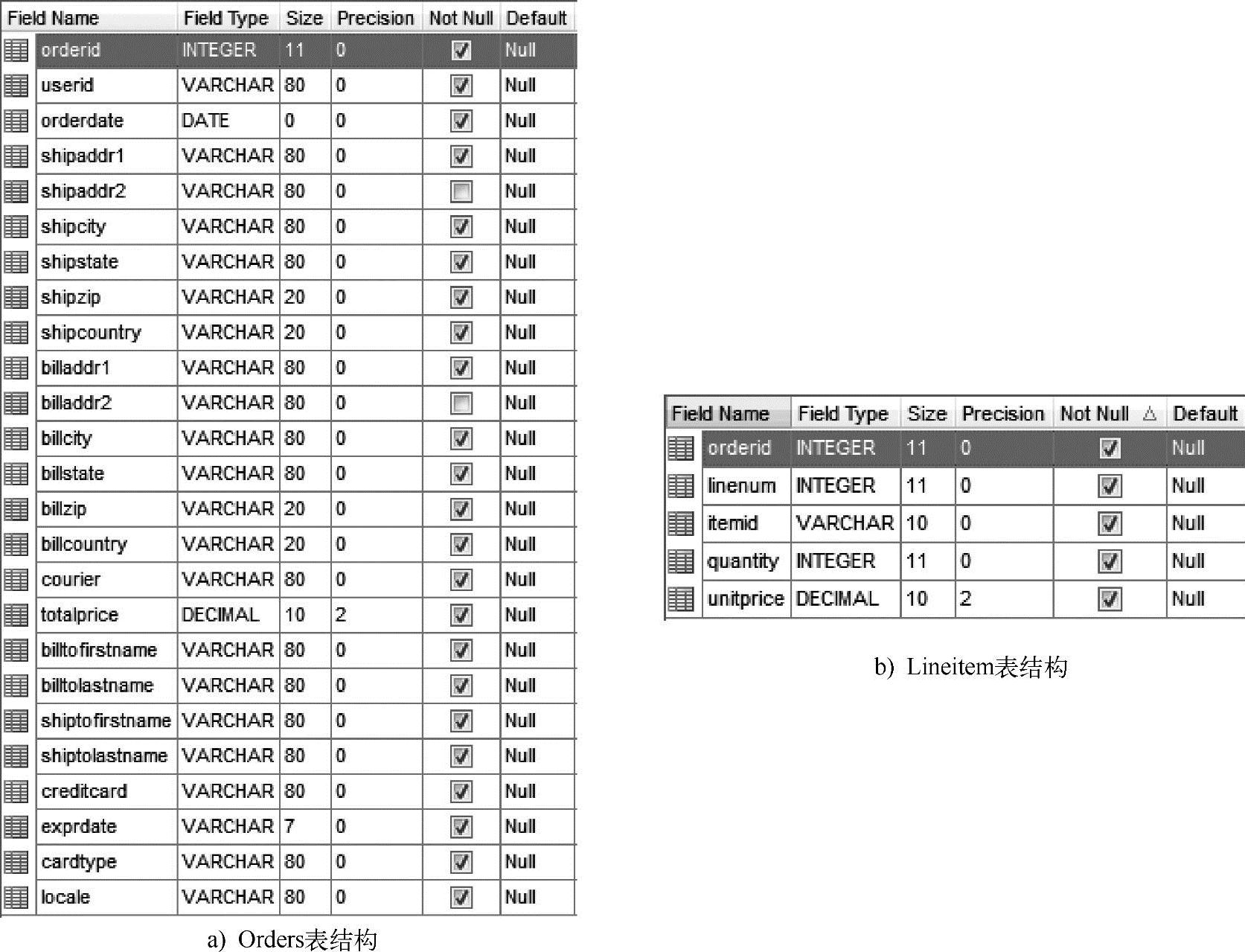
图6-10 Orders和Lineitem数据库表结构
在实际的业务中,商品的订单数据量可能会非常庞大。因此,在每次顾客选购商品时利用Apriori算法进行实时的数据挖掘是不现实的,开发人员一般会通过定时任务执行的方式对后台的商品关联结果(即Apriori算法中的商品频繁项集)进行数据更新。这里,需要新建一个表Relationship来存储该计算结果。并且,为了今后商品查询的简便性,在该表中只使用一个长度为1000的VARCHAR字段Relation来记录各关联商品的itemid集合,不同itemid间使用“,”进行分割。
在上述环境准备完毕后,就可以开始进行实际代码的编写了。这里假定读者对MVC思想、Spring框架和MyBatis持久化工具已经有了基本的了解,后面将不会涉及相关工具的具体介绍,请读者自行学习。
(1)对JPetStore主界面的调整
为了更好地进行演示,在本例中不会使用后台定时程序完成商品频繁项集的计算,而是通过在主界面Main.jsp上单击按钮的方式来生成分析结果。Main.jsp文件的位置在WEB- INF\jsp\catalog目录下。为了在界面上能够根据用户自定义的支持度来生成商品频繁项集,需要复制如下代码(见代码清单6-3)并置于Main.jsp中id为SidebarContent的Div容器中的尾部。
【代码清单6-3】

在上述代码的第一个form中可以看到beanclass="org.mybatis.jpetstore.web.actions.DataMiningActionBean"的代码段,org.mybatis.jpetstore.web.actions.DataMiningActionBean即程序中生成商品频繁项集将要调用的后台服务类名,form中submit按钮的name属性值Dat-aMiningOrderRelations即为需要调用的业务方法名称。第二个form的作用则是显示上述方法调用的结果反馈信息。
(2)后台DataMiningActionBean和DataMiningService的处理程序
在界面调整完毕后就需要完成后台的业务处理程序逻辑。下面将要建立DataMiningAc- tionBean来接收前端Main.jsp界面传来的请求,并调用后台的DataMiningService以完成实际的业务处理。DataMiningActionBean类的代码如代码清单6-4所示。
【代码清单6-4】


从上述代码中可以发现DataMiningActionBean只负责完成参数传递和界面跳转的功能,它仅将最小支持度minSupport传递给后台DataMiningService,并调用dataMiningSer-vice.DataMiningOrderRelations方法完成真正的商品频繁项集生成操作,最后将调用结果re-sultStr返回给前端界面。DataMiningService的代码如代码清单6-5所示。
【代码清单6-5】(https://www.xing528.com)







在上述代码中,DataMiningOrderRelations方法是获得商品频繁项集的主函数。根据Apri-ori算法理论,首先通过itemMapper.getItemList方法得到所有商品的信息并构造频繁1项集l1,之后将l1代入dataMiningByApriori方法中进行迭代,并对每次得到的迭代候选结果进行最小支持度分析,通过checkSupport方法返回满足最小支持度的频繁N项集,直到当ln的结果等于0时结束迭代,并最终通过writeResult方法返回计算结果并写入Relationship数据表中。
这里还要对程序中用到的部分数据库映射代码做进一步的配置,由于这部分不是介绍的重点,读者只需要从表6-5中创建相关文件或代码段到文件的对应位置即可。
表6-5 数据库映射配置代码表

(续)

上述代码配置,使用Apriori算法进行的程序主体工作已经完成,页面的显示效果如图6-11所示。
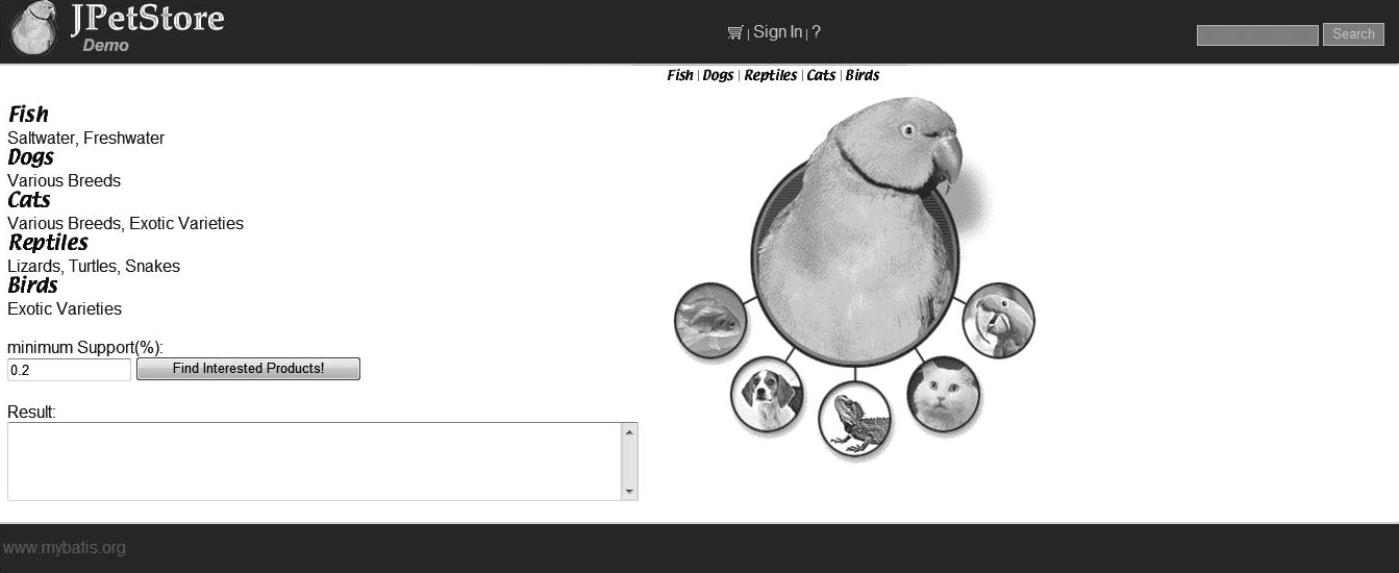
图6-11 使用Apriori算法修改后的网站效果
虽然宠物商店商品频繁项集的生成程序已经完成,但是在没有实际的订单业务数据的情况下,如何才能验证程序的准确性呢?另外,怎样才能测试不同订单数据量下程序的运行效率?开发一个商品销售记录生成程序就能解决这些问题。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。