



1.信息过滤的关键技术
根据信息过滤的概念和特点,结合信息检索的一般模型,Nicholas和Belkin在参考文献[13]中给出了信息过滤的一般模型。模型如图3-1所示。
在图3-1的信息过滤的一般模型中,原始信息经过特征抽取被表示为代表其特征的一定的格式,用户长期的信息需求被表示为用户模板,运用一定的过滤规则将两者进行比较和匹配(过滤),并将过滤结果提供给用户,用户使用过滤结果并将对过滤结果的评价反馈给系统以修改用户模板和用户信息需求。
信息过滤系统(Information Filtering System,IFS)是在信息过滤的一般模型的基础上研制出来的。一个简单的信息过滤系统包括三个基本部分:信息源(Source)、过滤器(Filter)和用户(User)。信息源向过滤器提供信息及其特征描述,过滤器根据用户信息需求有选择的向用户递送信息,用户向过滤器发出反馈信息以指明哪些信息符合他们的信息需求,过滤器进行不断地学习和调整,以提供更符合用户个性化需求的信息。
一个好的信息过滤系统必须满足以下3个条件:
(1)必须能够有效地将有用的信息提供给用户;
(2)必须能够足够快地将有用的信息提供给用户;
(3)必须能够有效地处理吞吐信息。
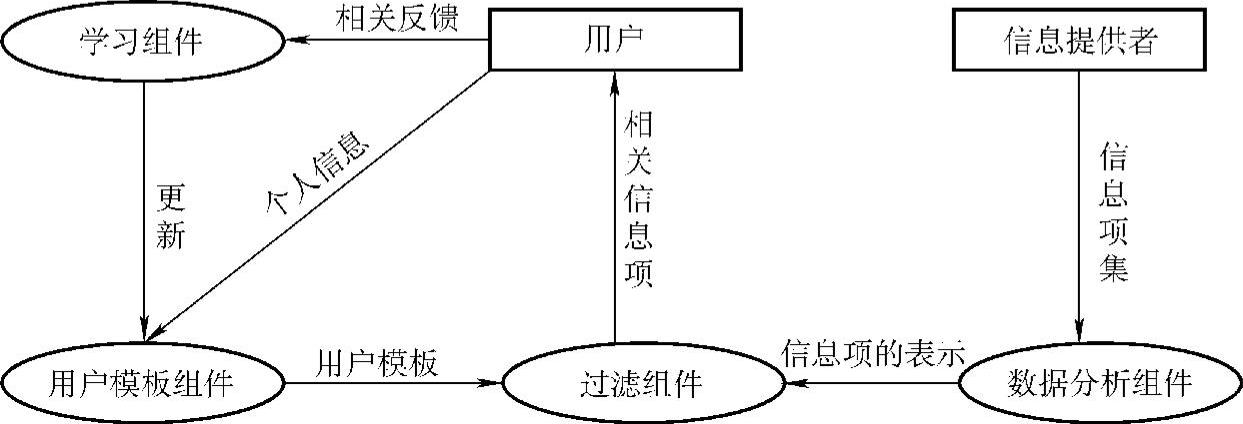
URI HANANI,BRACHA SHAPIRA和IPERETZ SHOVALZ等人在参考文献[14]中给出了信息过滤系统的一般模型,如图3-2所示。
根据信息过滤系统的一般模型,一个信息过滤系统一般包括四大组件,即数据分析组件、过滤组件、用户模板组件和学习组件。数据分析组件从信息提供处收集数据项并以一种合适的方式表示,然后将其作为输入送到过滤组件中去。用户模板组件以显式或者隐式的方式获得用户的信息需求,并以此构建用户模板,用户模板信息也作为输入送到过滤组件中。过滤组件把信息源数据项的表示与用户模板相匹配,决定信息项是否与用户相关,并把与用户需求相关的信息项提供给用户。学习组件用来检测用户兴趣改变,修改用户模板,逐步完善用户模板以获得一个理想的过滤效果。
2.网络文本信息过滤模型
网络文本信息过滤模型如图3-3所示。
 (https://www.xing528.com)
(https://www.xing528.com)
图3-2 信息过滤系统的一般模型
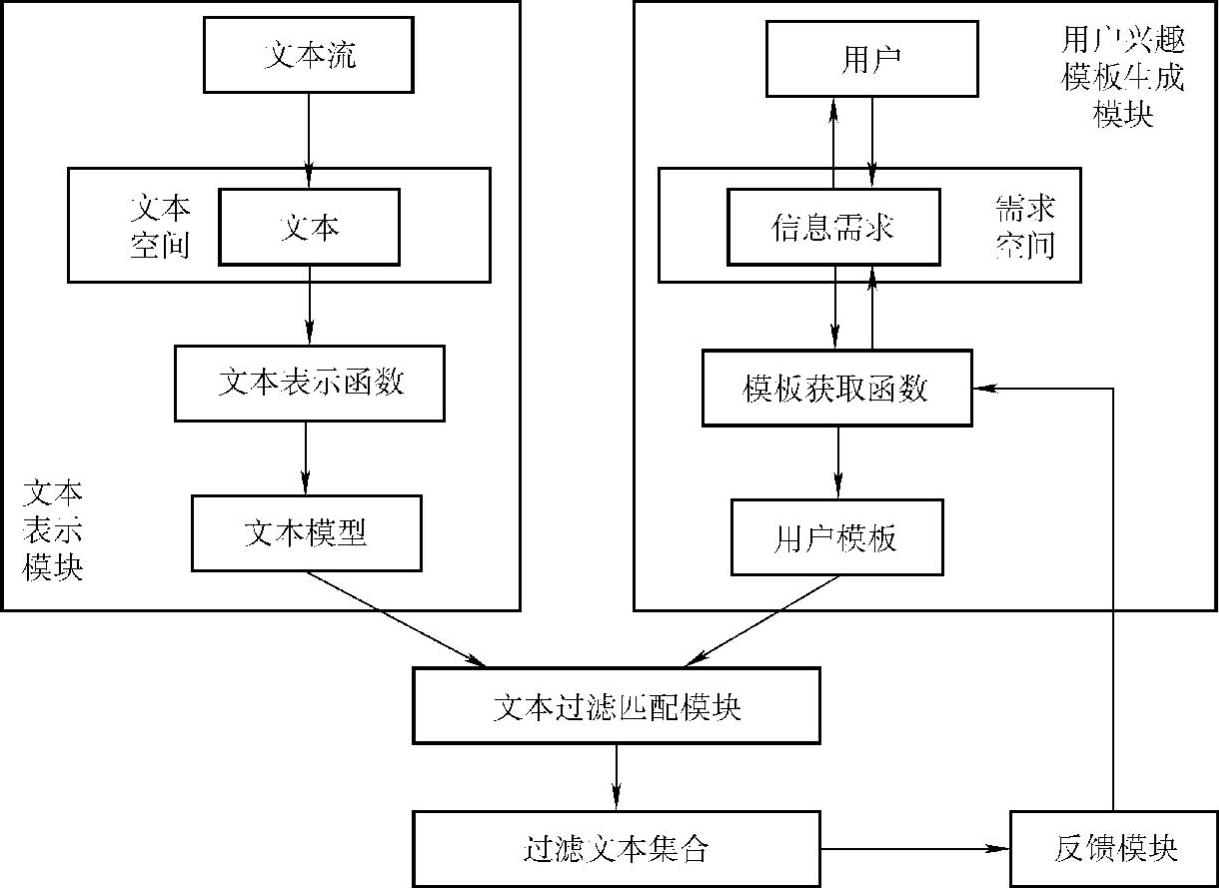
图3-3 网络文本信息过滤模型
实施网络文本信息过滤技术有助于减轻用户的认知压力,它在基于个人或用户群信息偏好的描述下为用户提供所需要的信息,也着重删除与用户不相关的信息,从而提高用户获取信息的效率。解决和优化文本信息过滤模型中的两大关键技术,即用户模型技术和匹配技术,对于大规模网络文本信息过滤具有重要的意义。
从图3-3来看,文本信息过滤系统主要包含:文本表示模块、文本过滤匹配模块、用户兴趣模板生成模块、反馈模块等,其中文本表示模块主要针对采集到的信息提取其中的特征信息,按照一定的格式来描述,然后作为输入信息传递给过滤匹配模块;用户兴趣模板生成模块是依据用户对信息的需求和喜好来生成,并根据用户提供的学习样本或主动跟踪用户的查询行为建立用户兴趣的初始模板,再根据用户反馈模块不断更新用户模板;文本过滤匹配模块就是将用户兴趣模板与信息表示模块中的信息分析表示结果按照一定的算法进行匹配,并按照匹配算法决定将要传递给用户的相关信息项;用户得到文本过滤的结果后,对其进行评价并反馈给用户模块,用户模块通过不断跟踪学习用户兴趣的变化及用户反馈来调整甚至更改用户需求表达,以求不断实现正确过滤无用信息的目的。
以下简要介绍模型中各部分的主要技术:
(1)文本表示。包括将Web中的有效文本信息提取出来,对于中文文本过滤来说,涉及中文的分词、停用词处理、语法语义分析等等过程。常用的方法是建立文本的布尔模型、向量空间模型和概率模型等。
(2)用户模板的建立。用户模板空间常按照倒排索引的方式存储用户信息,建立用户模板的方式有建立关键字表和示例文本,而常用的技术有建立向量空间模型、预定义关键字、层次概念集利分类目录等。
(3)用户模板与文本的匹配。最常用的方法有布尔模型、向量空间模型和概率模型。
(4)用户反馈。用户反馈分为确定性反馈和隐含性反馈。确定性反馈指的是二元(是或否)反馈,另外还有分级打分的方法。利用这些反馈信息,应用机器学习方法,完善用户模板。
综合以上介绍分析,可以将网络文本信息过滤的工作概括为两个方面:一是建立用户需求模型,即用户模板,用于描述用户对于信息的具体需求。建立用户需求模型的主要依据是用户提交的关键词、主题词或示例文本。二是匹配技术,即用户模板与文本的匹配技术。简单地讲,文本过滤模型就是根据用户的查询历史创建用户需求模型,将信息源中的文本有效表示出来,然后根据一定的匹配规则,将文本信息源中可以满足用户需求的信息返回给用户,并根据一定的反馈机制,不断地调整改进用户需求模型,以期获得更好的过滤结果。从技术角度来看,文本信息过滤的关键技术是获得用户信息需求(用户模板的建立)和解决信息过滤算法,即信息过滤技术研究应当集中在解决用户模板的表示及根据模板对文本流进行评价的方法上。为提高信息过滤系统的性能,应加强对过滤匹配算法和用户模型的研究与实践。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。