



判别方法是统计分析领域的过滤和分类算法的总称,主要有向量中心法、相关反馈法(Rocchio法)、K近邻(K-Nearest Neighbor,KNN)法、贝叶斯法[朴素贝叶斯(Naive Bayes)法和贝叶斯网络(Bayes Nets Work)]、多元回归模型(Multivariate Regression Models)、支持向量机(Support Vector Machines)以及概率模型(Probabilisite Model)等[21-23]。
1.向量中心法
向量中心法是建立在向量空间模型的基础上的。该方法通过计算新到来的文档与表示过滤主题的用户兴趣(向量中心)之间的夹角余弦值:
或者向 量内积
来判断文档是否跟该主题相关而被检出。由于这种方法简单而实用,因而在信息过滤、信息检索、文本分类等多个领域都得到了广泛应用。
2.相关反馈法
Rocchio法是一个在信息检索中广泛应用于文本处理与过滤等业务中的算法,它是一种基于相关反馈(Relevance Feedback)的,建立在向量空间模型上的方法。它用TFIDF方法来描述文本,其中TF(wi,d)是词wi在文本d中出现的频率,DF(wi)是出现wi文本数。该方法中可以选择不同的词加权方法、文本长度归一化方法和相似度测量方法以取得不同的效果。Rocchio方法首先通过训练集求出每一个主题的用户兴趣向量,其公式如下:
其中→C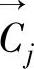 是主题j的用户兴趣,α/β反映正反训练样本对
是主题j的用户兴趣,α/β反映正反训练样本对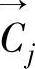 的影响。
的影响。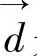 是文本向量,
是文本向量,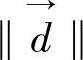 是该向量的欧氏距离,D是文本总数。
是该向量的欧氏距离,D是文本总数。
若以余弦计算相似度,则判别文本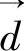 是否跟主题
是否跟主题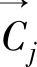 相关的公式为
相关的公式为
式中,n为每个文档的特征项(词)的个数。上式中忽略了d的长度,因为它不影响argmax的结果。Rocchio法实现起来较为容易,但是,它需要事先知道若干正负样本,受训练集合的影响较大,有时会导致性能的下降。
3.K近邻法[26]
K近邻方法的原理也很简单。给出了未知相关主题的文本,计算它与训练集中每个文本的距离,找出最近的k篇训练文档,然后根据这k篇文档的特性来判断未知文本相关的主题。可以选择出现在这k个邻居中相关的文本与未知文本的相似度的和,值最大的主题就被判定为未知文本相关的主题。如果允许每个主题相关样本点都有资格作为主题类的代表的话,这就是最近邻法。最近邻法不是仅仅比较与各主题类均值的距离,而是计算和所有样本点之间的距离,只要有距离最近者就归入所属主题类。为了克服最近邻法错判率较高的缺陷,K近邻法不是仅选取一个最近邻进行判断,而是选取k个近邻,然后检查它们相关的主题,归入比重最大的那个主题类。(https://www.xing528.com)
4.贝叶斯法
(1)朴素贝叶斯法[27,28]。朴素贝叶斯算法在机器学习中有着广泛的应用。其基本的思想是在贝叶斯概率公式的基础上,根据主题相关性已知的训练语料提供的信息进行参数估计,训练出过滤器。进行过滤时,分别计算新到文本跟各个主题相关的条件概率,认为文本跟条件概率最大的主题类相关。其计算公式如下:
式中,等式右边的概率均可根据训练语料,运用参数估计的方法求得。朴素贝叶斯方法是在假设各特征项之间相互独立的基本前提下得到的。这种假设使得贝叶斯算法易于实现。尽管这个假设与实际情况不相符,但实际应用证明,这种方法应用于信息过滤中是比较有效的。
(2)贝叶斯网络[29]。Heckerman等人和Sahami分别提出了对贝叶斯网络的理解与学习方法。贝叶斯网络的基本思想是取消纯粹贝叶斯方法中关于各特征之间的独立的假设,而允许它们具有一定的相关性。K-相关贝叶斯网络是指允许每个特征有至多k个父节点f,即至多有k个与之相关的特征项的贝叶斯网络。朴素贝叶斯则是贝叶斯网络的一个特例;0-相关贝叶斯网络。
5.多元回归模型
多元回归模型运用了线形最小平方匹配(Linear Least Square Fit)的算法。通过求解输入-输出矩阵的线形最小平方匹配问题,得到一个回归系数矩阵,作为过滤器。具体来讲就是求出一个矩阵X使得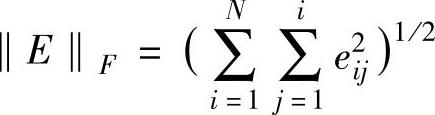 最小。其中E=AX-B。在信息过滤中A是输入矩阵,是训练集文本的词-文本矩阵(词在文本中的权重);B是输出矩阵,是训练集文本的文本-相关主题矩阵(主题在文本中的权重)。求得的矩阵X是一个关于词和主题的回归系数矩阵,它反映了某个词在某一主题类中的权重。在过滤过程中,用相关主题未知的文本的描述向量
最小。其中E=AX-B。在信息过滤中A是输入矩阵,是训练集文本的词-文本矩阵(词在文本中的权重);B是输出矩阵,是训练集文本的文本-相关主题矩阵(主题在文本中的权重)。求得的矩阵X是一个关于词和主题的回归系数矩阵,它反映了某个词在某一主题类中的权重。在过滤过程中,用相关主题未知的文本的描述向量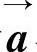 与回归系数矩阵X相乘就得到了反映各个主题与该文本相关度的矩阵
与回归系数矩阵X相乘就得到了反映各个主题与该文本相关度的矩阵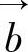 。相关度最大的主题就是该文本所相关的主题。
。相关度最大的主题就是该文本所相关的主题。
6.支持向量机
支持向量机算法是Vapnik提出的一种统计学习方法,它基于有序风险最小化归纳法(Structural Risk Minimization Inductive Principle),通过在特征空间构建具有最大间隔的最佳超平面,得到两类主题之间的划分准则,使期望风险的上界达到最小。支持向量机在文本分类领域得到了比较成功的应用,成为表现较好的分类技术之,其主要缺点是训练过程效率不高。N.Cancedda人将这种方法用于解决自动信息过滤问题[30],同样取得了较好的效果。
7.概率模型[31,32]
概率模型是Stephen Roberson等提出的信息检索模型,该模型同样可以用于信息过滤。其主要特点是认为文档和用户兴趣(查询)之间是按照一定的概率相关的,因而在特征加权时融入了概率因素,同时也综合考虑了词频、文档频率利文档长度等因素。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。