



集中趋势 (central tendency) 是指一组数据向某一中心值靠拢的倾向,它反映了一组数据的中心点的位置所在。测度集中趋势也就是寻找数据水平的代表值或中心值。在本节我们主要介绍众数 (mode)、中位数 (median)、四分位数 (quartiles)、平均数 (mean)。
4.1.1 众数
众数(mode) 通常记为M0,指数据中出现次数最多的数。众数一般用来描述分类变量,特别是那些有许多值的分类变量,如学历、对事物的态度、国家等。众数也可以测度其他类型的变量。
[例4.1]根据某天随机抽查的50名顾客在某大型超市购买的饮料的品牌的数据编制的频数分布表如表4-1所示。求这组数据的众数。
表4-1 饮料品牌频数分布表
解: 从表4-1可以看出,在所调查的50人中,购买可口可乐的人数最多,为15人,因此众数为“可口可乐”这一品牌,即M0=可口可乐。
[例4.2]负责公司网络系统的经理掌握着每天服务器的故障次数的数据。下面的数据反映了最近两个星期服务器每天出现故障的次数:
1 3 0 3 26 2 7 4 0 2 3 3 6 3
求这组数据的众数。
解: 先将这组数据排序如下:
0 0 1 2 2 3 3 3 3 3 4 6 7 26
我们可以看到“3”这个数字出现的次数最多是5次,因此3是众数,即该经理可以说一天之中服务器最经常出现故障的次数是3。
有时候,一组数据可能有多个众数或没有众数,考虑下面的准备时间数据:
28 30 35 39 39 40 43 44 44 52
有两个众数分别是39和44,因为这两个值出现了两次,其他的值只出现了一次。
例如,一个10家银行支票退回费用的样本数据如下:
26 28 20 21 22 25 18 23 15 30
这些数据就没有众数,因为每个数值出现的次数都一样多,只有一次。
众数是一个位置代表值,它不受数据中的极端值的影响。众数具有不唯一性,即一组数据可能有一个众数,可能有多个众数,可能没有众数。
4.1.2 中位数
中位数(median)通常记为Me,指一组数据排序以后,处于中间位置的变量值。中位数是另一个关于中心位置的统计量。显然,中位数将全部的数据等分成两部分,每部分包含50%的数据,一部分数据比中位数小,一部分数据比中位数大。一般来说,在研究房价、收入分配等许多其他经济变量时常常使用中位数来描述。
将数据xi按值由大到小排序后记为x(1),x(2),…,x(n)之后,则中位数为:
当数据的个数n为奇数时,中位数为处于(n+1)/2位置上的数值,即中位数=x(n+1)/2。
当数据的个数n为偶数时,中位数为处于中间位置上两个数据的平均值,即中位数=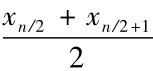 。
。
[例4.3]假设在某城市随机抽查5家企业得到的年销售额数据分别为62.9万元、61.6万元、62.5万元、60.8万元和120万元,计算年销售额的中位数。
解: 先将上面的数据排序,结果如下:
60.8 61.6 62.5 62.9 120
中位数的位置=(n+1)/2=(5+1)/2=3
中位数=62.5
我们再看看当数据的个数为偶数时怎样计算中位数。
假定抽取6家企业,每个企业的年销售额数据排序后如下: 58万元、60.8万元、61.6万元、62.5万元、62.9万元、120万元。
中位数的位置=(n+1)/2=(6+1)/2=3.5
中位数=(61.6+62.5)/2=62.05
中位数具有以下优点:
(1)中位数不易受极端值的影响。中位数仅指排序以后处于中间位置上的值,不会受到极大值或者极小值的影响。
(2)中位数具有唯一性,即一组数据只有一个中位数。
(3)中位数计算简单。只需要将所有的观测值从小到大排序,就可以应用找中点的方法得到中位数。
同时中位数也有一些缺点: 中位数仅仅只考虑中间值,并未利用其他观测值。这样它就没有利用数据中的所有信息。
4.1.3 四分位数
中位数是从中间将全部数据等分为两部分。与中位数类似的还有四分位数、十分位数、百分位数、千分位数、万分位数等。它们分别是用3个点、9个点、99个点将数据分为4等份、10等份、100等份后各分位点上对应的值。这里我们只介绍四分位数的计算,其他分位数依此类推。
四分位数(quartiles)是指将一组数据排序后处于25%和75%位置上的值。四分位数是通过三个点将全部数据等分为四部分,其中每部分包含25%的数据。很显然中间的四分位数就是中位数,因此通常所说的四分位数是指处于25%位置上的数值,称为第一四分位数(记为Q1),以及处于75%位置上的数值,称为第三四分位数(记为Q3)。下面介绍计算第一四分位数和第三四分位数的方法:
将数据xi按值由大到小排序后记为x(1),x(2),…,x(n)之后,则:(https://www.xing528.com)
在具体计算的过程中,由于涉及数据个数的奇偶问题,上面的公式算出来的不一定正好是整数或两个整数的中间,这就需要遵循以下的规则:
(1)如果求得的位置是整数,该位置上的这个观测值就是四分位数。
(2)如果求得的位置处于两个整数的中间,则它们相应的观测值的平均数就是四分位数。
(3)如果求得的位置既不是整数也不是两个整数的中间,一个简单的规则就是就近取整,并找出相应该整数位置上的观测值。
[例4.4]收集到一组数据如下:
12 16 15 9 8 14 11 10 18 20
求第一四分位数和第二四分位数。
解: 先将上面的数据排序,结果如下:
8 9 10 11 12 14 15 16 18 20
第一分位数的位置=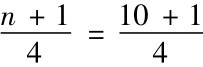 =2.75
=2.75
根据规则3,将其就近取整数到第三个位置的观测值,即第一四分位数=10。
第一分位数的位置=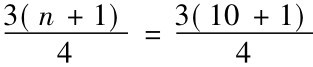 =8.25
=8.25
根据规则3,将其就近取整数到第八个位置的观测值,即第三四分位数=16。
4.1.4 平均数
平均数(mean)是一组数据相加后除以数据个数而得到的结果。像中位数一样,均值大致位于观测值中部。两者的不同之处在于,均值是一个变量的值,它可以看做数据集的重心。如果根据观测值的大小把它们放在跷跷板上,则跷跷板会在均值处达到平衡。
4.1.4.1 简单均值(simple mean)
根据未经分组的原始数据计算平均数。设xi表示第i项数值,若该组数据为总体数据,共有N项数值,则总体均值用希腊字母μ表示,计算公式为:
若该组数据为样本数据,共有n项数值,则样本均值用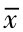 表示,计算公式为:
表示,计算公式为:
[例4.5]以下是一组容量n=11的样本数据如下:
7 5 8 3 6 10 12 4 9 15 18
请计算均值。
解: 根据公式得:
4.1.4.2 加权均值(weighted mean)
根据分组的原始数据计算平均数。设原始数据被分成k组,各组的组中值分别用M1, M2,…,MK表示,各组表量值出现的频率分别用f1,f2,…,fk表示,则总体均值的计算公式为:
式中,N=∑fi,即总体数据的个数。
对于样本数据,均值的计算公式为:
式中,n=∑fi,即样本容量。
[例4.6]根据第3章表3-8中的数据,计算家庭月人均可支配收入的均值。
解: 计算过程见表4-2。
表4-2 某市居民家庭月人均可支配收入数据的均值计算表
根据上面的公式得: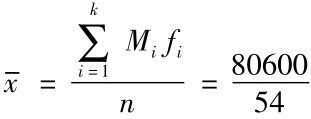 ≈1493(元)
≈1493(元)
根据上面的公式计算的时候,是用各组的组中值代表各组的实际数据,使用这个代表值时是假定各组数据在组内的分布是均匀分布的。如果实际数据与这一假定相符合,计算的结果还是比较准确的,否则误差会较大。
4.1.4.3 几何平均值(geometric mean)
当统计数据是各时期的增长率等前后两个时期的两两比率数据(环比),希望求出每时期的平均增长率、百分比时,几何平均值非常有用。我们常对销售收入、工资或者国内生产总值等经济数据的变化百分比很感兴趣,因此几何平均值在商业上和经济上有着广泛的应用。n个正数的几何平均值被定义为这n个值的乘积的n次方根,其计算公式可以表示为:
式中,xi(i=1,2,3,…,n) 是百分比或比率。
[例4.7]如果投资者在2007—2011年的收益率分别为5.2%,5%,2.5%,2.8%, 3%,则该投资者在这5年内的平均收益率是多少?
解: 根据上面的公式得:
4.1.5 众数、中位数和平均数之间的关系
选择哪种集中趋势测度指标将取决于所分析的数据集的性质和应用的要求。因此,了解众数、中位数和平均数之间的关系是很重要的。
平均数容易被多数人理解和接受,在实际中用得也较多,但主要的缺点是易受极端值的影响,对于偏态分布的数据,平均数的代表性较差。众数和中位数提供的信息不像平均数那样多,但它们也有优点,比如不受极端值的影响。当数据为偏态分布,特别是当偏斜的程度较大时,可以考虑选择中位数或者众数,这时它们的代表性要比平均数好。比如, 2007年有关香港的一则报道说,随着经济的增长,在香港家庭中低收入家庭的比重在增加。其中低收入家庭是指收入低于中位数的家庭。这里没有使用平均数作为划分低收入家庭的标准,原因是香港的富翁较多,平均收入很高,但它代表不了大多数家庭的收入状况。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。