



在语音领域中,最有意思的多任务学习应用当属多语种或者交叉语种的语音识别,不同语言的语音识别被当作不同的任务。为了解决语音识别中非常有挑战性的声学建模问题,已经出现各种各样的方法。然而出于经济层面的考虑,构建全世界所有语种的语音识别系统,瓶颈在于缺乏标注的语音数据。对于高斯混合模型—隐马尔可夫模型(GMM-HMM)系统[225]而言,交叉语种的数据共享以及数据加权是最普遍且行之有效的方法。GMM-HMM中另一种成功的方法是通过基于知识或者数据驱动方法来完成跨语言的发音单元映射[420]。但是这些方法的效果是远不如深度神经网络—隐马尔可夫模型(DNN-HMM)的,我们现在对这一方法做一下总结。
最近的几篇论文中[94,170,150],两个研究小组独立提出了非常相近的、具有多任务学习能力、用于多语种语音识别的深度神经网络架构。从图11.5中我们可以看到这种架构的图解。这一架构的思想是:通过适当的学习,深度神经网络中由低到高的隐层充当着复杂程度不断增加的特征变换,而这些变换共享跨语言声学数据中共有的隐藏因素。神经网络最后一个softmax层充当着一个对数线性(log-liner)分类器,利用了最顶端隐层所表示的最抽象的特征向量。尽管对数域的线性分类器对不同语言在必要时可以分开,但特征转换仍可以在跨语言之间共享。文献[225,420]中报告的多语种语音识别的效果非常好,这个结果比基于GMM-HMM的方法好很多。这些工作的意义是重要而深远的,它表明了我们可以从一个现有的多语种DNN中快速构建出一个性能良好的新语种DNN识别器。这样最大的好处莫过于我们只需要目标语言少量的训练数据,当然有更多的数据可以进一步地提高性能。这个多任务的学习方法可以降低无监督预训练阶段的需求,并且可以用更少的迭代次数进行训练。对这些工作进行推广,就可以高效地构建一个通用语言的语音识别系统。这样的系统不仅能够识别许多语言以及提高每种语言的识别精度,还能够通过简单地堆叠DNN的softmax层扩展到对一种新的语言的支持。
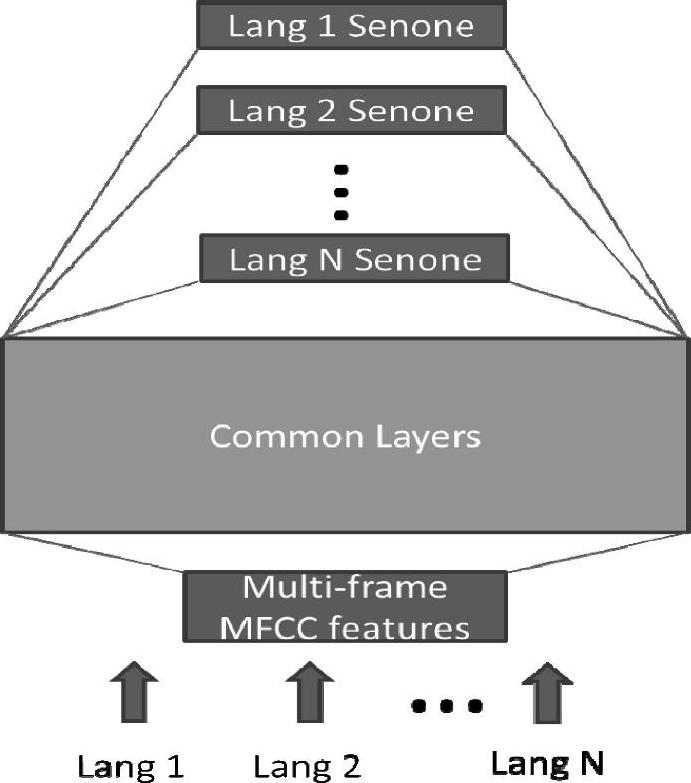
图11.5 一个用于多语种语音识别的DNN架构
图中词语翻译对照表
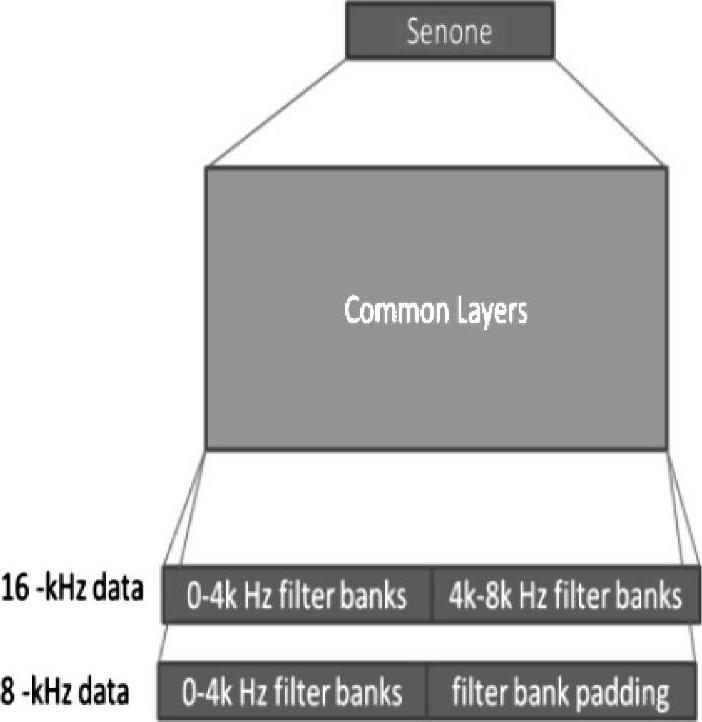
图11.6是一个与上述模型密切相关的、具有多任务学习能力的深度神经网络架构。该模型最近被应用到了另一个声学建模的任务中——学习两个不同声学数据集合的联合表示[94,221]。数据集包含宽带、高质量的16kHz采样率的语音数据,这些数据通常是从日趋流行的智能手机语音搜索应用中采集到的。而另外一种,采样率是8kHz的窄带数据集通常是通过电话语音识别系统采集而来的。
下面介绍语音领域的最后一个多任务学习的例子。首先,我们将音素识别和词识别当作是两个单独的“任务”。音素识别的结果往往被用于口语文本检索中语种类型的鉴别,而不是用于产生文本输出。音素识别的结果不是用来产生文本输出,而是用来做语种辨识或者语音文档检索。进而,在几乎所有语音系统中发音词典的使用可以看作是共享音素识别和单词识别任务的多任务学习。更多先进的语音识别的框架已经将这个方向推得更远。这些框架使用比音素更好的单元,从分层的语言结构中完成原始语音的声学信息到语义内容的过渡。例如,基于检测(detection-based)和丰富知识(knowledge-rich)的语音识别建模框架,使用了称为“语音属性”(speech attributes)的语音原子单元。而深度学习的方法使得该类识别方法的精度已经得到了很大的提升[332,330,427]。
 (https://www.xing528.com)
(https://www.xing528.com)
图11.6 用16kHz和8kHz采样率混合带宽的声学数据训练语音识别的一个DNN架构
图中词语翻译对照表
在自然语言处理领域,文献[62,63]中阐述的研究是多任务学习最典型的例子。一系列不同的“任务”,词性标注、组块(chunking)、命名实体标注、语义角色辨识和相似词辨识,均可使用一个通用的词表示和一个统一的深度学习方法来完成。在8.2节中可以找到这些工作的一个总结。
最后,深度学习在图像/视觉领域单模态的多任务学习上也是非常有效的。Srivastava和Salakhutdinov[349]等人提出了应用在不同图像分类数据集上的一个DNN系统,这一系统是基于分层贝叶斯先验的多任务学习系统。深度神经网络和先验结合在一起,通过任务之间信息的共享和在知识转移中发现相似的类别,提高了判别学习的性能。具体来说,他们提出了一个联合学习图像分类和层次类别的方法,比如对那些训练样本相对少的“缺乏数据类别”,可以从相似且拥有较多训练数据的“数据丰富类别”中获得帮助。这个工作可以看作是学习输出表示很好的例子,这个例子和学习输入表示都是目前所有深度学习研究所关注的。
Ciresan等人[58]将深度卷积神经网络架构应用到了拉丁文和中文的字符识别的工作中,这是图像领域的单模态多任务学习的一个实例。在中文字符上训练得到的卷积神经网络可以很轻易地识别大写拉丁字母。此外,可以通过先对所有类别上的一个小的子集做预训练,然后训练所有类别,对中文字符的学习进行加速。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。