



先解释一下词向量:将词用“词向量”的方式表示可谓是将深度学习算法引入自然语言处理(NLP)领域的一个核心技术。自然语言理解问题转化为机器学习问题的第一步都是通过一种方法把这些符号数学化。
词向量具有良好的语义特性,是表示词语特征的常用方式。词向量的每一维的值代表一个具有一定的语义和语法上解释的特征,故可以将词向量的每一维称为一个词语特征。词向量是一种词的分布式表示方法,是一种低维实数向量。
例如,NLP中最直观、最常用的词表示方法是One-hot。每个词用一个很长的向量(字典的个数)表示,绝大多数是0,只有一个维度是1,代表当前词在字典中的位置。例如,“话筒”表示为[0001000000000000…]。
但这种One-hot表示的是稀疏矩阵,在解决某些任务时会造成维数灾难,而使用低维的词向量就很好地解决了该问题。同时从实践上看,高维的特征如果要套用深度学习算法,其复杂度几乎是难以接受的。
分布式表示的低维实数向量,如[0.792,0.177,0.107,0.109,0.542,…],它让相似或相关的词在距离上更加接近。它的每一维表示词语的一个潜在特征,该特征捕获了有用的句法和语义特征。其特点是将词语的不同句法和语义特征分布到它的每一个维度上来表示。
再来看看结合深度学习算法的词向量是如何获取的。谈到word2vec的词向量,就得提到两个模型——CBOW(Continuous Bag-Of-Words,即连续的词袋)以及Skip-gram模型。这两个模型都是根据上下文词,来推断当前词发生的概率。可以实现两个基本目标:一是这句话是否是自然语句;二是获得词向量。图10.2示意的是CBOW模型结构,图10.3示意的是Skip-gram模型结构。(https://www.xing528.com)
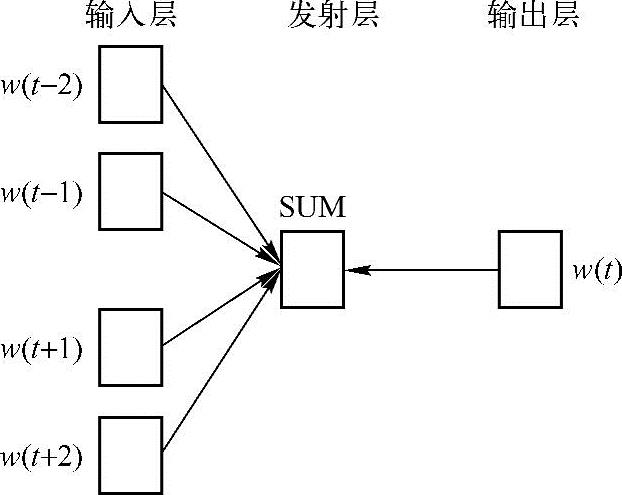
图10.2 CBOW模型结构
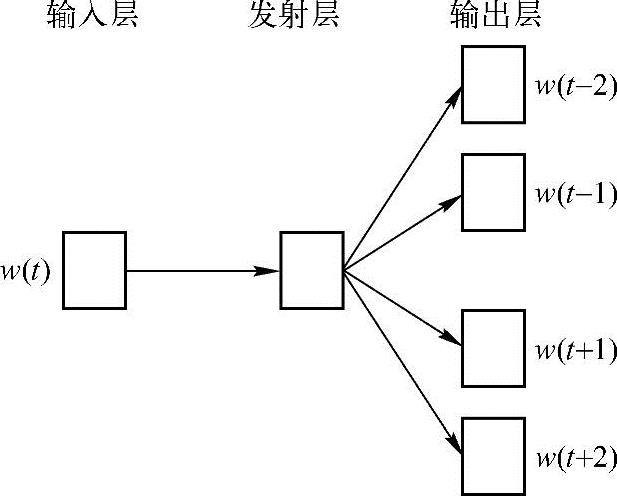
图10.3 Skip-gram模型结构
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。