



Storage的存储由统一接口BlockStore定义,BlockStore是一个抽象类,定义了数据的读写方法。BlockStore抽象类有不同的实现,目前有DiskStore、MemoryStore、ExternalBlockStore三种不同的实现。下面是BlockStore抽象接口的定义。

上面源代码是BlockStore抽象类的定义。putBytes、putIterator、putArray三个接口方法类似,都是按照指定的存储级别存储集合字节信息,getSize方法返回指定blockId对应数据块的长度,getBytes返回指定blockId对应的数据块的字节数组。remove方法移除指定blockId对应的数据,若该blockId存在并且移除成功,返回true,否则返回false。Contains方法用于判断blockId对应的数据是否存在。clear方法是一个钩子方法,在DiskStore和ExternalBlock-Store中不做任何处理,在MemoryStore中用于清除内存中的MemoryEntry,用于释放内存空间。
Storage存储按BlockStore的实现分为三种情况:
1)DiskStore:存储数据到磁盘。
2)MemoryStore:以字节数组或Java对象的方式存储在内存中。
3)ExternalBlockStore:存储数据到OFF_HEAP中,Spark目前的OFF_HEAP默认实现采用Tachyon。
BlockStore是存储模块的抽象,提供了存取数据的基本的抽象方法。DiskStore、Memo-ryStore、ExternalBlockStore都实现BlockStore接口,它们的继承层次类图如图6-3所示。
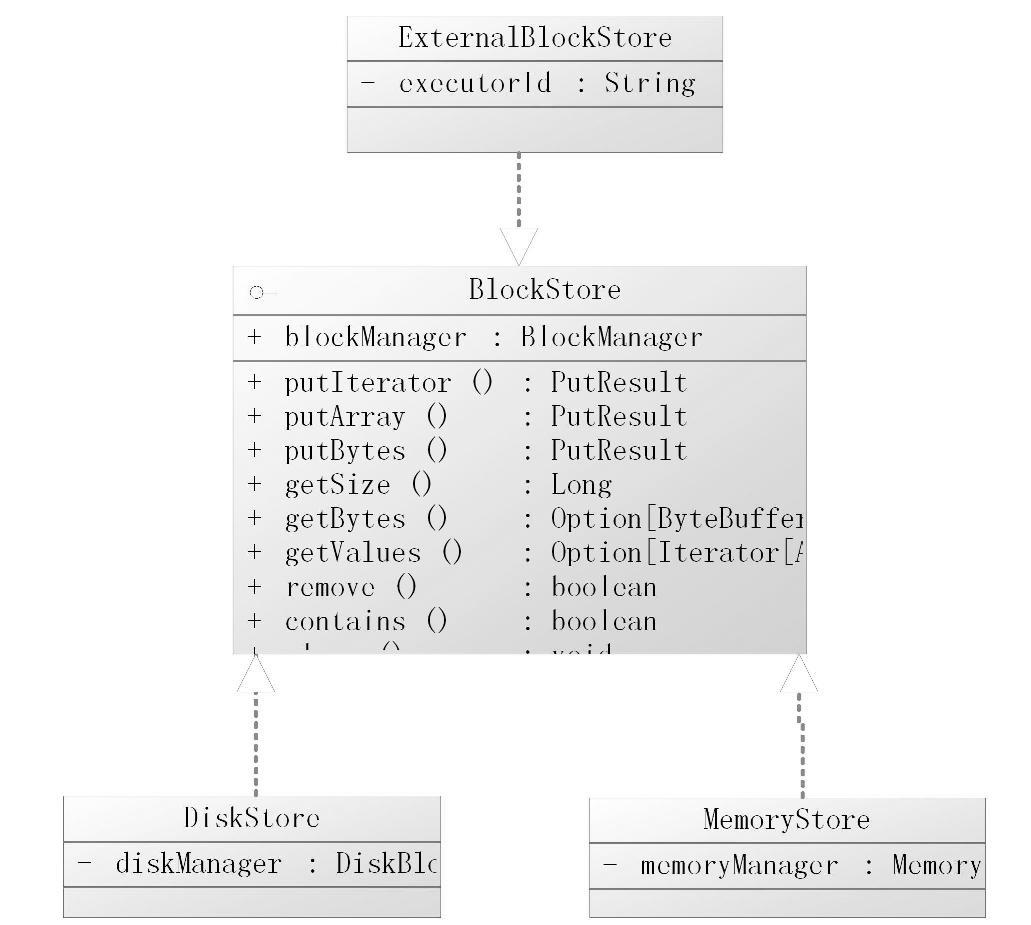
图6-3 BlockStore的继承结构
使用BlockStore时,可以指定StorageLevel,StorageLevel中存放的是一些标志信息,这些标志信息用于判断RDD数据进行何种方式的存储。下面是StorageLevel的部分源代码。


StorageLevel的几个构造参数是_useDisk、_useMemory、_useOffHeap、_deserialized、_replication。在构建StorageLevel的时候,根据传入参数的不同,实例化出不同的StorageLev-el。在Spark中已经预先定义出了很多StorageLevel,例如DISK_ONLY、MEMORY_ONLY等,这些预定义的存储级别可以直接通过StorageLevel对象引用,并且这些预定义的存储级别几乎能满足所有存储情景。
下面分别对BlockStore的三种不同实现:DiskStore、MemoryStore、ExternalBlockStore存储数据进行讲解。
1.DiskStore
顾名思义,DiskStore会将Block存放到磁盘上,要存储数据就需要指定数据存放的路径,怎么设置存放Block的路径呢?在DiskStore中可以配置多个存放Block的目录,Disk-BlockManger会根据这些配置创建不同的文件夹,存放Block。文件夹的命名格式为prefix-UUID的形式,Prefix为指定的文件名前缀(默认为blockmgr),UUID为UUID算法生成的字符串,Block将会存放在所有的创建目录中并保存副本。DiskBlockManger会调用createLo-calDirs方法为Block创建文件夹,源代码如下。

上面代码中,传入SparkConf,通过Utils得到conf中配置的多个文件的根目录,并使用Utils.createDirectory(rootDir,"blockmgr")方法实际创建根目录,这些目录可以通过spark.local.dir配置项配置。下面是Utils的createDirectory方法的源代码。


上面源代码中有一个attempts变量,用于记录尝试创建文件夹的次数,如果dir文件夹为空,将会一直循环处理,直到attempts达到最大尝试次数为止。如果超过最大创建文件夹的次数,将会抛出IOExeception异常。创建文件夹将会以传入的rootDir为根路径,创建文件夹的格式为prefix+"-"+UUID.randomUUID.toString的形式,如果dir存在或者不能够创建目录,则将dir置为null。若没有创建目录的权限,将捕获SecurityException异常,异常处理也是将dir置空,重新进行while循环。
在DiskBlock存储中,逻辑意义上的block和文件有什么关系呢?在DiskBlock中,每一个Block都被存储为一个文件,文件的名称是通过计算BlockId对象中的fileName的哈希值得到的,通过映射得到文件名称之后,将block中的数据写入到文件中。BlockId对象中的fileName与文件路径映射关系的源代码如下所示。


getFile方法首先得到fileName的哈希值,用哈希值对localDirs数组长度做模运算,得到要存放数据的目录ID,用hash值对localDirs数组长度做除运算,结果对subDirsPerLocalDir做模运算得到存放数据的目录中子目录的ID。其中,subDirsPerLocalDir的个数是通过spark.diskStore.subDirectories配置项配置的,默认值为64。如果没有子目录,则创建子目录;如果有则直接返回,subdirs(i)有sbudirs(i)锁保护,防止由于多线程的同时修改而造成数据的不一致。使用哈希映射将文件分配到不同的目录的目的是为了避免顶级目录的inodes过于庞大。
DiskStore实现了BlockManager中存取block的方法,这里以BlockStore抽象类中的put-Bytes(blockId:BlockId,_bytes:ByteBuffer,level:StorageLevel)为例,DiskStore重写的putBytes方法的源代码如下。


上面源代码中,putBytes方法传入blockId、_bytes和level共3个参数,blockId代表BlockId对象,该对象中有一个全局唯一的name属性;_bytes是ByteBuffer类型,里面存放的是字节数据;level表示StorageLevel,代表存储级别。
putBytes方法中通过调用diskManager的getFile(blockId)方法,得到BlockId对象中fileName映射的file路径,然后通过该路径得到File对象,再使用File对象上的输出流通道向文件中写入字节数据,最后返回PutResult对象,它是一个携带此次put操作数据信息的对象。
Block数据存入DiskStore之后,要怎么读取这些宝贵的数据呢?其实想要读取DiskStore中的block数据很简单,只需通过BlockId对象的fileName属性获得对应的哈希映射文件,并从文件中读取数据即可。下面来看一下DiskStore的getBytes(blockId:BlockId,offSet:Long,length:Long)方法,源代码如下。


getBytes(blockId:BlockId)方法中,通过BlockId对象中的name属性,由哈希算法获取映射的文件,并通过getBytes(file:File,offSet:Long,length:Long)读取Block映射文件中的字节数据。对于小于2MB的文件,采用直接读取的方式;对于大于2MB的文件,采用内存映射的方式读取。内存映射方式可以大大提高读取数据的性能,尤其适合读取大文件,这里的minMemoryMapBytes取值默认为2MB。
从getBytes和putBytes两个方法的分析中可以看到,在DiskStore中读取和保存block都是先通过BlockId获得映射的文件,然后通过数据流的形式读取和保存文件的。
DiskStore会将数据保存到磁盘,如果频繁地对磁盘进行I/O操作,必将严重影响系统的性能,正好MemoryStore可以解决对磁盘的I/O操作带来的问题,由于MemoryStore数据是驻留在内存中的,可以直接从内存中读取数据,减少磁盘I/O,大大加快了数据的读写速度,因此MemoryStore可以给系统性能带来巨大的提升。下面就来看看MemoryStore的源代码实现,MemoryStore与DiskStore最大的不同是MemoryStore将block保存在内存中,而Disk-Store将block通过文件的形式保存在磁盘中。
2.Memory Store
MemoryStore中维护着一个LinkedHashMap来管理所有的Block,Block被包装成Memory-Entry对象,该对象中保存了Block相关的数据信息,如大小、是否反序列化等。Link-endHashMap以blockId作为键,blockId对应的MemoryStore作为值,其源代码的定义如下。

MemoryStore中必须要有足够的内存来存放Block,否则将会把Block溢出到磁盘文件中。下面以putBytes方法为例,源代码如下。


putBytes方法中包含BlockId、ByteBuffer、StorageLevel共3个参数,这3个参数的含义与DiskStore中putBytes参数一样。代码行中,通过duplicate方法得到_bytes的副本,以避免在多个地方修改一个变量,造成逻辑上的错误。接下来判断StorageLevel是否为deserialized,如果为true,则进行反序列化,将字节数组反序列化成可迭代的对象,然后调用putIterator方法存入内存;若deserialized为false,则调用tryToPut方法尝试将字节数组中的数据存入内存,tryToPut方法的源代码如下。


在tryToPut方法中,首先调用MemoryManager的acquireStorageMemory方法,判断空闲内存是否足以容纳block。若可以容纳该Block,则将该Block放入内存中的entries这个Linked-HashMap进行管理;若不足以容纳,则通过调用dropFromMemory方法将此Block溢出到DiskStore。
MemoryStore将Block放入Executor内存中,每一个独立的JVM进程都可以分配堆大小(-Xmx和-Xms)。Executor详细的内存模型分析在6.4小节介绍。
接下来讲解如何从MemoryStore中读取Block信息。从MemoryStore中取得Block比较简单,根据blockId从哈希表中取出即可。这里以MemoryStore的getValues方法为例,源代码如下。

getVaults方法接受blockId作为参数,从entries这个LinkedHashMap中查找,如果没有查到该blockId对应的MemoryEntry,返回None,否则再根据是否反序列化得到反序列化之后的数据并返回。
Spark中有3种BlockStore的实现,分别是DiskStore、MemoryStore和ExternalBlockStore,上面谈到了DiskStore和MemoryStore中存取block的操作,接下来看一下ExternalBlockStore中对block的存取操作。
3.External BlookStore
ExternalBlockStore将Block存储在JVM外部的存储系统中,Spark目前实现的External-BlockStore将block存放在Tachyon分布式内存文件系统中。ExternalBlockStore的StorageLevel是OFF_HEAP。
ExternalBlockStore中是如何存取block的呢?仍然以putBytes方法为例,ExternalBlock-Store中putBytes方法的源代码如下所示。

putBytes方法接受3个参数,分别是BlockId、ByteBuffer和StorageLevel,这3个参数的含义同DiskStore和MemoryStore的putBytes方法的参数,分别代表Block对象,Block对应的字节数组和存储级别,这里StorageLevel的取值为OFF_HEAP,该方法返回PutResult对象。在putBytes方法内部调用putIntoExternalBlockStore方法,该方法用于将Block消息存入Ex-eternalBlockStore中,其源代码如下所示。


将Block存放到JVM外部存储系统中,必须借助ExternalBlockManager,首先判断Exter-nalBlockManger是否定义,如果没有定义,则打印出ExternalBlockManger没有定义的信息;如果定义了ExternalBlockManger,调用externalBlockManger.get.putBytes方法将byteBuffer存入外部系统中。
这里提到了ExternalBlockManager,它是一个抽象类,定义了使用外部存储系统存取Block的方法。ExternalBlockManager的源代码如下所示。


ExternalBlockManager抽象类定义了使用外部系统存储Block的基本的抽象方法,由具体存储系统实现。(https://www.xing528.com)
ExternalBlockManager中的init方法用于初始化ExternalBlockManager,该方法有两个参数,第一个参数是BlockManager,第二个参数是String类型的executorId,BlockManager定义了供外部模块调用的公共接口,BlockManager中提供了数据序列化和反序列化的方法,在ExternalBlockManager中可以使用以下几个方法。
·removeBlock,根据blockId删除对应的Block。
·BlockExists,判断blockId对应的Block在外部存储系统中是否存在。
·putBytes,将blockId对应的数据存入外部存储系统。
·putValues,将blockId对应的数据存入外部存储系统。
·getBytes,通过blockId,取出对应的Block。
·getValues,通过blockId,取出对应的Block。
·getSize,返回blockId对应的Block的大小。
shutdown在系统关闭时被调用,用于清理外部存储系统中持久化了的数据,例如,在TachyonBlockManager中,该方法用于递归删除某些保存数据的目录。
目前在Spark中,ExternalBlockManager抽象类只有一个实现,即针对Tachyon的实现,这个实现类是org.apache.spark.storage.TachyonBlockManager,接下来看一下TachyonBlock-Manager中重写的相关方法。
先来看一下TachyonBlockManager中init方法的实现,源代码如下。


init方法中,通过传入的BlockManager中的SparkConf对象取出外部存储的路径,该路径通过spark.externalBlockStore.baseDir配置,并通过SparkConf对象取出Tachyon保存数据文件夹的名称,该名称可以通过spark.externalBlockStore.folderName配置。使用storeDir、ap-pFolderName和executorId拼接成一个数据块存储的根路径。该路径格式为/storeDir/appFol-derName/executorId。通过SparkConf对象取出Tachyon的配置URL,该配置项可以通过spark.externalBlockStore.url来配置。得到Tachyon的master地址之后,通过TachyonFS.get(new TachyonURI(master),new TachyonConf())方法,得到Tachyon分布式文件系统的引用TachyonFS,通过该client,可以非常方便地使用TachyonFS进行创建、删除和存取数据操作。
init方法中另外一个重要的操作是创建目录,首先通过spark.externalBlockStore.subDi-rectories配置项获得子目录的个数,默认情况下为64个,可以通过spark.externalBlockStore. subDirectories配置项来配置。第28行调用createTachyonDirs方法,使用拼凑出来的rootDirs创建目录。创建好目录后,使用subDirectories参数构建一个二维数组,该二维数组有tachyon-Dirs.length行,subDirsPerTachyonDir列。
init方法完成Tachyon目录的创建准备工作,那么TachyonBlockManager是如何存取数据的呢?还是以putBytes方法为例,putBytes的源代码如下所示。

该方法传入两个参数,第一个参数是BlockId对象,该对象中包含name等属性及方法。第二个参数是ByteBuffer数组,为待存储的字节数据。上面源代码的第3行调用getFile方法,得到blockId经哈希映射后的文件,得到文件对象,使用文件上的输出流将字节数据写入文件中。
通过TachyonBlockManager查找Block信息也非常简单,只需传入blockId,在Tachyon系统中找出对应的数据返回即可。这里以getBytes方法为例,源代码如下。


在getBytes方法中,调用getFile方法,找出blockId经哈希函数映射后对应的文件,通过文件的输入流,读出字节数据并返回。
至此,DiskStore、MemoryStore和ExternalBlockStore都已讲解完。在Spark中拥有不同的BlockStore实现,并且这些实现有可能继续增加,为了对用户屏蔽这些内部的细节,并保证Spark今后对不同存储的扩展,Spark Storage模块对外提供了一个统一的方法类BlockManager。在BlockManager中提供了存取数据的方法,不必关心不同Store的具体实现细节,只需通过配置使用不同的StorageLevel,BlockManager就能自动选择不同的存储,并调用该存储的方法。
4.通过BlockManager读写数据
既然BlockManager是一个统一的接口,那么在BlockManager中肯定提供了读写数据的方法,并且在这些方法中会根据不同的StorageLevel,调用BlockStore接口实现类的方法来读写数据。接下来看一下BlockManager提供的读写方法,BlockManager提供了putBlockData方法,用于存储数据,该方法的源代码如下。

该方法有3个参数,第一个参数是BlockId对象;第二个参数是ManagedBuffer,表示待存数据;第三个参数是StorageLevel,用于指定存储的级别。方法中调用putBytes方法,该方法的源代码如下所示。

在putBytes方法中,tellMaster参数用于设置在存入数据后是否通知master,默认为true。还有一个参数是effectiveStorageLevel,设置有效的存储级别,默认为None。require用于检测传入的bytes是否为null,如果为空将以“Bytes is null”作为异常消息并抛出IllegalArgumen-tException异常。putBytes方法主要完成将一个序列化的字节数组存入BlockManager,并返回一个更新后的块列表。该方法中调用了doPut方法,源代码如下。




BlockManager中的doPut是一个很复杂的方法,下面将逐一讲解该方法中的代码。该方法根据StorageLevel设置的值将block存入对应的BlockStore中,如果有必要将会产生并保存副本。
在该方法中,首先检查blockId、storageLevel和effectiveStorageLevel是否为空,如果为空将会抛出IllegalArgumentsException异常并返回。新建一个名为updatedBlocks的ArrayBuffer,该缓存数组中存放一个二维元组,元组第一位存放BlockId对象,第二位存放BlockStatus对象,该updatedBlocks数组用于返回更新后的blocks信息。putBlockInfo代码块中构建Block-Info对象,首先会到blockinfo这个TimeStampedHashmap类型的map中查找blockId对应的BlockInfo是否已经定义,如果没有查到对应的BlockInfo对象,使用storageLevel和tellMaster构建一个BlockInfo,并存入blockInfo中,返回构建好的BlockInfo;如果已经定义了该Block-Info,返回旧的BlockInfo。
如果StorageLevel中配置的replication数目大于1,这种情况下,将在futureExecutionCon-text线程池中启动线程,在线程中进行数据的备份操作。
在putBlockInfo同步代码块中,根据不同的StorageLevel,判断使用不同的BlockStore,并判断是否需要返回值。得到blockStore之后,判断data的组织方式,调用blockStore的具体存储方法实际存储Block数据。
如果tellMaster为true,将调用reportBlockStatus(blockId,putBlockInfo,putBlockStatus)方法,向master报告Block的状态。最后根据StorageLevel中的replication数目产生副本。
在doPut函数中,只需完成以下几项工作。
1)为Block创建BlockInfo,存储block的相关信息。
2)为blockInfo加锁,使其他线程不能访问。
3)根据StorageLevel,将Block存到Memory或Disk或ExternalBlockStore中。
4)解锁blockInfo,使其他线程可访问。
5)根据StorageLevel中的replication判断是否将Block制作成副本存放。
接下来了解一下在BlockManager中是如何获取数据的,首先来看一下get方法,其源代码如下所示。


get方法中,根据blockId,首先调用getLocal方法,从本地blockManager中获得数据。如果获得了数据则返回;如果没有获取到数据,调用getRemote方法,尝试在其他远程blockMan-ager中查找数据,如果找到则返回,没有找到则返回None。Spark中,任务往往是根据block所在位置进行分配的,大部分情况下通过getLocal就能找到blockId对应的数据,但是在资源有限的情况下,任务调度器可能将任务调度到与Block所在结点不同的结点上执行,这种情况下必须通过getRemote方法得到远程Block数据。先来看一下getLocal方法,如下所示。

getLocal方法根据传入的BlockId通过调用doGetLocal方法取得BlockId对应的Block。doGetLocal方法的源代码如下所示。




首先从blockInfo哈希表中取出blockId对应的BlockInfo。如果为Null,返回None;如果info不为null,获取info的synchronize同步块,保证只有一个线程操作该blockInfo。为了保险,再次判断哈希表中该BlockInfo是否被removeBlock方法删除。如果该BlockInfo正在被其他线程写入数据,等待其他线程退出,如果等待失败,返回None。
所有检查条件都通过了之后,根据StorageLevel调用对应BlockStore的方法,查找block-Id对应的Block数据并返回。如果判断StorageLevel使用的是Memory,则调用memoryStore的getValues或getBytes方法查询块数据并返回;如果判断StorageLevel使用的是OFF_HEAP,则调用externalBlockStore的getValues或getBytes方法查找数据并返回;如果判断StorageLevel使用的是Disk,则调用diskStore的getBytes方法查询并返回数据。如果配置了useMemory,查询出来的数据将根据内存情况存入MemoryStore中,以便再次查询时直接从内存中查找,从而加快查找速度。
在本地没有查询到blockId对应的Block数据时,会调用getRemote方法查询远程结点上是否有该blockId对应的Block数据。接下来了解一下getRemote方法,源代码如下。

getRemote方法将通过其他结点上的BlockManager查询block,将查询的结果作为Block-Result实例。在该方法中调用doGetRemote方法。源代码如下。


doGetRemote方法首先会检查blockId是否为空,如果为空,则会抛出以“BlockId is null”为错误信息的IllegalArgumentExeception异常。如果存在blockId,调用BlockManager-Master的getLocations方法,返回存有该blockId的BlockManagerId信息。使用Random.shuffle方法得到BlockManagerId列表,以保证请求的负载均衡。
在for循环中,使用blockTransferService的fetchBlockSync方法异步抓取远程BlockManag-er上对应的blockId数据,该方法可能会失败,失败后将打印失败信息,并转至下一次循环,直到找到数据并返回。如果没有查找到blockId对应的数据,则返回None。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。