



ShuffleExternalSorter类的内部处理过程,可以先从该类在UnsafeShuffleWriter中的使用开始去理解。如果已经熟悉了UnsafeShuffleWriter的大致的写数据过程,可以直接忽略;如果不熟悉,也可以简单地在UnsafeShuffleWriter类中搜索ShuffleExternalSorter类的调用点来获取二进制处理的入口。
下面直接从ShuffleExternalSorter类基于Project Tungsten内存模型处理数据的关键入口点开始解析插入记录(对应ShuffleExternalSorter的在UnsafeShuffleWriter类的open与stop方法中的处理可以暂时忽略),也就是图8-9中的第1步插入记录(insertRecord)。即从Unsafe-ShuffleWriter的insertRecordIntoSorter方法中的相关源代码部分开始,简单源代码如下。

其中第3~5行是解析的关键入口点,也就是ShuffleExternalSorter的insertRecord方法。在该方法中会把当前的serBuffer内容(即一条记录数据)插入到ShuffleExternalSorter中。因此,接下来首先分析insertRecord方法,对应源代码及其解析如下。


处理的大致流程在前面已经给出简单描述,这里主要分析记录是如何存储在内存页(Page)的,即内存页中记录的组织形式,可以通过图8-10来描述。
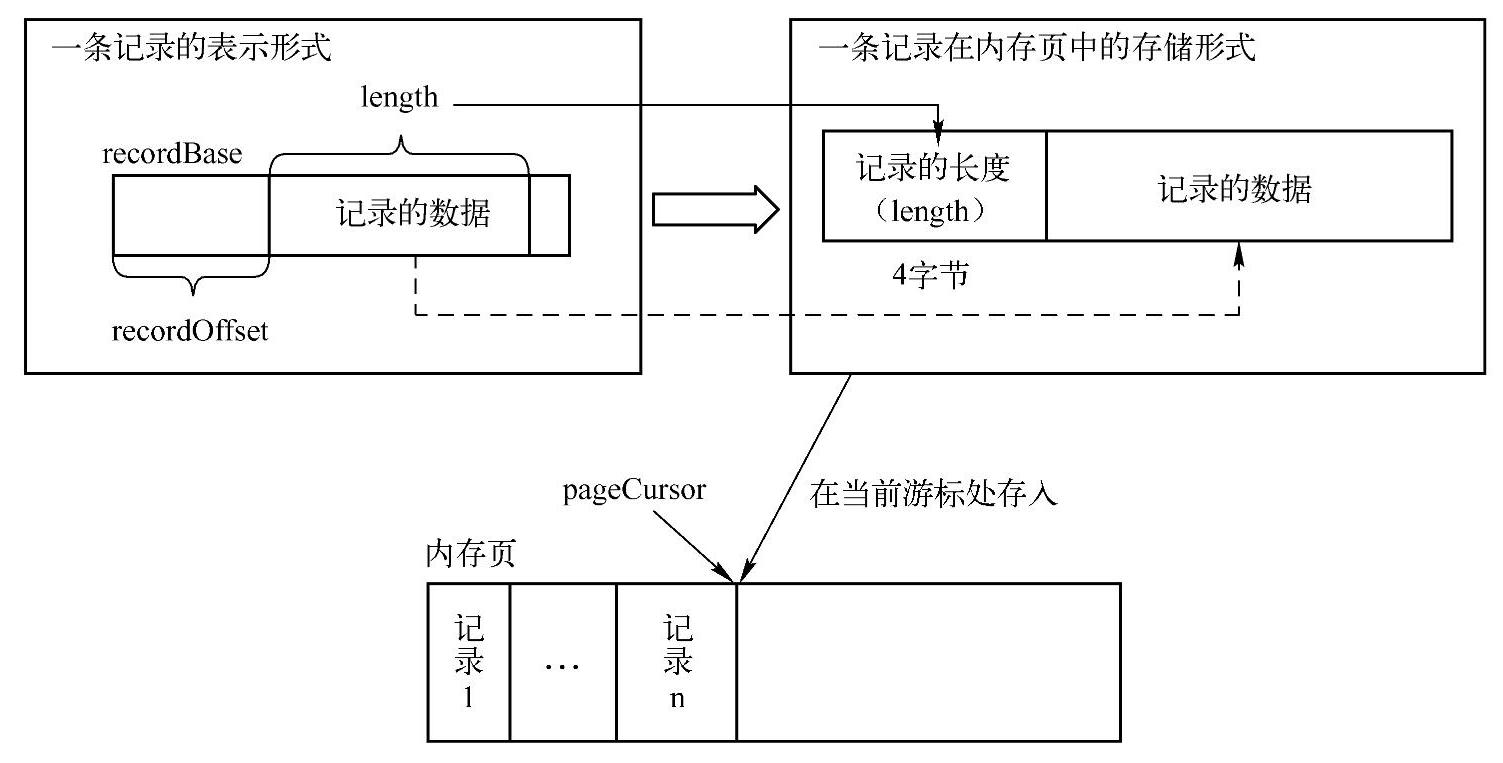
图8-10 内存页中记录的组织形式
将记录存入内存页时,首先是在内存页当前游标(pageCursor)所在位置存放该记录的数据长度(长度long类型对应4字节,因此占用的空间是记录数据的长度+4字节),然后通过描述记录数据信息的三元素,将记录数据复制到数据长度后面的内存页空间中。
描述记录数据信息的三元素如下。
1)recordBase:记录所在的对象。
2)recordOffset:记录在对象中的偏移量。
3)length:记录数据的长度。(https://www.xing528.com)
在处理过程中,通过TaskMemoryManager的encodePageNumberAndOffset方法,将记录在内存页中的存储地址进行编码(存储时已经包含记录的长度和数据,因此只需要起始地址即可),并将该编码地址和所在分区ID一起插入到inMemSorter(ShuffleInMemorySorter)变量中。继续查看插入的信息是如何在ShuffleInMemorySorter中组织的,具体源代码如下。

在插入到ShuffleInMemorySorter时,会将信息重新封装为PackedRecordPointer,然后存放到LongArray中。下面首先给出一个示意图,如图8-11所示。
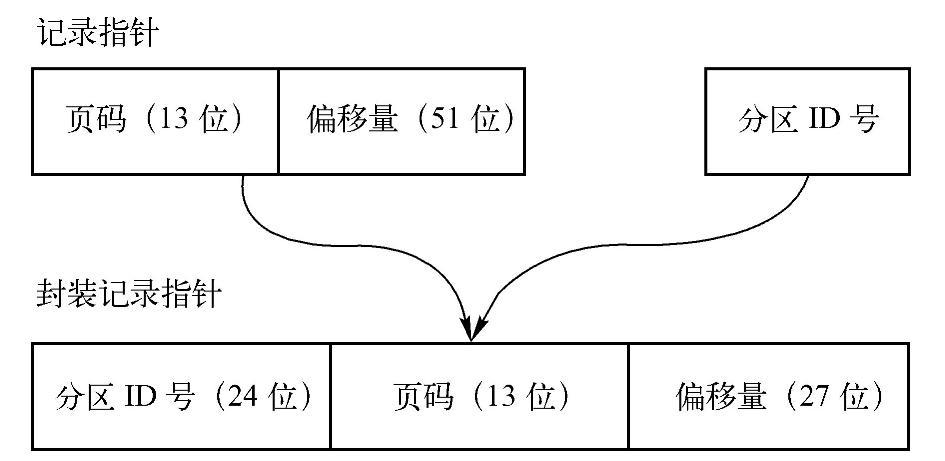
图8-11 PackedRecordPointer封装示意图
最终将记录的编码地址recordPointer通过PackedRecordPointer包装成一个64位的long型地址。即在ShuffleInMemorySorter的LongArray中存放的是重新包装后的地址,从该地址可以看到,地址中包含了分区ID信息PartitionId,该信息是用于记录排序的。对应的页内偏移量也缩成了27位,因此在使用Project Tungsten内存模型时,记录的长度也从原先的231-1变成了227-1(即当记录长度超过该值时,无法使用基于Tungsten的Shuffle机制)。同样,使用时分区的数量也会受到限制,即只能有224-1个分区。
对应在插入数据的过程中,使用的两个方法在某些细节上可能不容易理解,因此这里也给出简单的源代码及其解析。
首先是growPointerArrayIfNecessary方法,具体代码如下。


其次是acquireNewPageIfNecessary方法,具体代码如下。

免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。