



基于文献[518-520],算法复杂度分析只针对那些占绝大多数复杂性运算的模块,并且只考虑中继接收端,这是因为图5.6、图5.7的中继发射端的算法只是接收端中的一个子集,可直接参考对接收端的分析结果。
5.5.2.1 RRC匹配滤波器
匹配码片响应的根升余弦滤波器(RRC)的冲激响应为
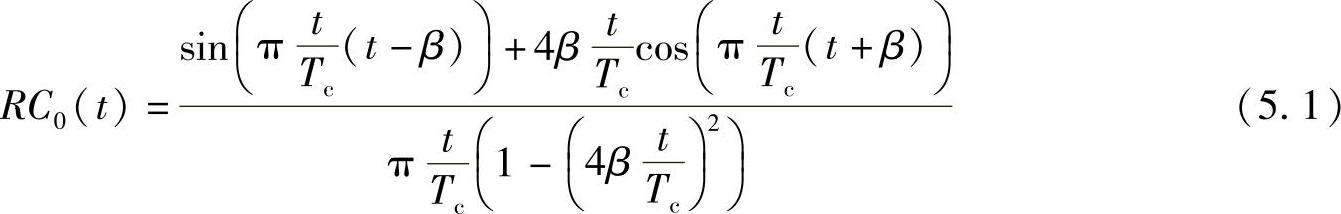
其中,Tc是码片持续时间;β为滚降因子。RRC匹配滤波器一般在数字域用有限个系数来实现,同时这个单元工作在采样级。
RRC匹配滤波器的计算复杂性取决于如下参数:信道时延扩展DS(以码片为单位),用来将叠加的多径分量分别延迟;过采样因子OSF,使信道捕获单元能处理接近路径传输延迟的采样值;每处理周期内码片数Nchips,如Nchips=2560为每时隙内的码片数,共有Nchips×OSF个采样值;Ndata是数据符号的个数,SFdata是数据符号的扩频因子,LRRC是脉冲成型滤波器的冲激响应的长度(以码片为单位),用来对接收信号进行匹配。
在运算操作次数方面,接收信号采样值长度为OSF×(Nchips+LRRC+DS-1)。脉冲成型长度为OSF×LRRC-1个样值,互相关运算输出为OSF×(Nchips+2×LRRC+DS-1)个样值,但是需要参与运算的只有后面的OSF×(Nchips+LRRC+DS-1)个样值。考虑到脉冲成型是实数值的信号,互相关的计算需要2×(OSF×LRRC+1)次实数乘法和2×(OSF×LRRC+1)次实数加法。考虑到边界效应(0值的存在),最后的OSF×LRRC个样值基本不参与运算。最后,总共需要OSF×(OSF×LRRC+1)×(2×(Ndata×SFdata+DS-1)+LRRC)次实数乘法和实数加法。
在Load/Store操作次数方面,需要对接收信号进行OSF×(Ndata×SFdata+DS+LRRC-1)次Load操作,加载脉冲成型滤波器冲激响应需要(OSF×LRRC+1)次Load操作,保存互相关序列需要OSF×(Ndata×SFdata+DS+LRRC-1)次Store操作。
假定每个复数样值用2×16位来表示,计算互相关序列时所需的内存中包括4×OSF×(Ndata×SFdata+DS+LRRC-1)字节来暂存接收信号,8×(OSF×LRRC+1)字节来计算互相关样值,4×OSF×(Ndata×SFdata+DS+LRRC-1)字节来存储互相关计算后的序列。在下面即将讨论的多径干扰消除(MPIC)检测模块中,这些互相关计算输出的序列是一直需要暂存,用来产生第二阶段以及后面的输入。
假定加法和乘法的复杂性相同,那么对于RRC匹配滤波器每个时隙内,总运算复杂度 、总Load/Store操作次数
、总Load/Store操作次数 及总内存需求
及总内存需求 结果如下:
结果如下:

5.5.2.2 信道捕获
搜索器是UMTS接收机中的重要功能模块之一,其作用是区分信道多径分量带来的时延,并据此设定不同的Rake指峰值。在下行链路,CPICH与数据并行发送,但采用相对更高的发射功率,从而使搜索器可从CPICH信道中获得信号延迟。在复杂度分析中,需要明确导频符号数、采样速率、相关窗长度及其他参数。很多估计信道延迟的算法可以改变Rake接收机的性能,但都是以复杂度为代价的。本节选择一种迭代类型的信道捕获过程进行分析,并且假定算法不包括加权多时隙平均类似的信号处理过程。
当开机,会话中断或者切换时,搜索器需要更新所有信道延迟和Rake分配,因此这个过程被称为全信道捕获。与此同时,一旦调制解调器正常开始工作,需要使用短些的相关窗进行上述参数的逐步更新,以降低复杂度,这个过程因此被称为部分信道捕获。这两种信道捕获方式的切换频率主要依赖于通信场景,而且常常被设备制造商直接设定。
全信道捕获和部分信道捕获过程的运算复杂度依赖于以下参数:信道时延扩展DS(即以码片为单位表示的,可分辩出有效多径信号的窗口长度);过采样因子OSF(使Rake接收机能以最近多径延迟的采样值进行处理);数据符号扩频码的扩频因子SF;用于信道捕获的导频的比特数Nbit,pilot;导频的码片数Nchip,pilot(有如下关系:Nchip,pilot=Nbit,pilot×SF/2);脉冲成型滤波器冲击响应的长度LRRC(以码片为单位,用来再生本地导频信号);可分辩的多径信号支路数L;部分信道捕获(道选)与全信道捕获(高复杂度)的执行频率比值Racq。
对于全信道捕获而言,由于接收信号中包括CPICI和用于导频的扩频码与扰码,信道估计必须计算出可用的多径分支数、多径分量基于时隙起始位置的时间延迟以及复衰减值,进而来进行多径分量的删余和估计。通常的做法是迭代进行接收信号与延迟后的、无多径传播的本地理想信号的相关操作,从而挑选出使相关出现最高峰值的时延值。因为发射的导频信号是已知的,所以同时还能确定该径的复衰减增益;这样关于这条多径的时延和衰落就都明确了。最后,在接收信号中减去本地理想信号的加权分量,即消除了这一径的影响后,再以同样的过程来分辩下一条功率较强的径。该算法的复杂度与其他可用的信道捕获方法比较接近。
首先需要产生导频信号。导频序列对于小区或扇区是唯一的,需要经过特定码字的扩频和加扰操作。假设只采用退化的乘法运算的话,导频生成的过程总共需要Nbit,pilot×SF次运算和5/2×Nbit,pilot×SF次Load/Store操作。接下来,导频码片需要通过发送和接收端的RRC滤波器滤波成型,以保证去除加权的本地理想信号是正确的。发送端的滤波器是多相滤波器,按照OSF对码片进行过采样。另外一方面,接收滤波器是全RRC滤波器,复杂度随OSF2线性增长。整个过程需要2×Nchip,pilot×OSF×(LRRC(OSF+1)3/2)+Nchip,pilot次运算操作和LRRC×(OSF+1)+Nchip,pilot(2×OSF×6+LRRC(OSF+1)))次Load/Store操作,计算复杂度较高。为降低整个信道捕获的复杂度,将欠采样的接收信号和本地训练序列进行相关运算,这是因为改为码片级对运算及存取次数产生很大的影响。而且,由于相关运算基于每个样值而非码片上进行,不会导致精度缺失。此外,被检测的多径分量的复衰减值正好就是相关点处的值,所以可以省略了对衰落的估计过程。互相关运算需要SD×OSF×(4×Nchip,pilot+3)×L次运算操作和DS×OSF×(2×Nchip,pilot+1)×L次Load/Store操作。为了保证检测到的相关峰是有效的多径分量,信道估计模块将对比分量中的导频信号进行解调。接收的样值信号经过解扰、解扩然后根据测量的复衰落进行相位旋转。将结果和已知的发送导频序列进行比较,以便估计被检测的多径分量的有效似然度。这一过程需要2×Nbit,pilot×(SF+2)×L次运算操作和Nbit,pilot×SF×L次Load/Store操作。最后从原接收信号中去除有效的多径分量,以进行次强度多径分量的估计。用在此多径分量上估计出的信道衰减值和本地产生的导频序列相乘,再从接收信号中去除这一分量,从而去除了这分量的路径时延造成的相关运算峰值。该过程共需要5×Nbit,pilot×OSF×(L-1)次运算操作和(3×Nbit,pilot×OSF+1)×(L-1)次Load/Store操作。
在内存需求方面,用于存储全信道估计过程的临时存储单元需要确保能够存储包含导频符号的接收信号副本(因为迭代运算过程会将部分信号会从原信号中去除,所以需要保留一份原接收信号样本),若用2×16比特表示复数样值,则需要占用4×(Nbit,pilot+DS)×OSF字节存储单元。相关运算时用于扩频和加扰的导频码片序列需要4×Nbit,pilot字节存储单元,而存储从接收信号中加权后分离的两次滤波的导频信号需要4×Nbit,pilot×OSF字节存储单元。
总之,在假定乘法和加法具有同样复杂度的前提下,全信道捕获过程中总的运算复杂度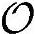 ,总Load/Store操作次数
,总Load/Store操作次数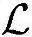 ,总内存需求
,总内存需求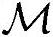 可以用每时隙字节数表示为:
可以用每时隙字节数表示为:
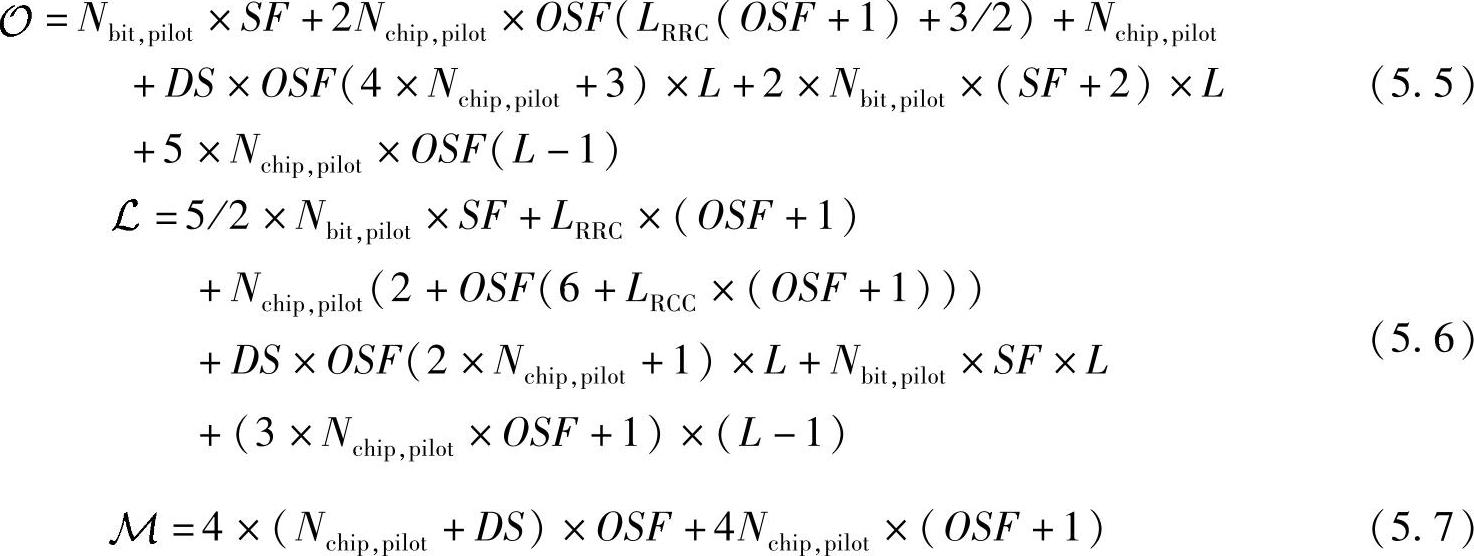
部分信道捕获在一些情况下只包含简单的多径分量估计,以降低整体复杂度,这被称为跟踪或部分信道捕获过程。基于上一时隙的信道估计模型,跟踪模块只针对当前时隙调整时延和复衰减,而不在整个搜索窗口内进行相关运算。对于每条检测出的多径分量,跟踪模块通过在约一个码长度的窗口内进行相关运算,获取需要调整的时延和复衰减值。
从复杂性角度分析,可以假设导频和RRC脉冲成型是在全信道捕获过程中生成和并被存储下来。基于一个码片周期上的相关运算可以降低运行复杂度:只需要L×OSF×(4×Nbit,piolt+5)次运算操作和2×L×(Nbit,pilot×OSF+2)次Lodd/Store操作。同时假定部分信道捕获过程中不需要实现多径分量的有效性确定,从而也就省略了加权和除权过程,保持内存需要和全信道捕获阶段一致。
总之,在假定乘法和加法具有同样复杂性的前提下,全信道捕获过程中总的运算复杂度 ,总Load/Store操作次数
,总Load/Store操作次数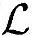 ,总内存需求
,总内存需求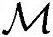 结果如下:
结果如下:
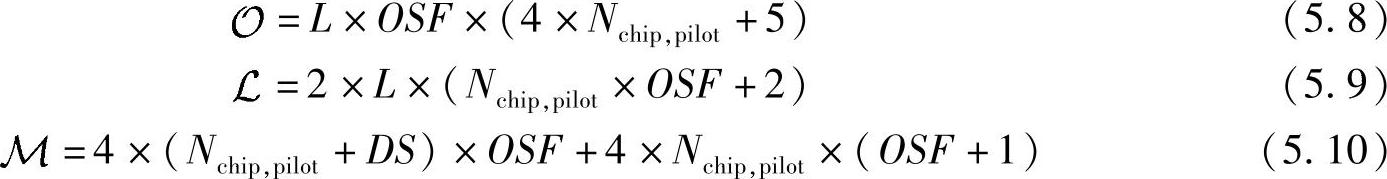
两种不同信道捕获模式的使用次数之比Racq依赖于运行环境和设备商,在给定比值的前提下,总的复杂度可以估计为Racq×全信道捕获条件下复杂度+(1-Racq)×部分信道捕获条件下复杂度。
5.5.2.3 信道估计
信道估计需要在每一条分辨出的多径上执行,因此必须在尽可能低的速率上实现。可选的信道估计途径有:①基于CPICH信道(需要额外进行码片级的解扩操作,但是可靠性较高);②基于嵌入在时隙中的导频符号(不需额外码片级操作,但可靠性降低)。显然我们会选择前者,这是因为CPICH信道比数据传输信道的发射功率更高,因此被接收到的可能性更大。但是有些环境下,如终端在小区边缘时,由于数据信道受功率控制而CPICH信道没有,所以我们选择基于时隙导频的信道估计。
信道估计的计算复杂度取决于如下参数:CPICH的扩频因子SFpilot(SFpilot=256);CPICH的导频符号个数Npilot=10;可分辨的多径分量数目L。基于CPICH信道的信道估计需要进行解扩、导频序列相乘、积分/平均和基于比例因子的缩放等过程。解扩数据序列和导频符号序列的复共轭相乘,以对基于CPICH的信道复系数进行估计,对生成的码片序列的样值进行求和,然后将结果再乘上一个因子进行缩放。
运算复杂度方面,由于码字(信道和扰码)都取自于QPSK调制符号集,一次复数乘法只需要两次实数加法来实现。对于CPICH解扩操作,需要2×Npilot×SFpilot×L次实数加法。对于导频序列相乘,需要2×Npilot×L次实数加法。积分(实际上就是求和)需要2×Npilot×L次实数加法。每个Rake分支的缩放操作需要2×L次实数乘法。
Load/Store操作方面,解扩过程中需要对每个多径分量执行加载接收到的导频的操作,因而需要Npilot×SFpilot×L次Load操作。加载所有的码字需要Npilot×SFpilot次Load操作。解扩后,CPICH数据需要通过Npilot×L次Load操作重新加载。导频数据符号的加载需要Npilot次Load操作。最后,输出的信道增益估计需要通过L次Store操作指令来存储。(https://www.xing528.com)
内存需求方面,信道增益系数是串行顺序进行估计,即一个系数后是另外一个系数。因此,存储解扩后的数据并不是根据所估计的系数个数,而仅仅需要4×Npilot个字节。存储最后估计的信道增益系数需要4×L字节的内存。
总之,假定乘法和加法具有同样复杂度的前提下,信道估计过程中总运算复杂度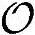 、总Load/Store操作次数
、总Load/Store操作次数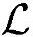 以及总内存需求
以及总内存需求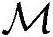 结果如下:
结果如下:

注意,对于MPIC检测器来说,这些操作对于MPIC的每一级都是一样的,甚至对于最后一级也如此。但是,每一级只执行一次上述操作,这是因为操作的次数不依赖于信道估计迭代过程中的循环次数。
5.5.2.4 MRC与MPIC符号检测器
一般来说检测器决定了接收机的主要性能。检测器的作用就是借助搜索器提供的辅助信息,从码片流中提取出符号数据流。检测与估计的理论已经被广泛深入地研究过,很多算法都为了降低复杂度而牺牲了部分性能。
显然最大似然检测(ML)算法是最佳的方案,它遍历所有可能的发射序列,并与处理后的接收数据进行比较,然后判决最有可能发送的信号序列。其依据是最大化η=‖x-Fs‖2R-1,这里x是输入数据流;F是检测滤波器,包括扩频码和扰码的因素;s为候选信号流,其中使得η值最小的就是最大似然解;R是时空相关矩阵。很明显这样的算法复杂度随着序列长度和调制阶数的增加呈指数增长,算法会十分复杂。还有一些检测算法通过牺牲性能来降低算法复杂度,如下面介绍的最大比合并(MRC)和MPIC算法。
上述两种检测算法的计算复杂度依赖于以下参数:数据的扩频因子SFdata(如HSDPA中为16);每时隙内符号个数Ndata(如HSDPA中为160);CPICH信道中导频符号的扩频因子SFdata=256;每时隙内CPICH的导频符号数Npilot=10;用户的瞬时信道码MC;可分辨的多径数L;最大信道延迟W(以码片为单位);MPIC中每级信道估计的迭代次数R;MPIC的级数LRRC。
MRC检测是最简单的一种检测器,基于单天线的Rake接收机和最大比合并的原理来实现。这种接收机被归类为线性接收机,在检测过程中忽略了多址干扰(MAI)。图5.6给出了经典的Rake接收机结构,在模数转换输出采样数据流之前都属于射频模块部分。数据流接着被送入到根升余弦滤波器进行匹配滤波,然后被送入捕获单元进行多径分量间的相对时延估计。捕获单元将估计的时延提供给各Rake分支,Rake接收机对输入数据流进行延时并以码片速率进行采样。然后,对数据和导频进行码片级的解扩和解扰操作,并分别在每个符号长度上对码片进行求平均。CPICH符号用来估计复信道系数,从而根据MRC算法计算合并加权系数w,这里有w=h,h是相应多径分量上信道系数估计。合并加权系数w的复共轭被乘到解扩后的符号数据流上,最后Rake分支的输出加起来送到符号估计和外部调制解调器。
MRC符号检测的复杂度估计如下:Rake接收机首先对接收数据进行解扩后,再对Rake各分支输出进行最大比合并,其复杂度的计算和信道估计类似,相关操作需要2×Ndata×SFdata×L次实数加法,积分需要2×Ndata×SFdata×L×MC次实数加法,比例因子乘法需要2×Ndata×L×MC次实数乘法,信道补偿需要2×Ndata×L×MC次实数加法和4×Ndata×L×MC次实数加法。
在Load/Store操作方面,为了进行解扩操作需要加载各多径分量上的码片级的接收数据,这需要Ndata×SFdata×L次Load操作。加载所有的码字需要Ndata×SFdata次Load操作(对于多码字的情况,信道并不需要对每个时隙都加载一次,只需要在发送时加载即可)。加载信道增益系数需要L次Load操作。最后,为了存储解扩后的数据流(以符号速率)需要Ndata×L×MC次Store操作。
内存量需要方面,存储解扩后的符号需要Ndata×L×MC字节空间,另外,需要存储每次的Ndata×MC字节的数据符号估计值。
总之,假定乘法和加法具有同样复杂性的前提下,MRC检测过程中总运算复杂度 、总Load/Store操作次数
、总Load/Store操作次数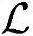 以及总内存需求
以及总内存需求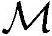 结果如下:
结果如下:
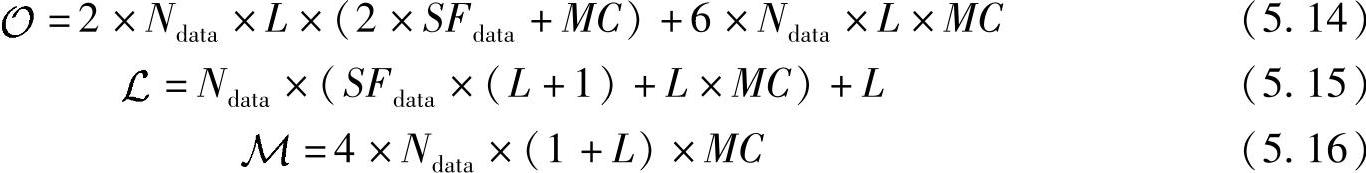
由Higuchi等人[518]提出的MPIC检测器具有非常好的性能,但同时复杂性也很高。它主要由多级信道估计和干扰重构单元(CEIGU)构成,在第二级及以后的各级中,从输入信号中减去前一级对多径干扰(MPI)的估计值。以Il(p)来表示在第p级(1≤p≤P)估计出的第l径的干扰信号(称为多径干扰重构,1≤l≤L)。原始接收到的信号先直接送入MPIC的第一级中,从第二级开始在第p级需要将上一级的多径干扰估计值(不包括当前径)从接收信号中减去,然后作为本级输入。CEIGU的结构在文献[518]中介绍和讨论过,在CEIGU的每一级中,每个天线接收到的样值序列经过匹配滤波器(MF)进行解扩以分辨出多径分量,要注意的是,此时的解扩操作实际上还包括解扰操作。信道估计则是基于一般导频序列和数据包,并结合相应的判决反馈数据来实现。每一径的相位变化需要通过补偿后再进行Rake合并。多径干扰则是使用判决数据序列和信道估计来重构。由于每一级都对信道估计和判决数据进行更新,随着数据判决错误的减少和信道估计的提高,多径干扰的重构会更准确。在每一级的每次迭代过程中,需要重新进行信道的译码和再编码操作,计算将变得很复杂。虽然如果不进行信道译码/再编码的过程得到的结果也可以接受,但是严格来讲,Turbo信道编译码需要整个外部调制解调器参与到整个译码和编码过程中。要注意的是,在这里MPIC复杂度的估计忽略了编码阶段。
MPIC的复杂度计算是非常复杂的,但在文献[518]中给出了推导。总体来说,在乘法和加法具有同样复杂性的前提下,MPIC检测器中总运算次数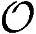 、总Load/Store操作次数
、总Load/Store操作次数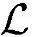 以及总内存需求
以及总内存需求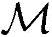 结果如下:
结果如下:

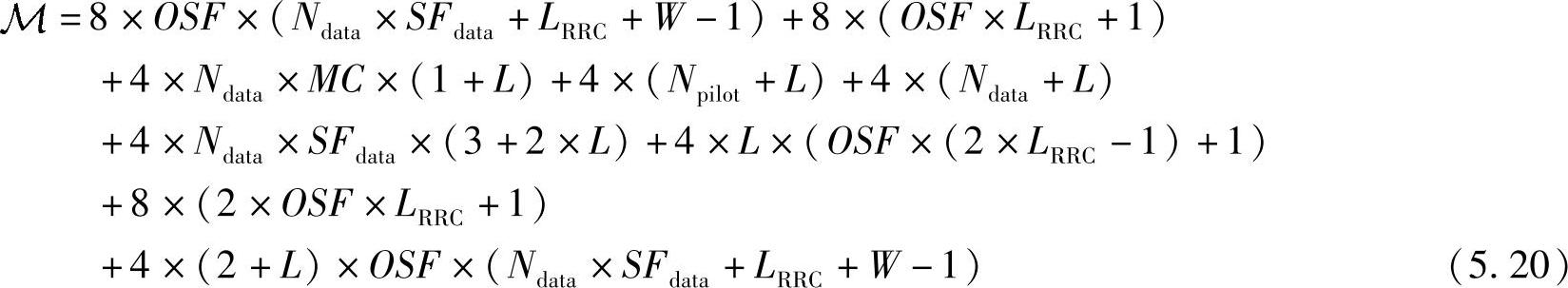
需要注意的是,QPSK和16QAM的计算复杂度是不同的。
5.5.2.5 外部调制解调器
中继的外部调制解调器执行以下操作:软解调、物理信道解映射、第二次解交织、业务信道解复用、分段重组、第一次解交织、速率匹配、信道译码、比特到字节转换,以及CRC计算。
对于复杂度评估,要注意HSDPA的外部调制解调器与前面给出的功能有所不同。然而,因为基带的复杂度主要是信道译码部分产生的,所以可以假定两者的复杂度是一致的。另外,循环索引(DSP中是硬件循环)开销是没有考虑在内的,而且在解交织的过程中,直接假定交织器已经在内存中,数据只需要按行写入一个二维矩阵然后按列读出即可,忽略了交织器产生的过程。为了实现专用信道中继的操作,需要专用控制信道(DCCH)。DCCH的大小为100 bit,采用1/3码率卷积码进行编码,但是当经过CRC后DCCH长度变为360bit。需要注意的是,我们只考虑了专用业务信道的译码复杂度,而忽略了专用控制信道译码。另外,假定交织器的长度为20 ms;需要注意HSDPA中采用了更短的交织器,但并没有明显降低外部调制解调器的复杂度。
外部调制解调器的复杂度评估取决于下面的参数:Nrx(物理信道解映射前接收到的发送块的比特数);NTTI发送块TTI包括的时隙个数,如对于20 ms的TTI,Nslot,TTI=30,对于HSDPA,Nslot,TTI=3);信道编码码率Rc;DTCH的删余度Rp,dtch;DCCH的删余度Rdcch,Tur-bo译码器的迭代次数Niter。注意上述参数不是相互独立的,比如采用1/3码率,那么NTTI=Nrx/3。
为估计复杂度,仅仅需要根据3G的外部调制解调器接收机协议栈,使用前面介绍的对与内部调制解调器模块进行推导的方法就可得到。假定乘法和加法的复杂度相同,那么在使用卷积码时每个发送块所需要的运算操作次数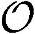 、Load/Store操作次数
、Load/Store操作次数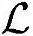 以及所需要的内存字节数
以及所需要的内存字节数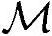 可计算如下:
可计算如下:
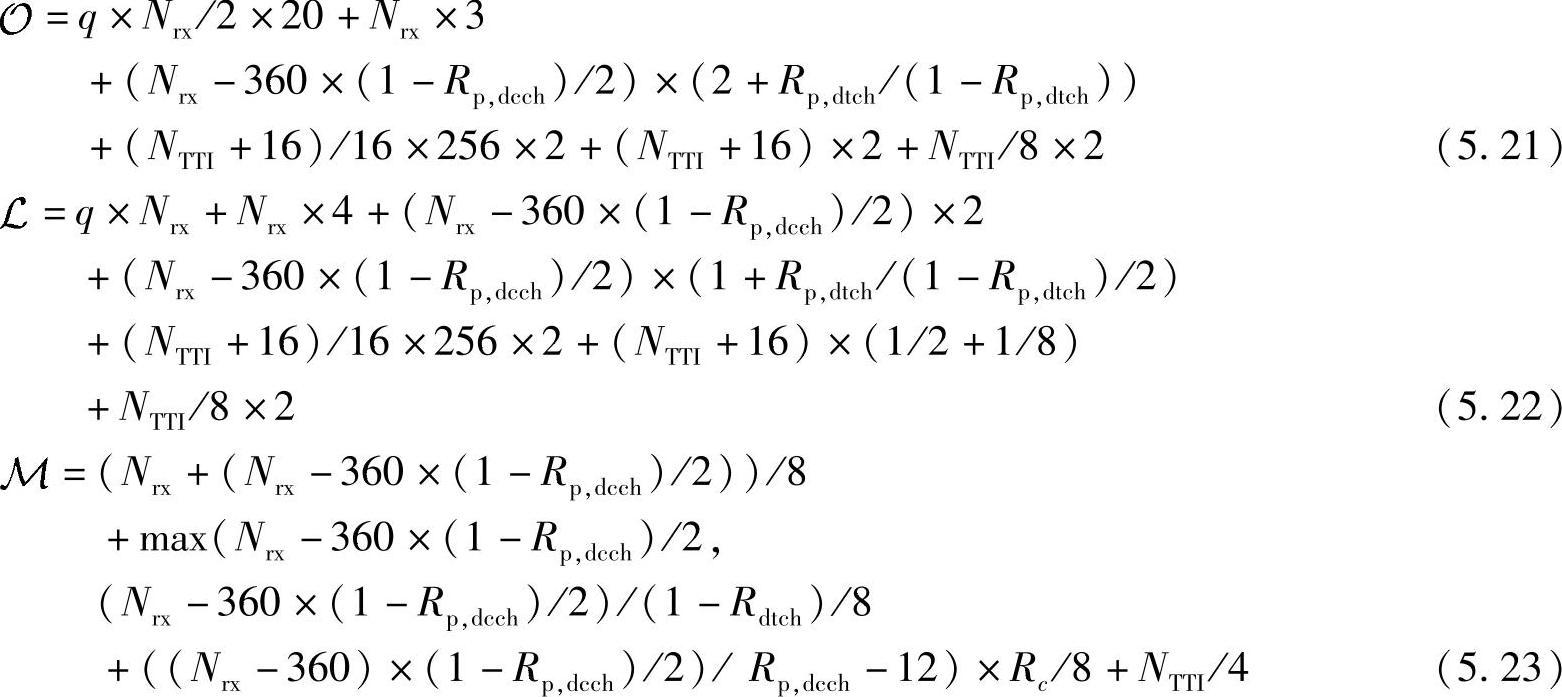
这里,对于QPSK来说q=1,对于16QAM来说q=4。为了获得一个时隙内的复杂度估计,就需要将上述结果除以每个发送块包含的时隙个数Nslots,TTI。
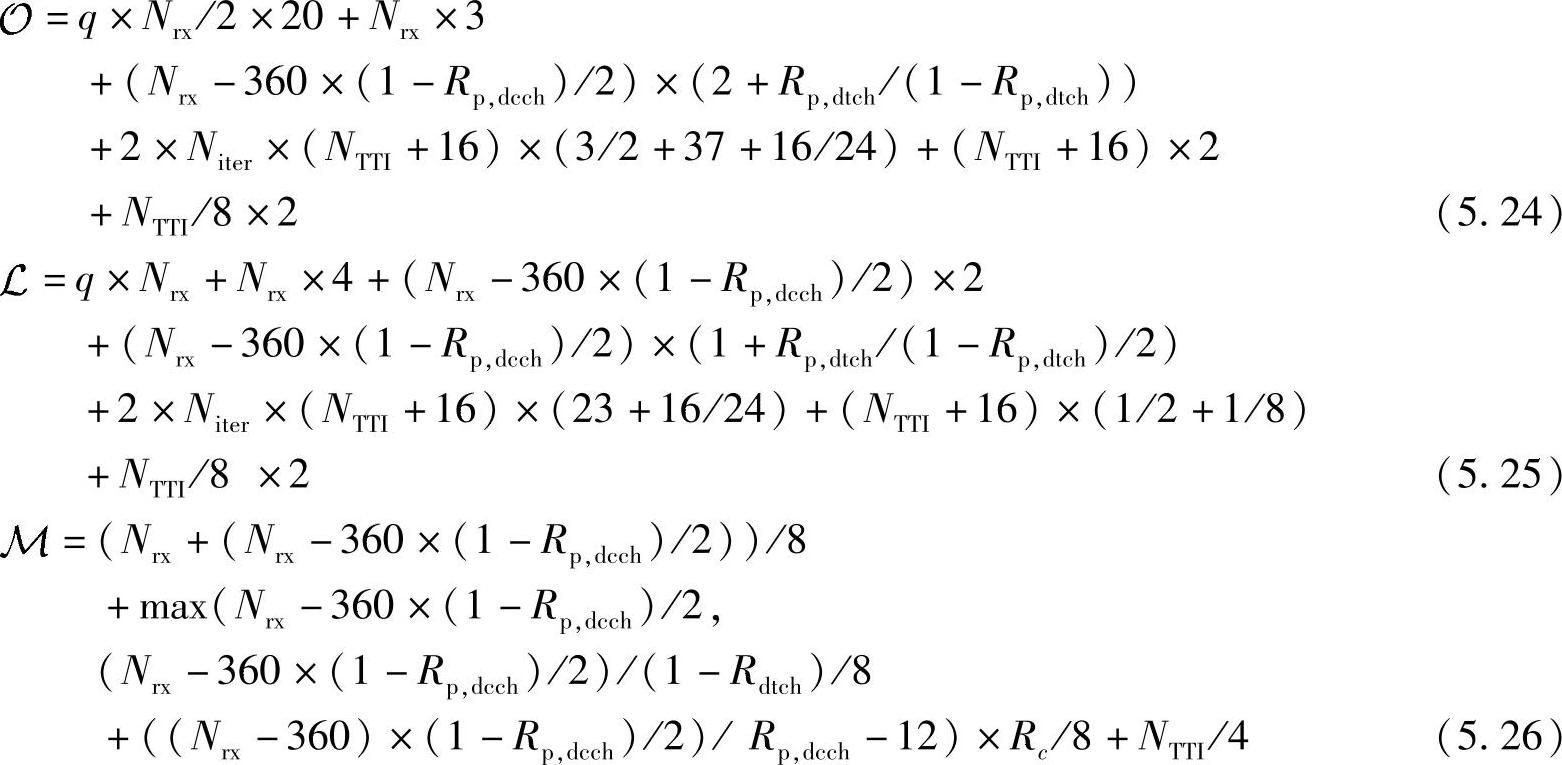
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。