



BP(back propagation)神经网络通常是指基于误差反向传播算法的多层前向神经网络,它是D.E.Rumelhart和McCelland及其研究小组在1986年研究并设计出来的。BP算法已成为目前应用最为广泛的神经网络算法,据统计,有90%的神经网络应用是基于BP算法演化而来的。
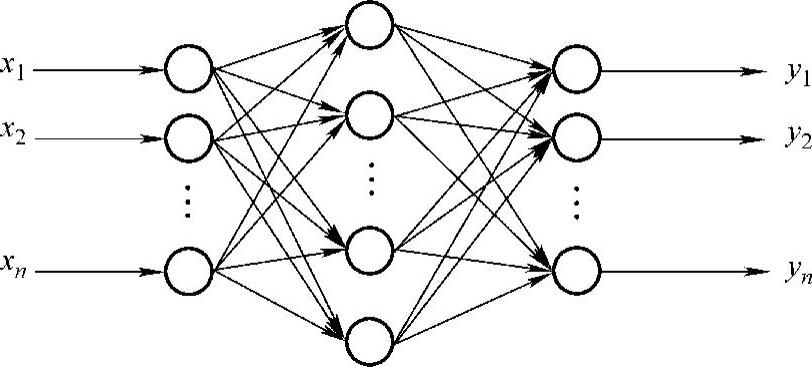
图9-7 BP神经网络
BP神经网络是一种具有三层或三层以上节点的单向传播的多层前馈网络。上下层之间各神经元实现全连接。BP神经网络的神经元采用的传递函数通常是Sigmoid型可微函数,它的输出神经元采用的是线性传递函数,一个最简单的多层多神经元的BP神经网络如图9-7所示。理论上已经证明,这样的BP神经网络,只要有足够的神经元数目,就可以以任意精度逼近任何一个非线性的映射函数。
1.误差反向传播算法
误差反向传播算法,即BP算法的基本思想是最小二乘法。它采用梯度搜索技术,以期使网络的实际输出值与期望输出值的误差均方值为最小。BP算法的学习过程由正向传播和反向传播组成。在正向传播过程中,输入信息从输入层经隐含层逐层处理,并传向输出层,每层神经元(节点)的状态只影响下一层的神经元的状态。如果在输出层得不到期望的输出,则转入反向传播,将误差信号沿原来的连接通路返回,通过修改各层神经元的权值,使误差信号最小。
设BP神经网络的结构如图9-7所示,有n个输入节点。输出层有n个输出节点,网络的隐含层有l个节点,wij是输入层和隐含层之间的连接权值,wjk是隐含层和输出层节点之间的连接权值,隐含层和输出层节点的输入是前一层节点的输出的加权和。令某一输入样本X={x1,x2,…,xm},相应的网络目标量为Ys={ys1,ys2,…,ysn}。
(1)信息的正向传播过程
隐含层第j个神经元的输出为
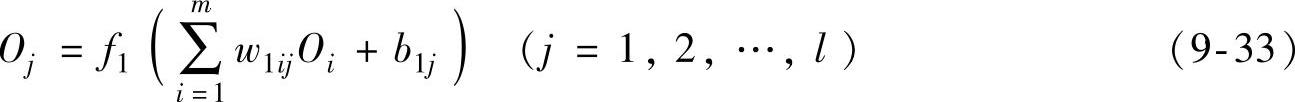
输出层第k个神经元的输出为
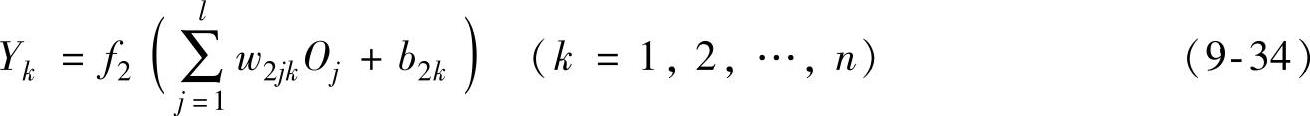
输出层第k个神经元的输出误差为

(2)权值变化与误差的反向传播过程权系数的修正公式为

式中,η为学习速率,且η>0。权值改变为
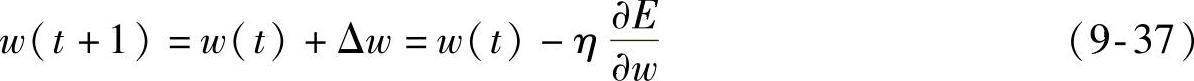
(3)输出层的权值变化 对于第j个输入到第k个输出的权值调整量为
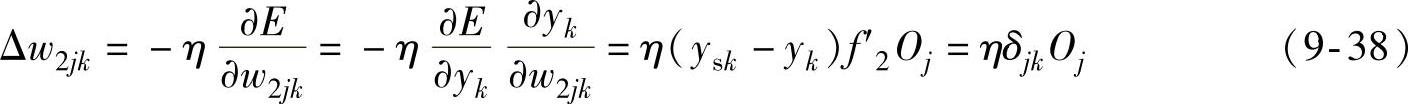
式中,δjk=(ysk-yk)f′2=ekf′2,ek=ysk-yk。同理输出层阈值改变量Δb2k为
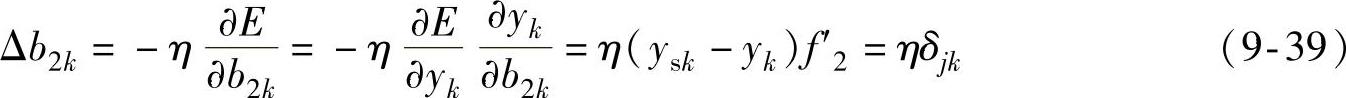 (https://www.xing528.com)
(https://www.xing528.com)
(4)隐层权值变化 对于从第i个输入到第j个输出的权值调整量为
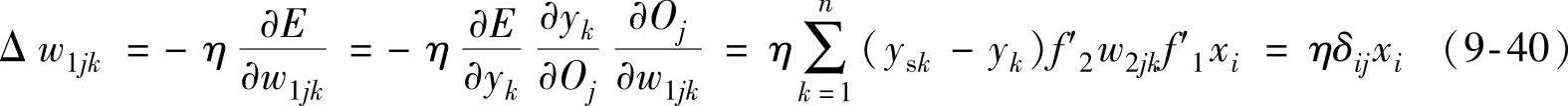
式中,δij=eif′1,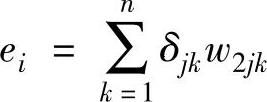 。
。
同理可得
Δb1j=ηδij (9-41)
基本BP算法是一种最简单通常也是收敛速度最慢的算法,它只能用于解决一些简单的问题,很难用于工程实际问题,因此必须对基本BP算法进行改进。
2.LM算法的基本原理
LM算法是BP神经网络的一种优化算法,它是牛顿法和保证收敛的最速下降法之间的一个折中,所以在实际应用中得到较广泛的推广。LM算法的思想是根据迭代结果动态地调整阻尼因子来改变收敛方向,从而达到使误差下降的目的。其优点在于网络权值较少时收敛非常迅速,可以使学习时间较短。设xk表示第k次迭代的权值和阈值所组成的矢量,新的权值和阈值组成的矢量xk+1可由下面表达式求得:
xk+1=xk-[JT(xk)J(xk)+μkI]-1JT(xk)v(xk) (9-42)
其中设E(x)是误差平方函数v(x)的和,即
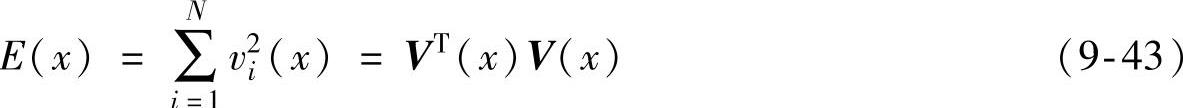
所以梯度为
▽E(x)=2JT(x)v(x) (9-44)
式中,J(x)为雅可比矩阵,可表示为

LM算法的一个非常有用的特点是:当μk增加时,它接近于有小的学习速度的最速下降法:
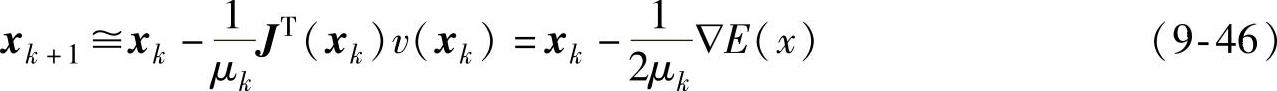
对于小的μk,当μk下降到0的时候,LM算法变为
xk+1=xk-[JT(xk)J(xk)]-1JT(xk)v(xk) (9-47)
式(9-47)的数学表达式也是牛顿算法的另一种变形,即高斯-牛顿算法,它的优点是不需要计算二阶导数。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。