



1.粗糙集理论
1982年,波兰科学家Z.Pawlak[47]提出粗糙集(Rough Sets,RS)。粗糙集理论有着强大的数据处理功能,对各类不完备信息,如不精确(imprecise)、不一致(inconsistent)、不完整(incomplete)问题依然是非常有效的工具。该理论一经提出就受到各界专家学者的普遍重视,此理论之所以能够处理不完善信息得益于使用者成熟的数学基础、不需要先验知识;另一方面在于该理论的易用性。粗糙集理论处理数据信息的原理比较直观,就是直接对数据信息样本进行分析和推理,从中发现数据中潜在的有用信息,找出数据中隐藏的规律,其属于数据挖掘或知识发现方法中的一类,与其他数据挖掘技术与方法,如基于概率论方法、模糊理论方法及证据理论等处理同类型不确定性问题相比,其只需提供待处理的不明确信息的知识,而且不需要其他额外的先验条件,以及与其他相关处理类似问题的理论存在互补性,这即为该理论的优势所在。再制造过程质量控制存在的不确定性问题,即再制造质量异常与引发因素之间的不确定性,刚好能被粗糙集的理论知识完美解决。同时,为了更好地处理再制造过程的质量数据,前期需要对再制造过程进行知识的公式化表达。知识表达系统的基是由再制造过程质量数据的集合为基础构成的,关于再制造过程的知识是依据再制造过程质量的基本特征(属性)和其特征值(属性值)来表达的。因此,某一数据表可以用公式表达为知识系统DT,具体以式(6-38)表示:
DT=<U,C∪D,V,f> (6-38)
式中:DT表示一个决策表;U∶U={x1,x2,…,xn}表示再制造过程质量的非空有限集合,称之为论域;C∪D∶C={β|β∈C}称为条件属性值,每个βi∈C,1≤i≤m称为C的一个质量属性,D={d|d∈D}称为决策属性集,C∩D=Φ,C≠Φ,D≠Φ;V∶V=∪Vβ(β∈C∪D)是信息函数f的值域;f∶f={fβ|fβ:U→Vβ,∀β∈C∪D}表示决策表的信息函数,fβ表示再制造质量属性β的信息函数。
若ind(C)⊆ind(D),称为决策表是相容的,即说明两者是一致或者协调的,式中ind(C)表示条件等价类,ind(D)表示决策等价类。
(1)知识、范畴和近似空间 假设A和B是两个集合,a∈A,b∈B,则(a,b)称为一个序偶。序偶中的两个元素a、b的位置是一定的,交换位置就变成另外一个序偶。当A和B属于同一集合时,直接从该集合中选取两子集构成序偶。
对于集合A和B,其所有序偶(a,b)构成的集合称之为A和B的笛卡儿乘积,记作A×B,以式(6-39)表示:
A×B={(a,b)|a∈A,b∈B} (6-39)对于笛卡儿乘积A×B中任意一个子集称为A到B的一个关系,记为R。
论域U中任意一子集X⊆R称为U的一个概念或者范畴。
对于给定的一个非空集合U定义为论域,R是U的等价关系,则二元组合L=(U,R)称为一个近似空间(approximation space),L称为U的一个知识基(knowledge base)。
(2)等价与不可分辨的关系 根据属性集意义的描述,具有等价关系的聚类称之为等价类。
为了方便再制造过程的数学推导,一般使用等价关系来表述分类,且两个概念可以互相代替。所以在实际再制造过程中,不是针对某一个具体过程而是论域U中的分类。论域U中的分类族构成了U上的知识库,其中某一特定的知识是论域上的一个分类。
定义:对于随机选取的子集X,Y⊂U,若根据等价关系R,X和Y在论域U上是不可分辨时,记为ind(R),其中子集X和Y属于等价关系R上的一个范畴,具体表示以式(6-40)表示:
[X]R=U|R=U|ind(R) (6-40)
式中,[X]R表示等价关系中的一种等价类。
当某一不可分辨关系是由属性集P表达时,属性集P⊂R,且P≠Φ,则∩P(P中全部等价关系的交集)也是一种等价关系,称为P上的不可分辨关系,记为ind(P),因此,等价关系中一个不可分辨等价类以式(6-41)表示:
Xind(P)=∩[X]R,P⊂R (6-41)
当不可分辨关系由属性集P表达时,属性集P⊂R,对象X,Y⊂U,当且仅当f(X,a)=f(Y,a)时,a∈X,Y,P是不可分辨的,以式(6-42)表示:
ind(P)=|(X,Y)⊂U:所有的a∈P,f(X,a)=f(Y,a)| (6-42)
不可分辨关系具有以下几点性质:
自反性:(xi,xj)∈R(1≤n≤i)。
对称性:(xi,xj)∈R⇒(xi,xj)∈R(∀i,j≤n)。
传递性:(xi,xj)∈R,(xj,xk)∈R⇒(xi,xk)∈R(∀i,j,k≤n)。
不可分辨关系ind(P)可表达为U|ind(P)或者U|P。如果R中任意基本集合都是互不可变,以对象c1,c1∈U为例,若两者都属于相同的基本集合Xj,即c1,c1∈Xj,则两对象具有相同的描述:
Des(c1)=Des(c2)=Des(Xj)
(3)集合近似与粗集的概念 粗糙集理论的相关基础概念包括分类和范畴,范畴的概念是指论域中的特征子集对对象的描述,其是指在知识库中获得的知识。此外,某一范畴在一个知识库中是可定义的,但在另外一个知识库中有可能就是不可定义。在讨论的论域U中,存在子集X⊂U,定义R为一等价系。当某一子集X能用R属性集准确描述时,能通过R上一些基本集合的并来表达,称X是在R上是可定义的;反之,为不可定义的。R上的可定义集称之为R的精确集,而R的不可定义集称之为R非精确集,即为R粗集。
假设给定的知识库l=(U,R),对于每一个子集X∈U,等价关系R⊂ind(l),集合X的划分可以通过等价关系R的基本集合的描述进行。对于每一个X∈U的集合,为了衡量根据集合Yi⊂U|ind(R)来描述集合X的情况,因此,对于粗集的近似地定义,使用两个精确集,即粗集的上近似集R-(X)和粗集的下近似集R_(X)进行描述。粗糙集的概念具体描述如图6-7所示。
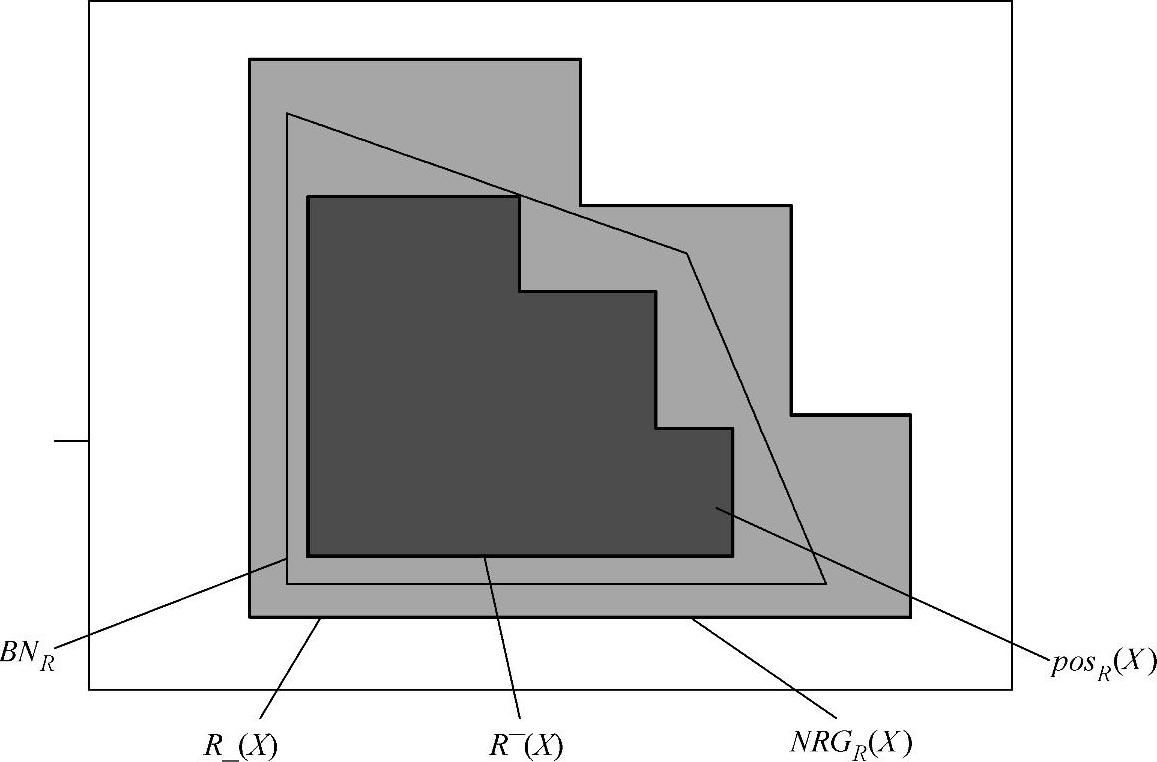
图6-7 粗糙集概念示意图
R-(X)=∪{Yi⊂U|ind(R):Yi⊂X}
R-(X)=∪{Yi⊂U|ind(R):Yi∩X=Φ}
式(6-43)称为X的R正域:
posR{X}=R-(X) (6-43)
式(6-44)称为X的R负域:
NRGR(X)=U-R-(X) (6-44)
式(6-45)称为X的R边界:
BNR{X}=R-(X)-R-(X) (6-45)
下近似集R-(X)或正域是由依据知识等价关系R,判断X中属于论域U中元素的集合组成;同样,上近似集R-(X)是由依据知识等价关系R,判断X中属于或者可能属于论域U中元素的集合组成;边界域BNR{X}是依据知识等价关系R,即不能判断肯定属于X,又不能肯定不属于X的论域U中的元素集合构成;负域NRGR(X)是由肯定不属于X的论域中U的元素集合组成。
(4)知识的约简 对于给定的一个知识库l=(U,R),以及知识库中的一个等价关系族P⊆S,∀R∈P,如果ind(P)=ind(P-{R})成立,则称知识R为P中不必要的,反之,这说明R为P中必要的。
对于每一个R∈P,如果R都为P中必要的,则称P为独立的,否则称P是依赖的或者不独立的。对于任意R∈P,若R满足ind(P-{R})≠ind(P),则称R为P中不必要的,P中所有必要的知识组成的集合称为P的核,记为CORE(P)。核实具有唯一性的特征的。
假设Q∈P,如果Q是独立的,且ind(Q)≠ind(P),则称Q为P的一个约简。显然,P有多个约简。
核与约简的关系以式(6-46)表示:
CORE(P)=∩RED(P) (6-46)
从式(6-46)可以看出,知识的核等于知识所有约简的交集,这说明知识的核包含在知识的每一个约简之中,属于约简中的一个基础部分。核作为知识特征中最重要的一部分,在知识约简过程中是绝对不能被删除的,否则将会削弱知识的分类能力。
为了更好地表达集合之间的近似程度,引入近似度的概念。定义等价关系R关系描述近似程度以式(6-47)表示:

式中,card(R-(X)),card(R-(X))分别表示R-(X),R-(X)的势,即R-(X)和R-(X)集合中元素的个数。
2.基于粗糙集的再制造过程质量异常诊断
再制造产品的质量主要受再制造过程中各种关键过程参数的影响。再制造过程参数在实际加工过程中的任何异常变动,都会出现各种各样有质量缺陷的产品。再制造过程的复杂性与其存在的各种不确定性对再制造过程的产品质量产生较大的影响,所以如何实现再制造过程质量异常诊断并提出调整方案使得再制造过程恢复正常是一个重要难题。
再制造过程的质量主要以工序的形式传递,影响再制造过程质量的因素主要有以下几个方面[48]。
1)人员因素:是指参与制造过程的操作工、质检员、配料员等工作人员的业务水平、受教育程度、身体条件等各方面的因素。
2)设备因素:是指再制造过程使用的机床、检测设备的精度、安全性及可靠性,刀具的材质与精度,夹具的精度与磨损,以及生产过程中的辅助设备的精度及磨损等因素。
3)材料因素:是指再制造过程使用的废旧毛坯、原材料、辅助材料的力学性能与精度,如尺寸要求、硬度、表面粗糙度等因素。
4)方法因素:是指再制造过程采用的加工工艺、修复方法、检测方法等的准确性与可靠性。
5)环境因素:是指再制造过程中有关的环境因素,如温度、噪声、湿度等微气候因素。影响再制造产品质量的因素有很多,将一些次要的、偶然因素忽略,主要从5M1E五个方面入手考虑。在此仅罗列出比较常见的几种原因,如图6-8所示。
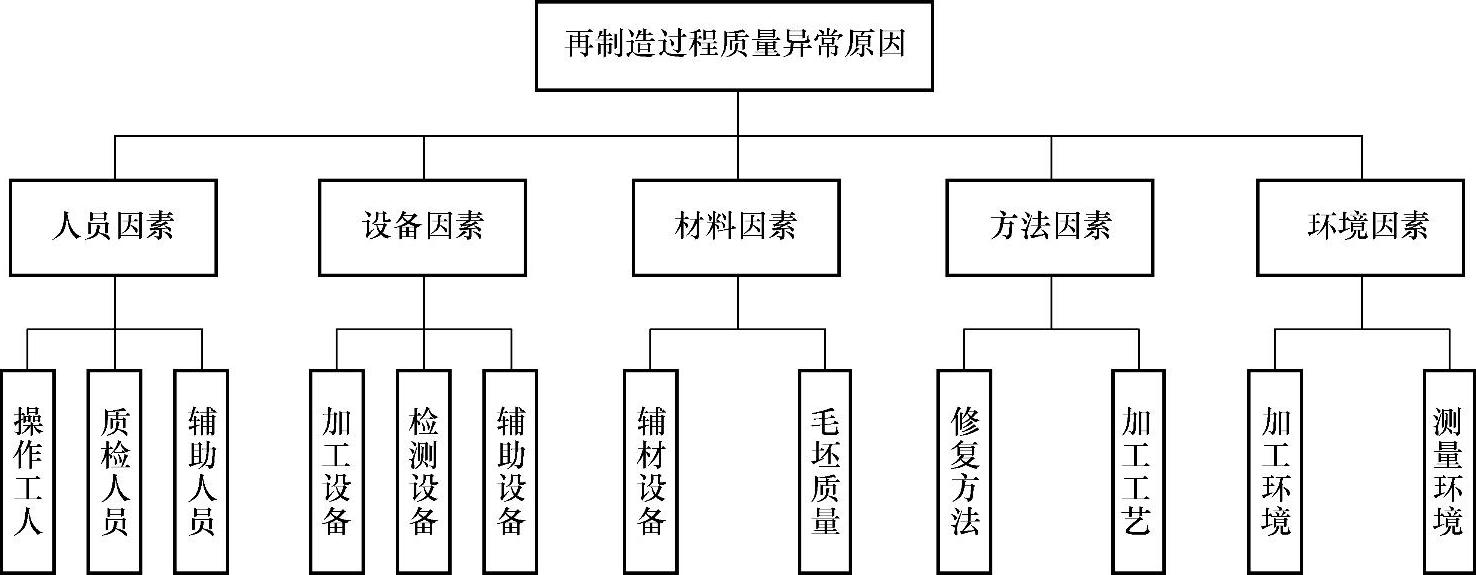
图6-8 再制造过程质量异常原因(https://www.xing528.com)
当检测出再制造过程出现异常,但对于何种原因引发的这次质量异常,还需要进一步溯源。这种溯源的过程就称为再制造过程的质量异常诊断。基于粗糙集的再制造过程质量异常诊断是利用粗糙集理论计算条件属性(质量影响因素)相对于决策属性(质量特征)的重要度。诊断过程的核心思路是指当再制造过程出现质量异常时,根据影响因素的重要度的大小,从大到小依次考虑,对异常原因进行溯源。具体的过程如图6-9所示。
根据两种质量概念[49]可知,依据再制造过程分析,总质量是在上一道工序加工完成后的半成品(它的特征值反映了上道工序的影响水平)的基础上。经本工序的再一次加工后综合而成的产品质量。分质量只是总质量的一部分。分质量与上道工序没有关系的,要想将上下工序之间的这种联系切断,要从再制造过程的分质量入手,进而实现其质量控制,达到简化分析的目的。因此,通过利用两种质量的知识理论分析问题时,关键所在是对其分质量进行分析。
以再制造过程某一特定生产为例,过程的每一道工序都有自己的分质量,将每道工序的加工质量与前期的工序质量叠加在一起,构成了总质量,因此,各道工序都存在两种质量。当在技术方面与上道工序无关的工序,或者在无须考虑原材料输入影响的第一道工序的情况下,两种质量是相等的(但这不是说两种质量不存在)。
某一具体再制造过程有n道工序,定义X0为原始材料的质量属性值,Xi={xi1,xi2,…,xin},i=1,2,…,n,为影响再制造过程工序i的生产质量的因素集,即为前文所叙述的5M1E。工序i的质量特征用Yi,这里Yi既表示工序i的质量特征的输出值,又表示工序(i+1)的输入值。定义Yn为再制造产品最终的质量特征值。
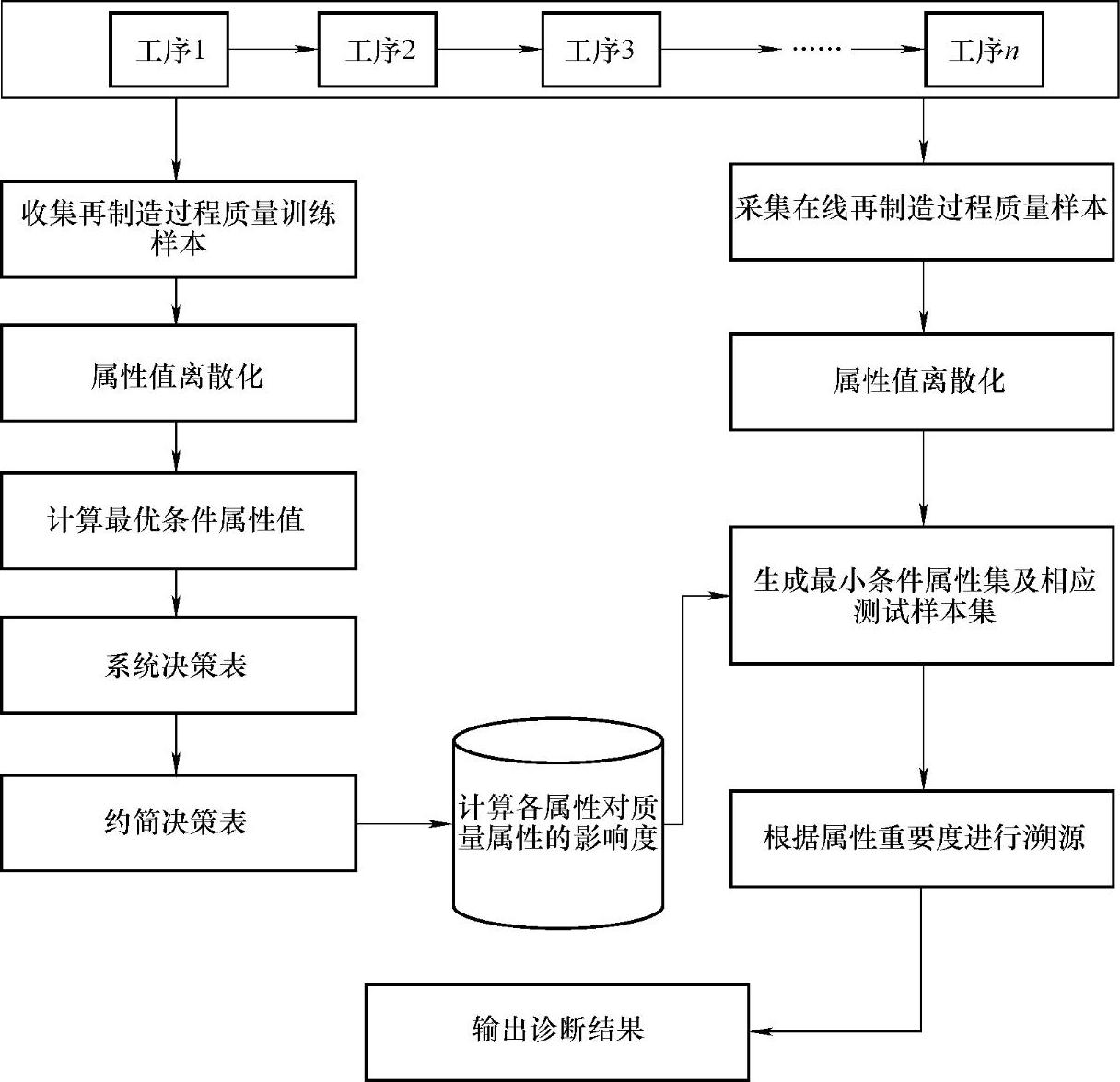
图6-9 再制造过程质量异常诊断流程
对于整个再制造过程,Xi={X0,X1,…,Xn}为影响最终再制造产品质量特征Yn的因素集[50],如式(6-48)表示:
Yn=f(X)=f(X0,X1,…,Xn) (6-48)
根据上述两质量的概念,再制造工序i的质量由上一道工序对本道工序的影响Yi-1和本道工序时产品本身的质量的Xi决定,如式(6-49)表示:
Yi=fi(Yi-1,Xi) (6-49)
而在实际再制造过程中,并不需要为每一道工序都设立相关的质量监控点,只需要将对再制造过程质量产生重要影响的重点工序作为质量控制点。设再制造有m个工序质量控制点,其对应的再制造质量特性分别为Y1∗,Y2∗,…,Yk∗,…,Ym∗,若质量监控点k-1和监控点k间的生产子系统k有Xl∗,Xl∗+1,…,Xl∗+s个工序,令Y∗(k)={Xl,Xl+1,…,Xl+s},则生产子系统过程k有Y(∗k)=fk∗(Y(∗k-1),Xk∗)。
根据两质量的知识理论,再依据用户和实际再制造过程生产的质量分析需求,可针对不同过程(整个再制造过程、单个工序或若干个工序组成的生产子系统)建立相对应的质量影响方程。
为了更好地处理再制造质量数据,需要对再制造过程质量诊断系统进行描述,即为知识的表达。知识的表达系统基本成分是研究对象,即再制造过程质量数据的集合,关于这些再制造过程的知识是通过再制造过程的基本特征(属性)和它们的特征值(属性值)来表达的。
基于粗糙集的理论知识,实际再制造过程中影响再制造过程质量的因素作为决策系统的条件属性,再制造质量的特征作为决策属性,即条件属性集由表征原材料(或再制造上道工序分质量)和影响再制造过程每道工序质量的5M1E数据(即X)组成,决策属性是指再制造过程总质量特征的数据。
综上所述,再制造过程质量诊断系统可分为三个子系统,即再制造产品质量诊断决策系统、工序质量诊断决策系统、再制造子系统质量诊断决策系统。
1)再制造产品质量诊断决策系统以式(6-50)表示:
P=(U,{X0,X1,…,Xn}∪Yn,V,f) (6-50)
式中:U表示再制造系统的集合;{X0,X1,…,Xn}∪Yn=R表示属性集合;{X0,X1,…,Xn}表示条件属性集;Yn表示决策属性集;V表示属性值的集合,通常为连续性,需进行转化,变成离散型;f表示一信息函数,即f:U×R→V表示为指定U中的一个对象x的属性值。以上述Yn=f(X)=f(X0,X1,…,Xn)为例。
以决策表来表达此决策系统,具体见表6-6。
表6-6 再制造产品质量诊断系统决策表

2)工序质量诊断决策系统以式(6-51)表示:
Pj=(U,{Yj-1,Xj}∪Yj,V,f) (6-51)
式中:U表示研究对象的集合;{Yj-1,Xj}∪Yj表示属性集合;{Yj-1,Xj}表示条件属性集;Yj表示决策属性集。
同样,此决策系统依旧用决策表来表达,具体见表6-7。
表6-7 再制造过程工序质量诊断子系统决策表

3)再制造子系统t质量诊断决策系统以式(6-52)表示:
Pt∗=(U,{Y(t-1)∗,Xt∗}∪Yt∗,V,f) (6-52)
式中,U表示研究对象,即再制造子系统的集合,{Y(t-1)∗,Xt∗}∪Yt∗表示属性集合,{Y(t-1)∗,Xt∗}为条件属性集,Yt∗为决策属性集合。Xt∗=(Xl,Xl+1,…,Xl+s)。同样,用决策表来表述该决策。具体见表6-8。
表6-8 再制造子系统t质量诊断子系统决策表

根据粗糙集的理论知识可得,给定一个决策表DT=<U,C∪D,V,f>,对于∀B⊆C,∀β∈C及∀α∈C-B,定义以式(6-53)~式(6-55)表示
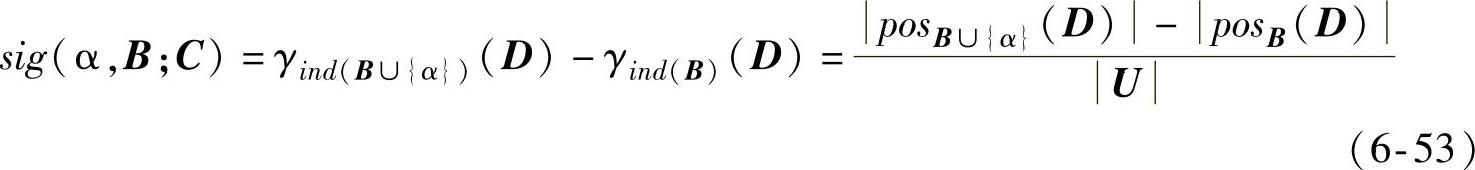
式中,sig(α,B;C)为条件属性α对条件属性集B相对于决策属性D的重要性。
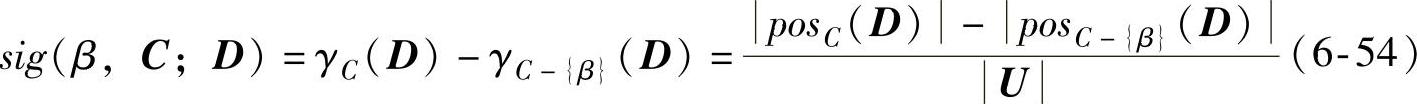
式中,sig(β,C;D)为条件属性β对条件属性集B相对于决策属性D的重要性。
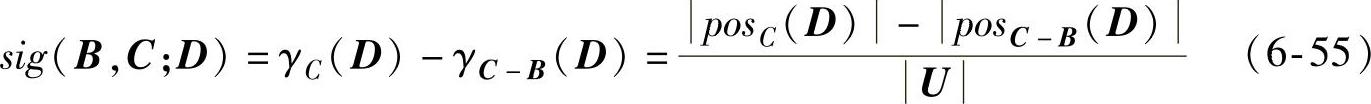
式中,sig(B,C;D)为条件属性B对条件属性全集C相对于决策属性D的重要性。
再制造过程质量诊断实质过程为计算条件属性(再制造过程质量影响因素)相对于决策属性(再制造过程质量特征)的重要性,当再制造过程产品出现异常时,首先从重要性大的影响因素入手进行溯源。
3.再制造过程质量异常诊断的具体过程
再制造过程质量异常诊断的具体计算过程如下:
1)输入:决策表DT=<U,C∪D,V,f>
步骤1:计算C相对于D的核CORED(C);
步骤2:令B=CORED(C),如果CORED(C),转到步骤5;
步骤3:对于∀ci∈C\B,计算属性重要度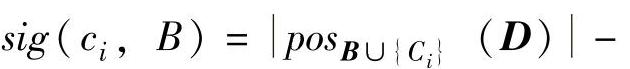
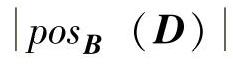 ,求得
,求得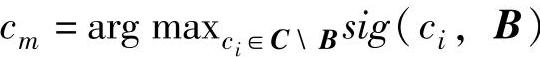 ,如果存在多个属性满足最大值,从中选取一个与B属性值组合数最少的属性为cm。令B=B∪{cm};
,如果存在多个属性满足最大值,从中选取一个与B属性值组合数最少的属性为cm。令B=B∪{cm};
步骤4:当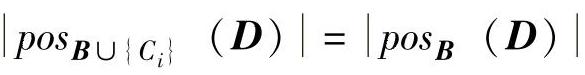 ,回到步骤3,否则转到步骤5;
,回到步骤3,否则转到步骤5;
步骤5:输出B∈REDC(D),本次计算结束。
2)输出:条件属性C相对于决策属性D的一个约简B∈REDC(D)。
再制造过程质量具体的诊断算法步骤如下:
1)收集原始再制造质量数据,从中选取训练样本集,建立初始的决策表;
2)对数据中连续属性进行离散化处理并消除冗余样本,获得离散的信息表;
3)约简再制造过程的条件属性;
4)计算不同的条件属性对决策属性的重要度;
5)当再制造过程出现质量缺陷时,按照上述计算的重要度,从高到低,对条件属性(质量影响因素)进行分析,得出诊断的结果。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。