



现在构建社会网络所采用的方法大多是基于两个实体名字在网络上的共现特征。但是共现状态只能说明两者可能存在关系,不能确定二者是否有直接关系,更不能给出具体的关系描述,因而参考文献[14]提出了基于内容的关系抽取方法,很好地弥补了这一点。此方法在对输入文章进行分词标注、共指消解等预处理之后,通过名词合并及主动词识别,得到存在关系的实体之间的关系指向和关系描述,最后通过有向图把存在关系的实体进行链接,最终形成有向关系网络。这样不仅能够通过对一个新闻事件的分析得到对事件中实体之间关系的指向,更能根据关系图中每个点的出度、入度确定各个实体在事件中的重要程度,而且可以确定点与点之间的相对关系紧密程度,并给出比较合理的点与点之间关系的描述。本方法的主要贡献如下:
首先,本方法是基于文本内容分析的,不仅仅依靠实体的共现信息,得到的社会网络更加可靠。
其次,本方法不仅仅局限于对人与人之间的关系进行抽取,而是对所有的不同实体之间的关系进行抽取。
最后,本方法中采用有向图对社会网络进行可视化表现,对实体之间关系的描述更加详细。有向图中不仅仅标注出实体之间是否有关系,而且标注出实体之间的关系指向,并给出了实体之间相互作用关系的描述词。
1.方法框架
本节提出的方法的整体框架如下:对于输入的单个文档或者一个主题的相关文档集合,首先进行文档预处理,主要是进行分词,标注以及命名实体的指代消解。然后把经过预处理的文档,根据句义完整性进行语篇划分,对划分之后的各个话语片断再进行主动词及其施事论元和受事论元的识别,然后把施事论元和受事论元之间进行有向连接,并进行关系动词的标注,这个关系动词即此话语片断的主动词。最后把处理得到所有实体关系进行合并得到整个事件中实体间的关系网络。
2.预处理
为了进行关系抽取,首先应该对输入的文档进行预处理,这包括分词、标注以及实体的指代消解。在分词、标注过程中,使用中科院计算所研制的基于多层隐马尔可夫模型的汉语词法分析系统ICTCLAS对输入文档进行分词及标注。而在指代消解部分,为了保证社会网络抽取的准确性和系统实现的简洁性,这里使用了两种方法对文中出现的普通代词和零代词进行了有针对性的消解。
(1)命名实体识别(Named Entity Recognition)及指代消解技术研究现状。新闻信息处理第一个重要的方面就是要对新闻进行命名实体识别,以及指代词的消解。因为在网络新闻五大要素中有三个要素属于命名实体的范围。
命名实体识别是最基础的信息抽取技术,也是机器翻译、信息检索、问答系统等自然语言处理应用领域的重要基础工具。一般来说,常规命名实体识别的任务就是识别出文本中的人名、地名、机构名、时间、数字五类命名实体。汉语命名实体识别最初是从单一类型的命名实体开始研究的。孙茂松等人最早进行了我国人名的识别研究[15],主要采用了统计方法;郑家恒和Tan Hongye等人也以统计为主的方法进行了人名、地名的识别[16,17];2001年,张艳丽等人[18]开始采用统计与规则相结合的策略进行汉语机构名称的识别。在五类命名实体中,时间和数量表达式相对比较容易,基本采用规则的方法,汉语命名实体的研究主要集中在人名、地名和机构名上。第六届和第七届MUC评测会议中,H.H.Chen[19]和新加坡肯特岗数字实验室(Kent Ridge Digital Labs)[20]参加了MUC-7汉语命名实体识别任务的评测。参考文献[19]采用了规则和统计相结合的方法,中国人名和外国人名使用局部统计特征进行识别,地名和机构名采用规则方法识别。参考文献[20]采用了隐马尔可夫模型,状态转移概率反应了实体的上下文模型,发射概率反应了实体内部特征。参考文献[21]提出基于类的语言模型,采用了词类之间的三元语言模型进行命名实体识别。参考文献[22]运用角色标注模型对汉语命名实体进行识别,并实现了分词、词性标注、命名实体识别的一体化标注。参考文献[23]在已有工作的基础上,充分挖掘了不同层次的上下文特征,采用了统计模型和专家知识相结合的方法,在新闻语料上取得了较好的识别效果。
现在对命名实体识别的准确度已经很高,也有不少开源的命名实体识别算法,所以本文中不再研究命名实体识别,而是把重点放在与实体有关的指代消解方面。
指代消解是自然语言处理的重要内容,在信息抽取中,指代消解就是一个关键问题[24-27]。同样,信息检索、文本摘要中也存在大量的需要消解的指代问题[24,28,29]。近20年来,指代消解受到了格外的关注,大多数计算模型和实现技术都是这一时期出现的。1997年的EACL和1999年的ACL年会都设立了指代消解的专题会议,2001年的Computational Linguistics学报还出了指代消解的专辑。但在汉语处理方面,指代问题的研究相对较少[30-33]。
指代一般分成两种情况[34],回指和共指。所谓回指,是指当前的指示语与上文出现的词、短语或句子(句群)存在密切的语义关联性;共指则主要是指两个名词(包括代名词、名词短语)指向真实世界中的同一参照体。回指和共指的消解,所需的知识和消解步骤是基本一致的,但在处理上不完全相同:回指消解是要根据上下文判断指示语与先行语之间是否有关系,这种关系可以是上下位关系,部分整体关系和近义关系,当然,也包括等价关系。共指消解则主要考虑等价关系。
指代消解首先要构造先行语候选集,然后再从候选中作多选一选择。早期比较著名的方法有1997年的朴素Hobbs算法[35]和1983年前后提出的中心理论[36]。但是无论是朴素Hobbs算法,还是中心理论,主要都是作为理论模型提出的,在实际系统上很少直接使用。而现已实现的典型技术主要有基于句法的方法和基于语料库的方法。
基于句法的指代消解是较早采用的方法,这种方法试图充分利用句法层面的知识,并以启发式的方式运用到指代消解中[30,31,33,37-41]。比较典型的系统是1994年由Lappin&Leass提出的RAP算法,该算法用于识别第三人称代词和具有反身特征与互指特征的先行语,算法主要使用了句法知识[33]。它先通过槽文法分析,再通过句法知识消解指代。Lappin&Leass的算法,指代消解准确度达到了86%。但他们事先通过人工方式对句子作过简化处理,同时,也只考虑了第三人称形式。1998年Mitkov提出了一种“有限知识”的指代消解方法[39]。该方法只需要进行词性标注,再利用一些指示符计算先行语候选的突显性,再经过性、数的一致性检验后,选取较高值的先行语作为最后的先行语。测试结果表明,成功率为89.7%。
另一种指代消解的方法是基于语料库的方法。随着语料库语言学的发展。基于语料库的指代消解方法也相继出现[25-27,40-42],主要有统计方法,统计机器学习方法等。
Soon等[43]采用该统计框架,选用决策树算法进行共指消解,在MUC评测结果首次超过了基于知识工程的共指消解方法,随后许多研究者均以此为基础进行了多方面的研究。Vincent Ng等在这个框架下对训练实例抽取和链接算法进行了改进[44],Strube等[45]和Yang[46]等提出了不同的两个实体提及匹配特征的表示方法,Florian等选用了最大熵方法用于统计共指消解[47]。
汉语指代/共指消解研究起步较晚,研究主要集中在人称代词的消解,主流方法为基于句法语义结构分析的规则方法。王厚峰等利用句类基本知识根据人称代词及其先行语在语义块中可能的语义角色,并结合局部焦点法,给出了汉语人称代词消解的基本规则和优先性规则[48]。为了克服知识获取瓶颈问题,他又提出了一种弱化语言知识的鲁棒性人称代词消解方法[49],仅仅用到了单复数特征、性别特征和语法角色特征,取得了满意效果。王晓斌提出了一种语篇表述理论为指导的汉语人称代词的指代消解方法[50],在语篇表述结构的构造过程中实现了人称代词消解。此外,曹军[51]、张威[52]分别对汉语零指代消解和元指代消解进行了研究。郎君尝试采用决策树算法用于汉语名词短语共指消解[53];孔祥勇采用了规则消解和统计因子消解相结合的策略,用于汉语共指消解[54];Zhou运用基于转换的自动学习方法,用于ACE中汉语实体提及之间的共指分析,取得了满意的效果[55]。
指代消解是一项重要的研究,同时也是一项非常困难的研究。到目前为止,还没有较好的全自动的指代消解技术和方法。而且目前指代消解研究主要依赖于基于句法语义结构分析的规则方法,不适合实现针对非受限大规模文本的信息抽取任务。因此,基于统计学习的实体指代消解方法有待深入研究。
(2)零指代消解。
1)零指代的定义:话语中提及了某个事物后,当再次论及这个事物的时候会采用各种方式来进行上下文的照应,这就是回指(anaphor)。当回指在语流上没有任何的形式体现时,就是零指代(zero anaphor)。像一般的共指一样,零指代也可以分为两种,一种是先行语出现在零指代之前,称为回指(anaphoric),另一种是先行语出现在零指代之后,称为后指(cataphoric)。
下面是零指代的几个例子。
①中国从前的监狱,墙上大抵画着一只虎头,所以叫做“虎头牢”,狱门就建筑在虎口里,这是说,□1一进去,□2是很难再出来的。《释放四题》
②(廖医生在我腿上敷了草药,拿纱布缠了。又拿出两副中药,对母亲说:“这种药,每天煎三次,两天后再来换药。”)母亲颤声问:“廖医生,□多少钱?”(《洁白的木槿花》)
③母亲高兴地答应了,□1拿了篮子,□2把木槿花全摘下来了。廖大夫拿秤一称□3,□4竟有一斤。《洁白的木槿花》
其中带□的地方都是空形式,但却有语义内容。以汉语为母语的人能够很容易地确定:①中□1、□2指称的是“犯人”,②中□指的是“诊治和拿药的费用”,③中□1、□2指的是“母亲”,□3、□4指的是“木槿花”。
说到零指代,人们往往会想到一连串相似的概念:省略、隐含、空语类,因为它们有共同的特点,在句子的表层结构中没有语音形式而有语义内容,但它们的所指各有不同。按沈阳[3]的解释,空语类包括三种类型:移位型、隐含型和省略型。所以它的外延最宽,涵盖了省略和隐含。隐含指的是句子中由于句法作用而出现的“空”形式,人们可以根据语言知识理解它的语义内容,但决不能在句子的表层形式中补出它,它是“真空”,因此,隐含是语言系统中的问题;省略与它不同,它是话语中由于语境作用而出现的“空”形式,人们往往要依赖句子以外的因素(语篇、情景等)才能将该空形式的语义内容找回,需要的话,它可以在句子的表层结构中补出来,它是“伪空”。省略离不开语境,因此它是言语中的问题。和零指代直接相关的是省略。
2)零指代的类型。
①就零指代本身在句中的位置及职能可以分为两类:作主语的,作宾语的。其中主语占多数。零指代作主语的大约占93.4%,而作宾语仅占6.6%。
②就零指代本身的属性可以分为两类:有生命的(即表人或动物的),无生命的。其中有生命的零指代占多数。据统计,有生命的零形代词大约占88.3%。无生命的零指代则占11.7%。
③就零指代的先行词的位置可以分为三类:先行词作主语的,作宾语的,做其他成分的。其中也是先行词作主语的占多数,大约占91.4%,先行词为宾语的次之,占5.3%,先行词为其他成分(如定语或状语的一部分等等)的最少,仅占3.2%。
④就零指代与先行词的距离可以分为三类:相邻的,隔句的,远距离的。其中相邻的包括一个先行词带有多个同指的零指代,但相应位置中间不被别的指称成分隔开的情况。如:
有一次父亲停下来,□1转到我面前,□2作出抱我的姿势,□3又做个抛的动作,然后□4捻手指表示在点钱,原来他要把我当豆腐卖喽!(《我和我的哑巴父亲》)
□1、□2、□3、□4是处于主语位置的零指代,它们的先行词都是“父亲”,因为中间没有出现别的主语,所以都算是相邻的。远距离的是指零指代和先行词相隔两句或两句以上的。在这三种类型中,相邻的零指代占绝大多数,约占95%,隔句的和远距离的都不多,两者合起来才占5%。所以我们选取6个小句(当前句及其前三个小句、后两个小句,见侯敏等[56])作为信息处理的句组长度。
3)零指代消解的相关工作。零指代的频繁使用,给汉语共指消解提出了一个挑战。虽然性、数等属性可以为普通的指代消解提供思路,但是由于零指代没有提供相关这些信息,同时识别零指代也是一个相当困难的工作。另外,即使识别出来零指代,但它有可能不是共指。所有这些使得汉语零指代消解极其困难。
零指代在语言学中曾经研究过[57],但是计算语言学中只有一小部分工作涉及零指代的识别和消解[58-60]。Yeh and Chen提出了一种基于中心理论的零指代消解方法[58,61]。这种方法是使用一系列的手工编写的规则来实现零指代的识别,同样在消解时,也是使用人工编写规则。Converse[59,61]假设零指代和标准的解析树给定情况下,使用Hobbs算法进行零指代消解。此系统不能自动识别零指代。作为指代消解的一个主要问题,对汉语零指代消解的研究并不是太多。而且以前大部分汉语零指代消解方法,在识别和消解过程中大多使用规则和启发式。文章[63]针对汉语零指代的特点,分析了零指代在语义结构中与其他语言成分的相互关系;并提出在这种关系的宏观控制下,利用谓词语义进行零指代消解的策略。Shanheng Zhao and Hwee Tou提出了一种基于机器学习的识别和消解汉语零指代的方法[60]。他们自称,通过两组可计算的特征识别和消解过程都能自动进行,是至今为止完全使用机器学习的方法实现零指代消解的方法。
4)基于浅层分析与机器学习的汉语零指代消解。下面着重介绍本章使用的零指代消解方法。为了解释本文方法,先对文中使用的几个定义做一下解释。
话语片段(discourse segment):根据零形代词所在句与先行词所在句之间的间隔不能太远,选取6个小句(当前句及其前三个小句、后两个小句,见参考文献[5])作为信息处理的句组长度,这样的一个句组称之为一个话语片段(discourse segment)。
主动词:是指句子的核心动词。
逻辑论元:逻辑论元是指动词的逻辑配价中的配价成分,它相当于谓词逻辑中的论元(argument)。即动词动作所涉及的客体。比如看到一个动词“吃”,必然要问“吃”的主体是谁,“吃”的客体又是什么,此时“吃”的主体就称为施事论元,而“吃”的客体则为受事论元。
逻辑配价:所谓逻辑配价是指从逻辑语义的角度来考察动词的配价问题,也就是指动词的逻辑语义配价。它研究动词在逻辑语义层面所必须联系的语义论元,换句话说就是我们在理解一个句子的语义时必不可少的成分。在逻辑配价中不存在所谓的三价四价甚至六价七价动词,动词应该最多只能是二价,即自动词动作不涉及客体是一价,只有施事论元。其他动词动作涉及客体是二价,除了施事论元还有受事论元。这样处理会有以下四个方面的好处:首先突出了施事和受事的特殊地位。可以这么说典型的动作动词带典型原型的施事和受事;施事和受事的典型程度与动词的典型程度正相关。也正是从这个角度看,与其把论元划分得很细,不如根据动词动作性来划分动词,这样动词的类也就是论元(施事和受事)的类。其次,把动词的逻辑论元限制在施事和受事,便于确定动词的逻辑配价成分。我们只需考虑最简单的情况,即如果一个动词只带了一个论元,就表达了一个相对完整的命题,那么这个论元必定是施事。如果一个动词带了两个论元,才能表达一个相对完整的命题,那么这两个论元必定是施事和受事。再次,把动词的逻辑论元限制在施事和受事,可以简化动词逻辑配价的框架结构。便于操作,易于计算。最后,把动词的逻辑论元限制在施事和受事,既可以避免确定许多名词短语语义角色时的困难,又可以做到句法和语义的同构对应,使动词配价研究能够真正为自然语言理解服务。
下面来看基于浅层分析与机器学习的汉语零指代消解的具体步骤。
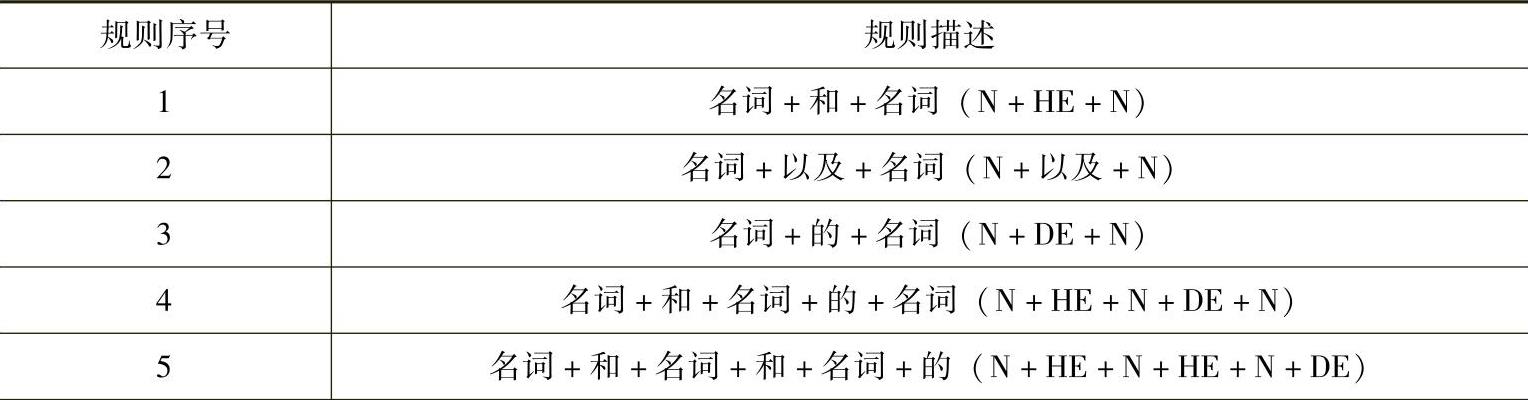
第一步,基于主动词识别,对话语片段进行层次分析。主动词是句子的核心,如何判断句子的核心动词,是正确分析句子结构和层次的重要步骤。但是,在汉语文本中,一个句子中有一个以上的动词很普通,而且汉语动词没有数、性、格和时态的变化,用语法来确定哪个是主动词非常困难。因此,本文采用基于动宾语义搭配的方法进行汉语主动词识别[64]。该方法将句子中的动词按其分布情况分成了三类。第一类是在介词框架外的右邻不为“的”的动词(WD);第二类是在介词框架外的右邻为“的”的动词以及落选的左邻不为“的”的动词(W2);第三类是在介词框架内的动词(WJ)。只有右邻不为“的”的动词可以是候选主动词。所以确定主动词有两个步骤:首先是对动词进行分类,将情况简化,然后根据规则确定出主动词。在进行动词自动分类以前,首先要将词(主要是名词)进行合并,达到同一语法块中相邻词的词性是互异的。两个名词是否能合并主要由结合关系语义场决定。在名词合并方面,主要考虑了以下几种常见语法形式的分析规则,见表5-1。
表5-1 名词合并规则
(续)
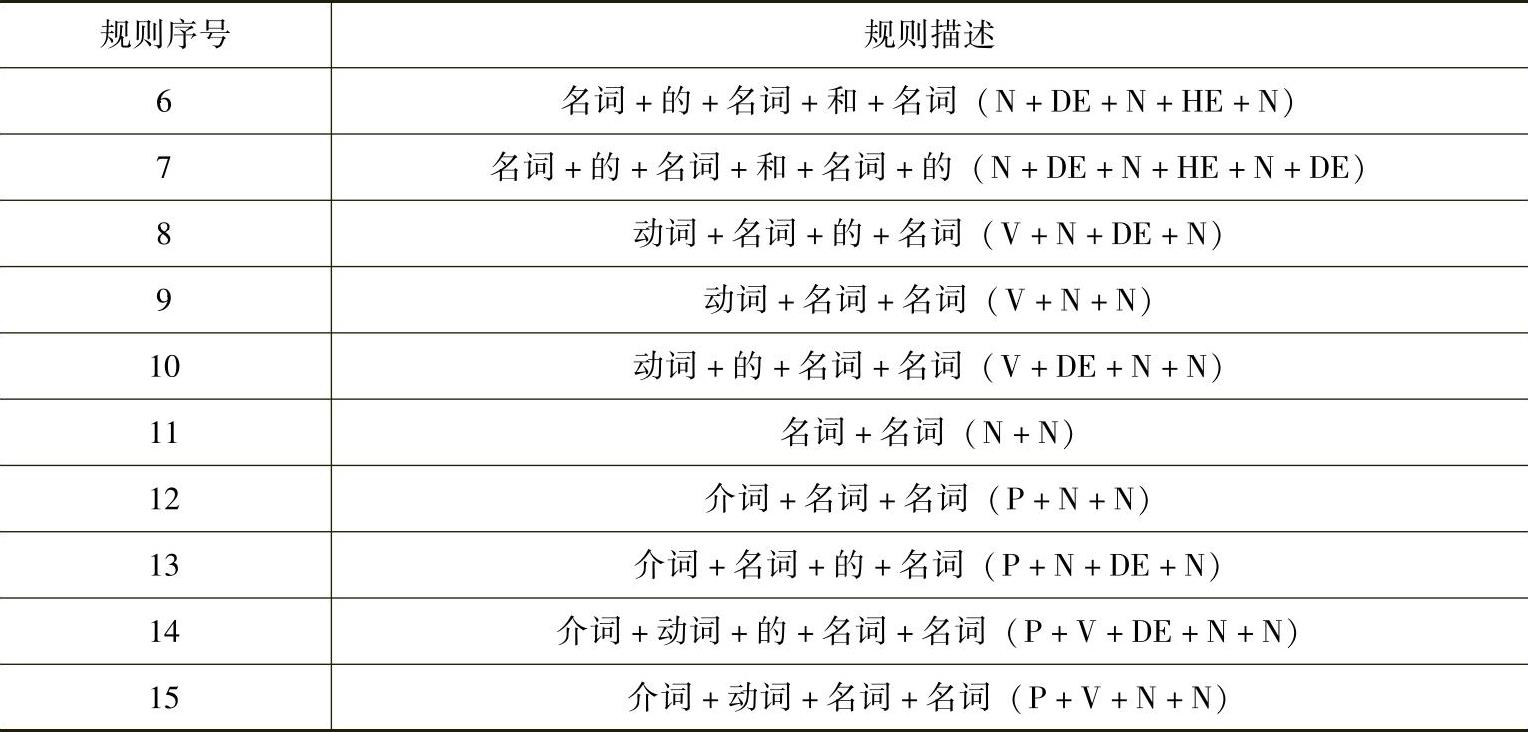
名词合并完成之后,进行基于规则的动词自动分类,实现流程如下(自左向右扫描I→待定动词指针K=I):


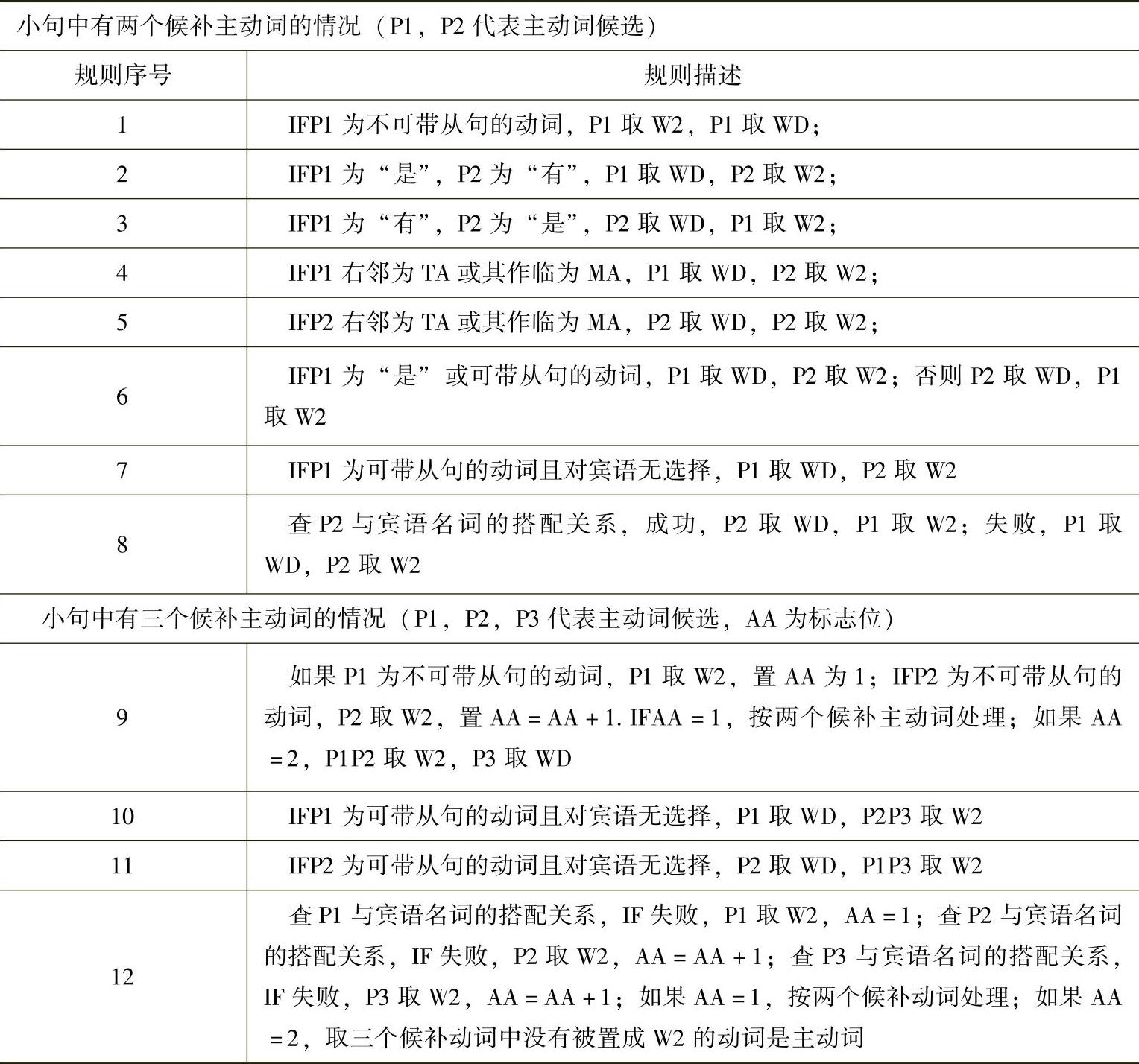
在名词分类之后,对每个话语片断进行主动词的识别。首先,按照动词分类的规则进行主动词候选过滤,过滤得到的动词集合作为主动词候选集合。然后根据主动词识别规则进行识别。主动词识别规则见表5-2:
在得到主动词之后,可以对每个华语片断进行层次分析。因为一个片断一般是由一系列小句组成,小句和小句之间一般为承接或者并列关系,一般不共享主动词,所以,主动词识别主要针对小句进行,然后再通过小句之间关系,得到长句的主动词及层次结构。当然也存在特殊情况。
表5-2 主动词识别规则
 (https://www.xing528.com)
(https://www.xing528.com)
例如:“老妇人见[阿弟瞪着细眼凝想,同时搔着头皮],知道有下文……”
一般情况下表示动作+感知的动词(如看见、发现、听见等)的管辖区域可以是跨小句的,分析层次时应该单独处理。从动词与后续小句的语义关联可以确定它们的层次关系,比如当动词是表示动作+感知的动词,如果后续小句描写心理动作或有“于是”、“不禁”、“忍不住”等词承接上句,则很可能是感知动作主体作出的反应,因此该小句不属于前句动词的管辖,而是与其层次相同;当后续小句的动词也是表示动作+感知的动词,则该小句也不属于前面动词的管辖,而是与其所在的句子并列;其他情况,尤其是描写事物性状的小句,属于前面动词的管辖的倾向性很大。本文中对这种情况下通过考察动词的辖区内的小句的结构是否一致,作为判断主动词的一个依据。
因为一个片断一般是由一系列小句组成,小句和小句之间一般为承接或者并列关系,一般不共享主动词,所以,主动词识别主要针对小句进行,然后再通过小句之间关系,得到长句的主动词及层次结构。
例如:“老妇人见阿弟瞪着细眼凝想,同时搔着头皮,知道有下文……”
分析第一个小句,有三个候选主动词“见”“瞪着”“凝想”,根据主动词识别规则,“见”可以带从句,而瞪着和凝想都不可以,我们取“见”为主动词,且“见”后面组成主谓结构,为其从句,从层次关系上从句属于“见”的子层。主句的结构可以表示为N+WD+OP(OP代表宾语部分)。分析完主句之后分析从句的结构,阿弟瞪着细眼凝想,“瞪着细眼”合并之后作为状语成分,从句表示为N+AC+WD(AC代表状语部分)。
分析第二个小句,只有一个候选词“搔”,取作主动词,但是,此句的结构不同于前句的主句,但与子句相似,所以与子句处于同一层次,属于“见”的宾语部分。结构分析为PT+V+N(PT为时助词)。
分析第三个小句,有两个候选主动词“知道”和“有”,根据主动词识别规则,“知道”可以带从句,而“有”不可以,我们取“知道”为主动词,且“知道”后面为谓宾结构,可以看作为它从句,从层次关系上从句属于“知道”的子层。主句结构为(V+OP),从句结构为(V+N)。
根据上面的分析我们得到整个句子的层次结构如下(见图5-4):
[老妇人见]1[阿弟瞪着细眼凝想,同时搔着头皮,]2[知道]1[有下文……]2
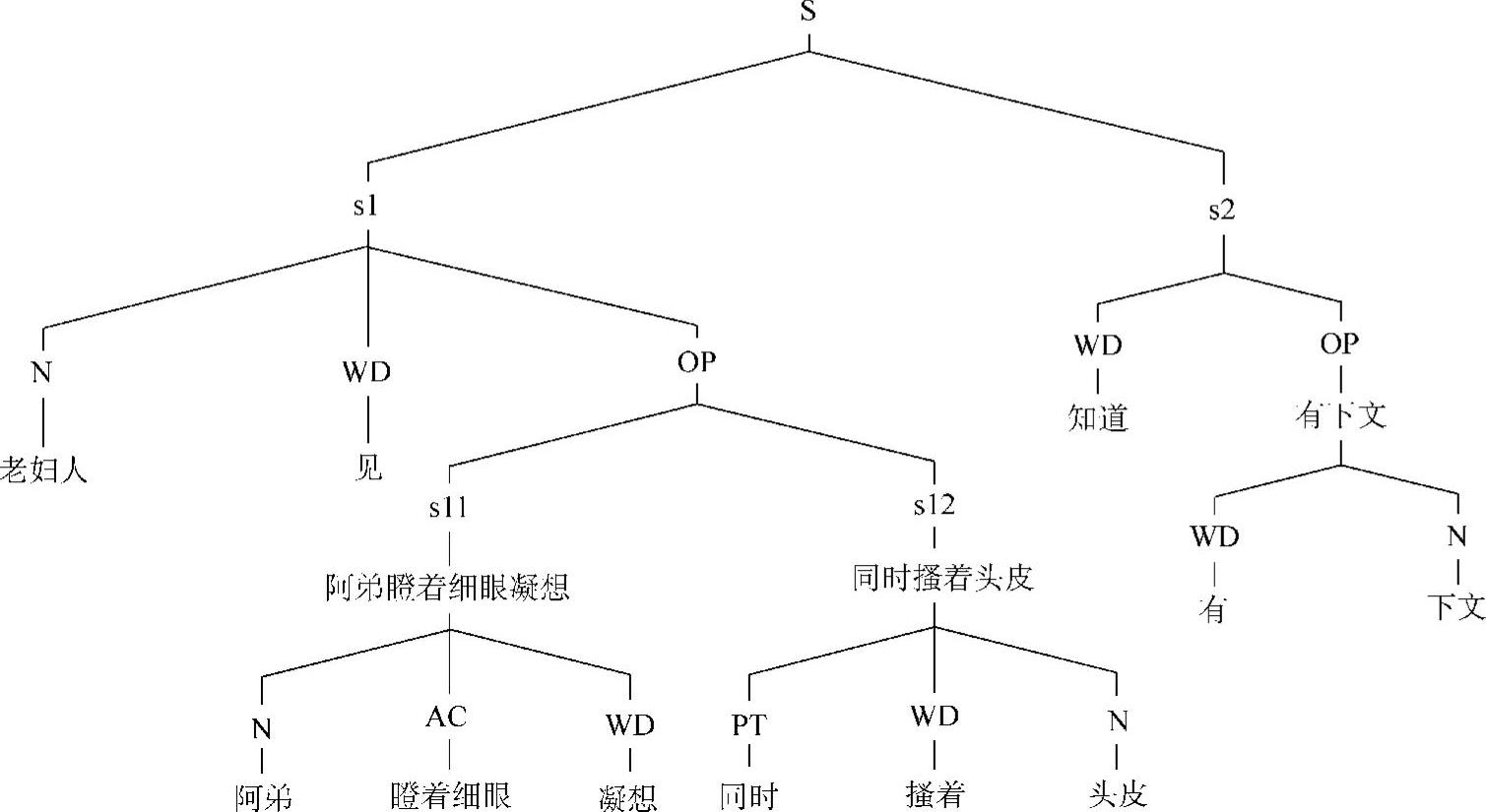
图5-4 话语片段层次分析结果示例
第二步,基于动词逻辑配价及逻辑论元识别的零指代识别。这里所谓提取逻辑论元指的是两个方面,一方面是该动词能否带受事论元,另一方面是该动词能带什么样的受事论元和施事论元。
首先判断动词的逻辑配价。现在研究动词配价的机构很多,例如北大的基于配价的汉语语义词典。但是现在还没有公开发表的配价词典。所以此处我们配价是通过《现代汉语词典》中对动词释义和应用举例来判断动词的价。同时,我们认为存在受事论元的动词一般是有实事论元的,所以只考虑动词是否能带受事论元,如果可以那么我们就把动词定义为二价动词。
比如,安排—有条理、分先后地处理(事物)、安置(人员)~工作、~生活、~他当统计员。
安排这个词可以带有受事论元,定义其价为2。
论元识别:经过前面提到的名次合并,基本上所有的小句都成为一个简单句,使得论元的识别变得非常容易。
规则1:如果动词前为名词(包括合并后的名词短语)或者代词,则把此词作为动词的施事论元;
规则2:如果动词后为名词(包括合并后的名词短语)或者代词,则把此词作为动词的受事论元;
根据上面的分析,零指代识别可以看作是动词的逻辑论元识别。给每个必须带论元的动词找到相应的实事和受事论元,如果默认,则认为此处为零指代。
仍以上例中句子为例,分析过程如下:
第一小句中,“见”为二价动词,在此片断中,存在主语“老妇人”,并且有宾语从句“阿弟瞪着细眼凝想,同时搔着头皮”作为其受事论元,所以不缺少论元,从句中“凝想”为一价动词,存在主语“阿弟”,所以不缺少论元。第二小句中,“搔”为二价动词,存在受事论元“头皮”,缺少施事论元。第三小句中,“知道”为二价动词,存在受事论元“有下文”,缺少施事论元。从句中“有”为二价,存在受事论元“下文”,缺少施事论元。所以得到所有的缺少论元。我们也得到了句子中的零形代词如下:老妇人见阿弟瞪着细眼凝想,同时ϕ1搔着头皮,ϕ2知道ϕ3有下文……其中ϕ1,ϕ2,ϕ3即表示零形代词。
第三步,用机器学习的方法进行零指代的消解。
在零指代消解方面,采用决策树(C4.5)的方法训练分类器进行零形代词消解。所使用的特征见表5-3所示。在表5-3的特征描述中,ZP代表零形代词,NP代表候选先行代词。在进行零指代消解之前,我们从话语片断中获得所有的候选先行词,通过过滤规则进行初步过滤,去除不可能的候选先行词。候选先行词的过滤规则如下:
①ZP和NP在句子中处于并列的位置,它们之间不存在共指关系。
例如:[公司]1决定ϕ1和[清华大学]2一起在多媒体应用技术领域ϕ2展开多方面合作。
在这个句子中,短语2和ZPϕ1处于并列的位置,因而它们之间不存在共指关系。
②P的出现位置在N首次出现的位置之前。
公司开会决定将50%的股份转让给ST中川。
[公司]1开会决定ϕ1将50%的股份转让给[ST中川]2。
在这个句子中,ZPϕ1的出现位置在NP2首次出现位置之前,因而它们之间不存在共指关系。
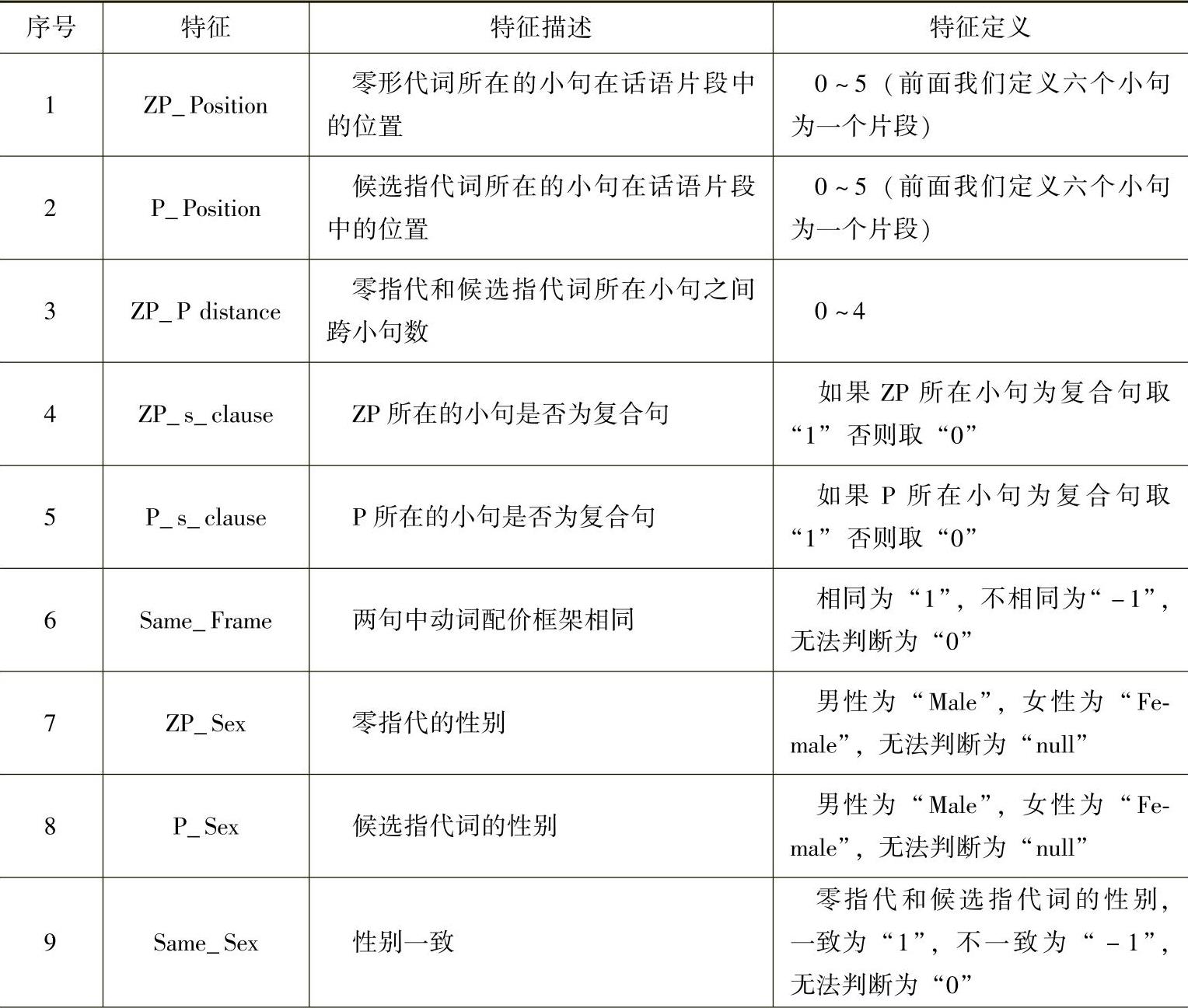
经过简单的先行词过滤之后,我们得到了每个零形代词的比较合理的候选代词集合。我们用机器学习的方法判断每个候选先行词与零形代词之间的关系,把每个NP候选和ZP看作一个候选对,通过分类器,判断他们之间存在共指关系,如果存在则把NP看作ZP的先行词,如果不存在,则把后面的NP与ZP看作候选对,直至找到一个ZP的先行词,或者没有NP候选存在时停止。零指代消解系统具体特征定义见表5-3:
表5-3 汉语零指代消解特征定义
(续)
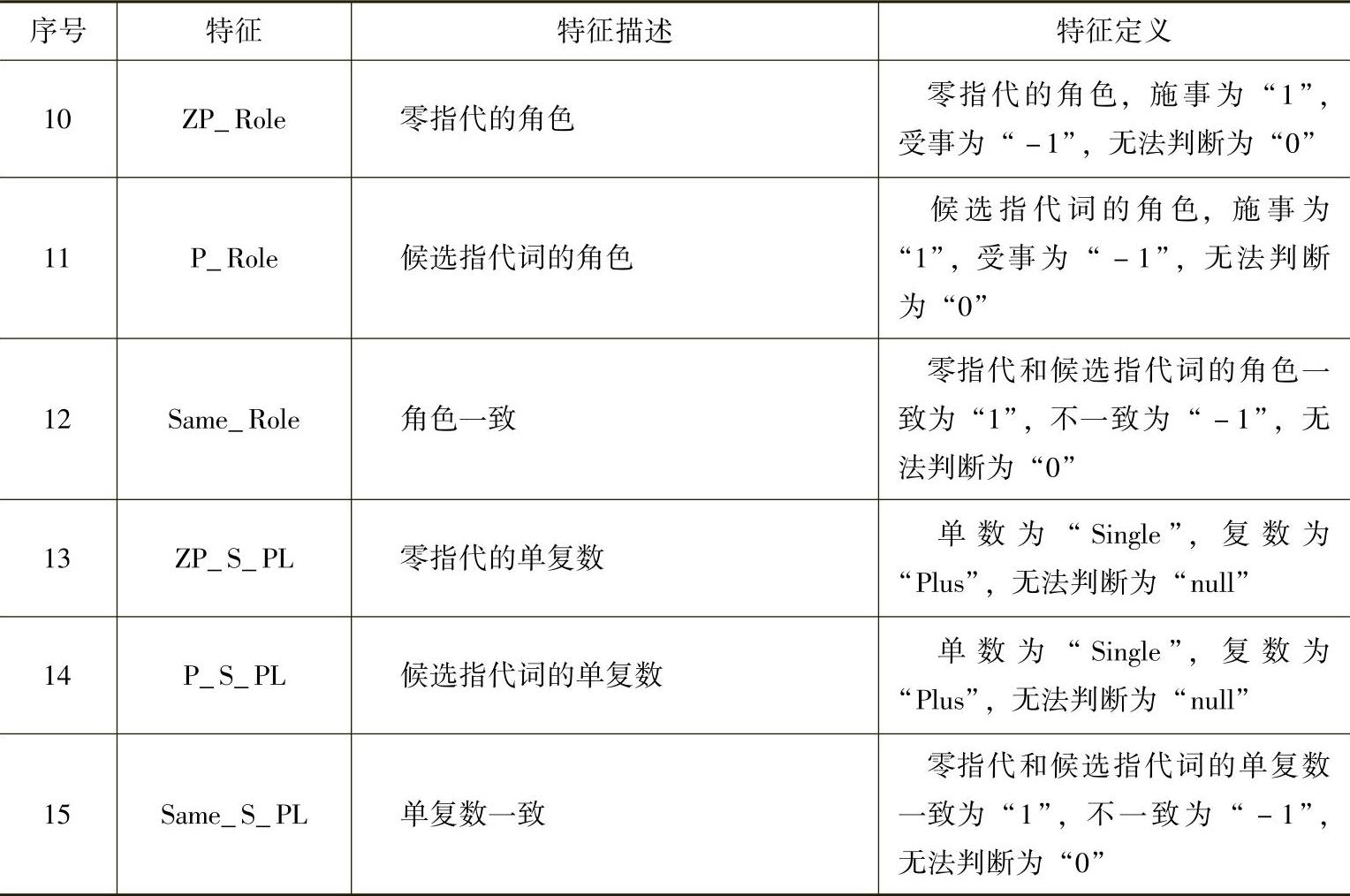
(3)其他指代消解。对于其他类型的指代词,利用一种简单的基于规则的方法进行了指代消解[65]。其使用的规则主要包括过滤集合和优选集合两个部分。前者将不存在共指关系的指代词P和指代实体N组成的“P-N”对过滤掉,后者对可能存在共指关系的“P-N”对进行打分。具体规则见表5-4。
表5-4 指代消解规则
利用上述规则进行过滤打分之后,使用一个消解度公式计算每个P-N对的消解度,
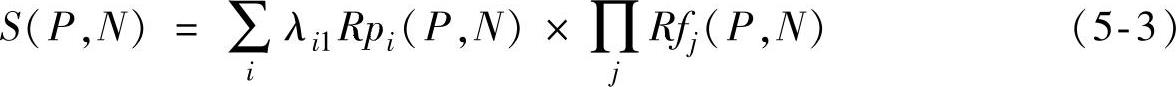
在式(5-3)中,P代表代词;N代表实体(先行词);Rf表示过滤规则;Rp表示优选规则;λ表示第i条优选规则的权值;S表示该P-N对的消解度。Rf值为0或1,即表示该共指关系是否应该被过滤掉。S值越大说明P-N对越有可能存在共指关系。
(4)语篇划分。话语片断的划分,决定了文本自然语言处理过程的准确性。在划分之前,对话语片断都要给定一个合适的量,它既要保证语言分析需要的足够信息,又要适合计算机的操作及存储空间的开销。通过分析,本文提出了基于语义完整性划分语篇的方法:因为一个语义完整的话语片断必然存在主动词及其必要论元,所以最初以每个小句为单位进行分析,如果小句中存在主动词和相应的论元,则把此小句作为一个单独的话语片断进行后续处理,如果此小句中缺少任何元素,那么考虑加入其后紧邻的小句,并进行同样的主动词及相应论元的分析,直到这个处理句组中存在主动词及必要论元为止,然后把这个句组当作一个话语片断进行后续处理。
(5)关系抽取。对于每个话语片断,进行主动词及其逻辑论元识别,方法与零指代消解中相同。在识别主动词及其论元之后,即完成了对这个话语片断中存在的关系的判断,接下来主要是看这些关系涉及的是否为命名实体,这主要是看主动词的论元是否都为命名实体或者都包含命名实体的成分,如果是,则在关系图中把二者进行有向连接,箭头由施事论元指向受事论元,同时把该主动词作为此关系的描述标注于连线的上方。整篇文档中所有的话语片断分析完成之后进行合并去重,即生成整篇文档中所有实体间的有向关系网络。下面举例说明:对于一篇新闻文档,新闻内容如下:
题目:穆巴拉克称允许加沙居民进入埃及购买必需品。
内容:2008年1月23日,上万巴勒斯坦民众通过被毁的边境墙涌入埃及境内。
*以色列称埃及应负责解决加沙地带边境民众骚乱
*巴勒斯坦民众涌入埃及抢购生活用品
*联合国安理会召开紧急会议讨论加沙局势
据法新社报道,埃及总统穆巴拉克今日称,他允许巴勒斯坦人离开加沙,前往埃及境内寻找生活必需品,前提是他们不得携带武器。
穆巴拉克对开罗媒体说:“我告诉安全部队对前往我国境内的加沙居民予以放行,并允许他们返回加沙,只要他们不携带武器或其他非法物品。”
我们进行社会网络分析得到的关系图如图5-5所示。
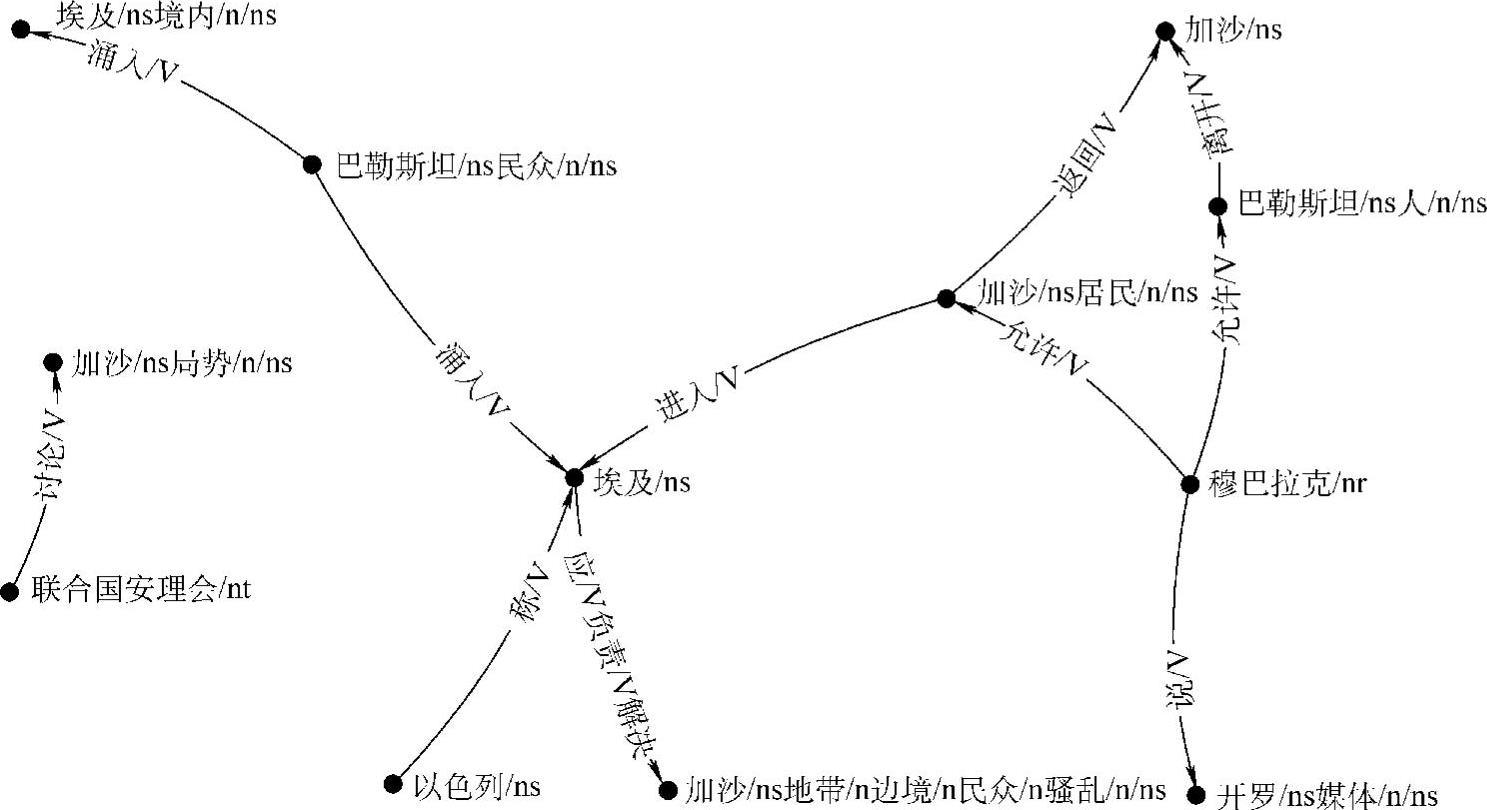
图5-5 对举例中新闻文档分析得到的社会网络关系图
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。