



4.4.1 Jena API
Jena来自于惠普实验室语义网研究项目的开放资源,它用于创建语义网应用系统的Java框架结构,为RDF,RDFS,OWL提供了一个程序开发环境,以及一个基于规则的推理引擎。语义网推荐规范中的本体描述语言的核心是RDF图(Graph),这是全球通用的数据结构。Jena将RDF图作为其核心的接口。Jena有以下几个主要功能:
(1)RDF API(主要是com.hp.hpl.jena.rdf.model包),可将RDF模型视为一组RDFStatements集合。
(2)RDQL查询语言(主要是com.hp.hpl.jena.rdql包),对RDF数据的查询语言,可以伴随关系数据库存储一起使用以实现查询优化。
(3)推理子系统(主要是com.hp.hpl.jena.reasoner包),包括基于RDFS,OWL等规则集的推理,也可自己建立规则。
(4)内存存储和永久性存储(主要是com.hp.hpl.jena.db包)。Jena提供了基于内存暂时存储的RDF模型方法,目前仅支持MySQL,Oracle和PostgreSQL的数据存储。
(5)本体子系统(主要是com.hp.hpl.jena.ontology包)。Jena对OWL,DAML+OIL和RDFS提供不同的接口支持。
(6)SPARQL查询语言(主要是com.hp.hpl.jena.query包)。可使用Jena创建和执行SPARQL查询。
Jena被设计成一个具有三层(Layer)架构和多种视图(View)的语义网开发框架(Framework)。它有很多应用程序开发接口提供给系统级和应用级的开发人员,因此它具有很高的灵活性。
Jena的系统架构分成三层:Graph层,EnhGraph层,Model(Ontology)层。图4-11是Jena的完整系统架构图。
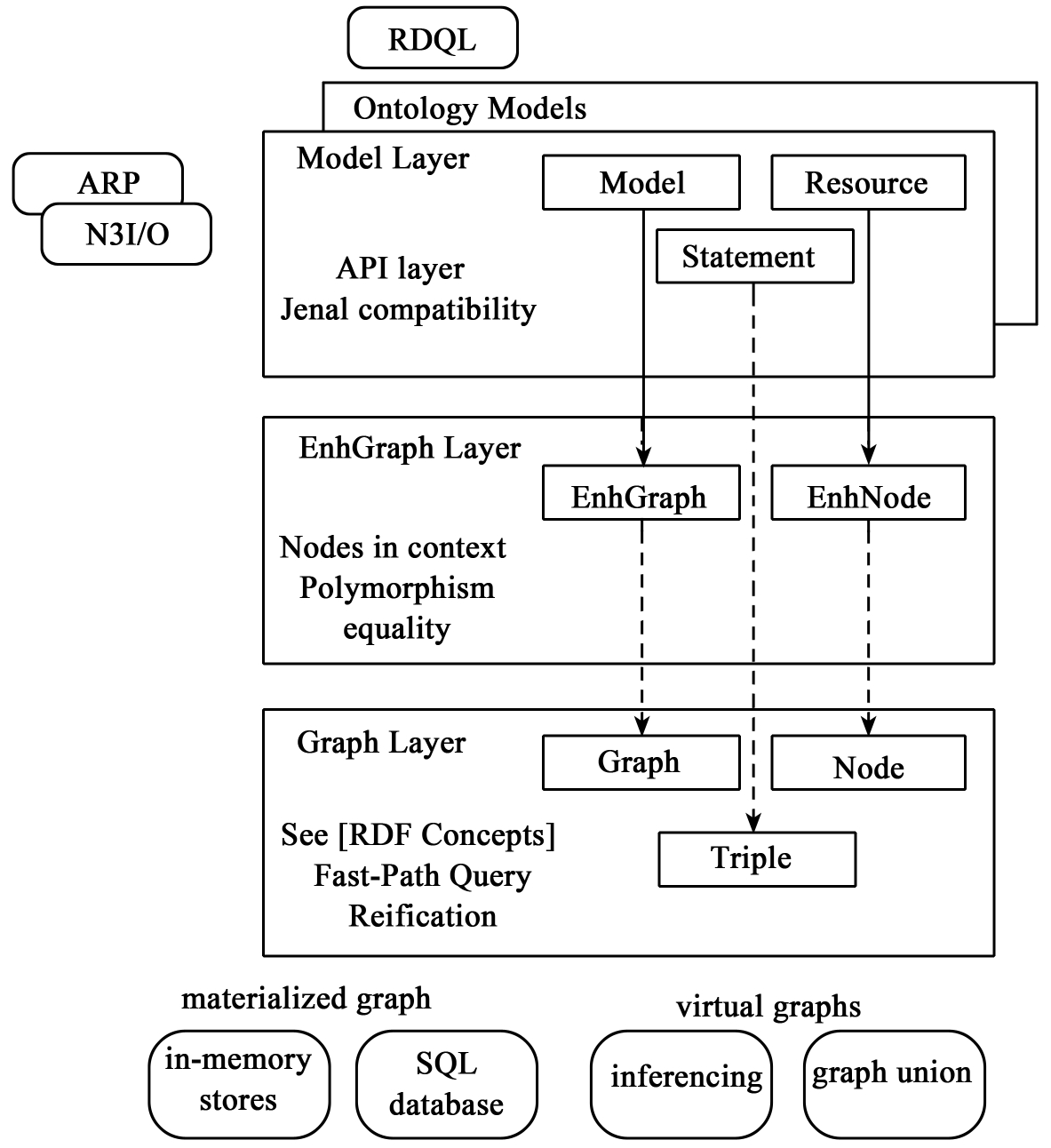
图4-11 Jena系统架构图
Jena系统架构的核心就是RDF图(由结点组成的三元组的集合)。这可以从Graph层中体现出来。这一层采用RDF的语法,并且采用最小限度的设计,仅实现最简单功能,而其他可能的功能就由其他层来实现。这样就允许对Graph层实现很多扩充的功能,比如在内存中或持久的实现三元组存储。
EnhGraph层是建立各种API的基石。在Jena中,这层所提供的功能可以用于实现Jena1中的Model API和Jena中新的Ontology API(用于支持OWL,RDFS和DAML)。
I/O操作是在Model层中实现的。Jena的系统架构支持使用RDQL从该层上对底层的SQL数据库实现查询,而且允许用户查询时采用SQL查询优化。
下面我们对三层进行详细说明:
(1)Graph层:用三元组作为全局数据结构
Graph层是采用RDF标准的。该层仅仅面向以下的功能来实现:
●三元组存储,包括内存和持久性存储方式。
●可以将非三元组的数据当作只读的三元组来处理,比如从一个网页中抽取,或者是从一个文件系统获取的数据。
●虚拟的三元组数据。例如推理过程中产生的三元组的结果集。
Jena中Graph层的实现提供了多种持久性存储三元组的方式,并且内置了基于RDFS和OWL-Lite的推理。
(2)Model层:为应用程序员提供的视图
Jena中的Model API是程序开发人员获取RDF图数据的主要方式。这一层提供了大量的方法来操作图(通过Model接口)和图中的结点(通过Resource接口及其子类)。图可以理解成模型(Model)本身,而结点可以理解成模型中的资源(Resource)。此外,DAML API也得到了进一步的加强。Jena中扩充了的Ontology API不仅支持了DAML,而且支持OWL。
(3)EnhGraph层:多种同步的视图
Model层和Ontology层和Graph层之间有一个中间层:EnhGraph层。该层必须能支持上面的Model层和Ontology层的多种表现视图。这一层的作用是使得表现层不固定,可以根据需要而改变。但是所有的表现层都是基于图的。EnhGraph层被设计成能同步提供多种图或结点视图方式。Java的单继承机制避免了在这层出现多个不同状态的对象,但又能将一个对象以多种视图方式表现出来。
RDF API主要用来创建,解析,处理和查询RDF模型。Jena定义了很多的接口来访问和处理RDF数据,如图4-12所示。
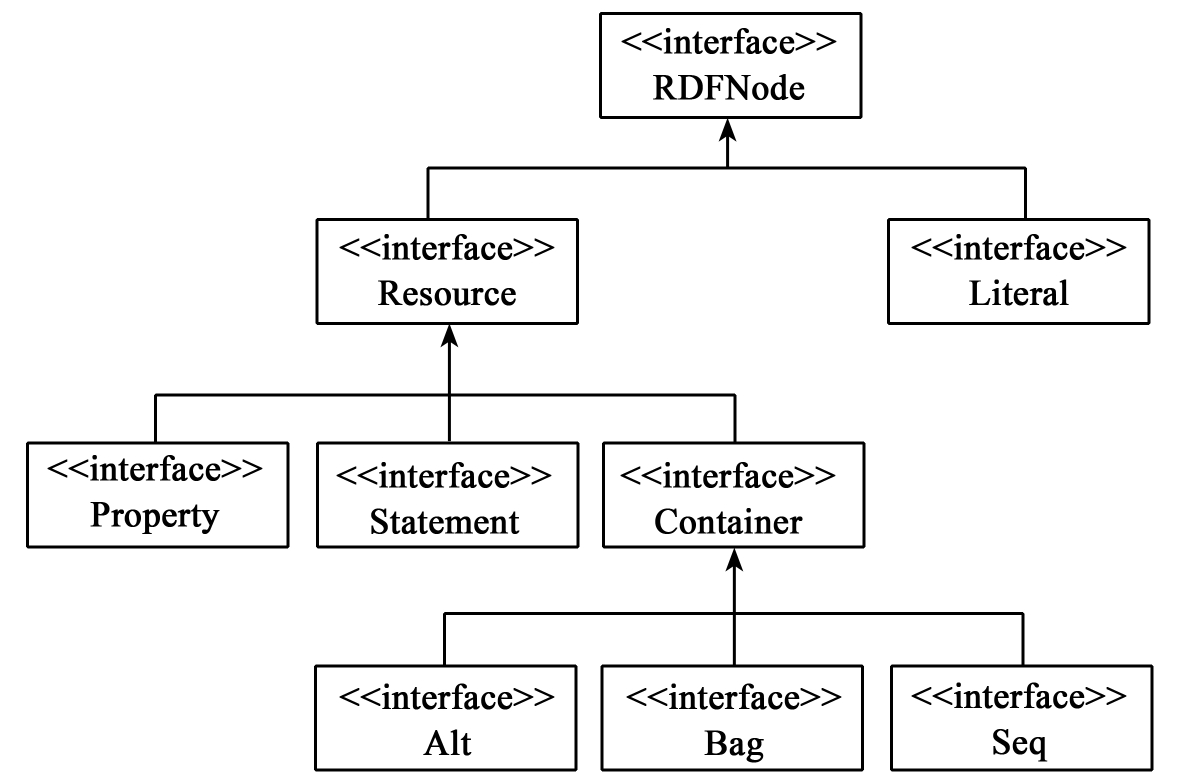
图4-12 RDF API的主要接口图
(1)创建和读、写RDF模型:Jena具有一系列的方法创建一个RDF模型,并将其内容写入到RDF文件中,也可以把RDF文件中的信息读取到模型中,如代码4-1所示,当然相关的RDF文件都要遵循XML语法和格式规则。
代码4-1 创建和读、写RDF模型
//创建一个空的RDF模型
Modelmodelname=ModelFactory.createDefaultModel()
//将模型中的信息写入到RDF文件
modelname.write(system.out)
//将RDF文件中的信息读取到模型中
modelname.read(new InputStreamReader(inputstreamname),″″)
(2)操纵和检索RDF模型:Jena提供一系列的方法用于对RDF模型中的数据进行操纵和检索。在操纵RDF模型时,首先可以根据Resource的UR I(Universal Resource Identifier)地址从模型中提取一个Resource对象,然后可以利用Resource对象提供的接口来操纵其中的相关内容,例如检索符合一定条件的特定值;使用RDF API对RDF模型只能进行比较粗糙和简单的检索,更强大的检索功能要借助于RDQL查询语言,可以使用一定的Jena API方法在RDF模型中检索出符合条件的信息。如代码4-2所示。
代码4-2 在RDF模型中检索信息
//根据Resource的UR I返回Resource对象
Resource resourcename=model.getresource(URI)
//利用Resource对象的接口列出符合条件的信息(一个例子)
String stringname=resourcename.getProperty(propertyname).getString()
//使用一般的方法检索RDF模型
ResIterator iteratorname=model.listSubjectsWithProperty(propertyname)
//使用Selector对象以三元组匹配的形式检索RDF模型
Selector selectorname=new SimpleSelector(Subject,Predicate,Object)
//然后可以使用liststatement方法输出相关结果
StmtIterator interatorname=model.listStatements(selectorname)
前面已经讲解了怎样将RDF模型中的信息写入到文件中进行存储。Jena还提供一个持久化模型,该模型扩充了Model类,可以透明地使用基于数据库引擎的持久性存储。该模型可以支持三种常见的数据库:MySQL,Oracle,PostgreSQL,支持的平台有Linux和Windows。
有两种方式来创建持久性模型,一种是工厂方法,另一种是构造ModelRDB类。
(1)工厂方法
如代码4-3,用工厂方法创建或打开一个持久性数据库模型可以分成三步。第一步,加载JDBC驱动类,建立与数据库的连接。注意:Jena中数据库的类型需要在建立连接的时候特别指明。第二步,构造ModelMaker类。该类用来创建模型的持久性实例。第三步,调用ModelMaker类的方法创建新的模型或者打开已经存在的数据库持久性模型。
代码4-3 用工厂方法创建持久化模型
//加载数据库驱动程序
Class.forName(M_DBDRIVER_CLASS);
//创建数据库连接
IDBConnection conn=new DBConnection(M_DB_URL,M_DB_USER,M_ DB_PASSWD,M_DB);
//用所给的连接创建ModelMaker
ModelMaker maker=ModelFactory.createModelRDBMaker(conn);
//创建一个空模型
Model defModel=maker.createModel();
//创建一个有名字的模型
Model nmModel=maker.createModel(″MyNamedModel″);
//打开一个以前就存在的模型(https://www.xing528.com)
Model prvModel=maker.openModel(″AnExistingModel″);
(2)ModelRDB方法
基于数据库的RDF模型可以看作ModelRDB的一个实例。ModelRDB继承了Model接口的所有方法,而且提供了静态(static)方法来创建、扩充、打开数据库持久性模型。如代码4-4所示,创建或打开一个持久性数据库模型可以分成两步。第一步同工厂方法一样,加载JDBC驱动类,建立与数据库的连接。第二步,使用ModelRDB的静态方法创建ModelRDB的实例或者打开已存在的实例。
代码4-4 用ModelRDB方法创建持久化模型
//加载数据库驱动程序
Class.forName(M_DBDRIVER_CLASS);
//创建数据库连接
IDBConnection conn=new DBConnection(M_DB_URL,M_DB_USER,M_ DB_PASSWD,M_DB);
//用ModelRDB创建一个有名字的模型
ModelRDB nmModel=ModelRDB.createModel(conn,″MyModelName″);
Jena中允许每个数据库对应多个存储Model,每个模型都用不同的表来存储。代码4-5是一个来检查数据库中是否存在指定命名的Model的代码示例。这在需要创建新Model或者是打开已存在的Model的时候是必需的,否则可能会抛出异常。
代码4-5 检查数据库中是否存在制定命名的Model
//创建数据库连接
Class.forName(M_DBDRIVER_CLASS);
DBConnection dbcon=new DBConnection(M_DB_URL,M_DB_USER,M_ DB_PASSWD,M_DB);
ModelRDB model;
//检测是否已经存在指定命名的Model,若不存在则创建一个新的,若存在则使用已有的
if(!dbcon.containsModel(″myModelName″)
model=ModelRDB.createModel(dbcon,″myModelName″);
else
model=ModelRDB.open(dbcon,″myModelName″);
在了解如何使用Jena来构建和存储本体之后,还需要进一步使用已经构建好的本体为我们服务,其中最重要的一种利用方式就是进行基于本体的语义检索。语义检索是基于概念及其概念之间的关系进行的语义层面的检索,关键在于概念之间的推理。Jena提供基于规则的推理机(如RDFSReasoner、OWL Reasoner等),它包含了一般的推理功能,此外用户还可以根据需要自定义推理规则,也可以注册使用第三方推理引擎。如图4-13所示,推理机的工作原理是:推理机注册机制根据基本RDF三元组描述(信息资源)和Ontology(可选)创建出推理机,由此推理机可以生成包含推理机制的模型对象(Inference Graph,InfGraph),在Jena中,图(Graph)也被称为模型(Model),而表现形式为模型界面(ModelInterface),然后可以使用Model API和Ontology API对此模型进行操作和处理,从而实现语义层面的信息检索。
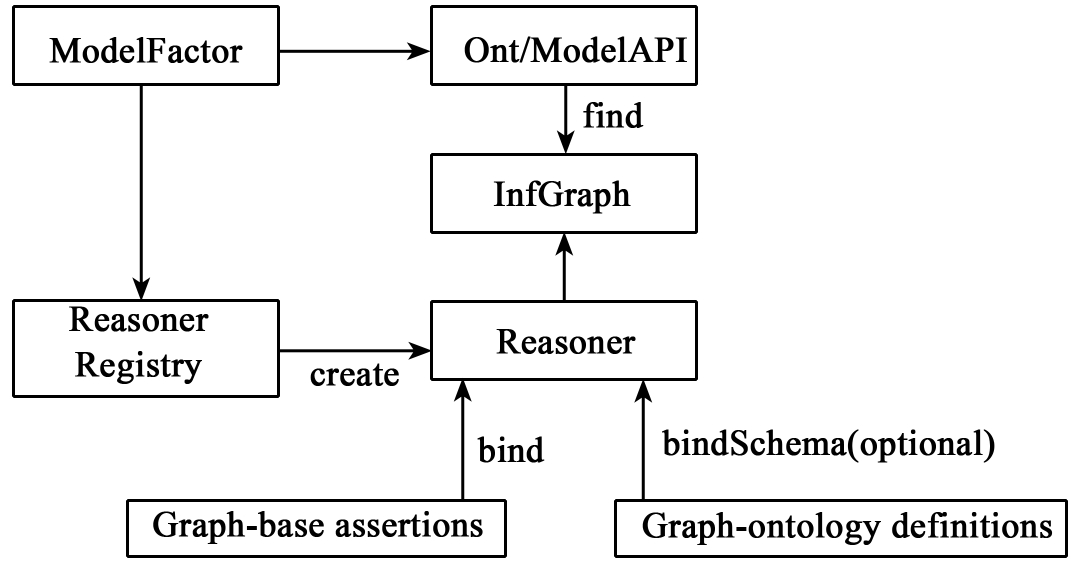
图4-13 Jena推理机的工作机制图
在应用程序中,通常使用ModelFactory类把推理机与数据模型关联起来,以达到推理的目的。在创建推理机时,主要有三种方式:
(1)借助于Jena自带的RDFReasoner和OWLReasoner,同时支持DAML。这些推理机中的推理规则都是基于一般用途的,以OWL Reasoner为例,具体的使用过程如代码4-6所示。
代码4-6 推理机的使用(以OWL Reasoner为例)
//获取Ontology数据
Model schema=ModelLoader.loadModel(SchemaFileURI)
//获取信息资源数据
Model data=ModelLoader.loadModel(DataFileURI)
//创建空的OWL注册机
Reasoner reasoner=ReasonerRegistry.getOWLReasoner()
//向注册机中绑定Ontology数据
reasoner=reasoner.bindSchema(schema)
//向注册机中绑定信息资源数据
InfModel infmodel=ModelFactory.createInfModel(reasoner,data)
(2)使用基于自定义规则的推理机。推理机的内部是根据一定的触发机制,通过对推理规则的解释,从而实现推理的效果。具体的触发机制包括向前链引擎、向后链引擎和混合式规则引擎,向前链引擎和向后链引擎可以彼此独立使用,或者向前链引擎可以初始化向后链引擎;对于推理规则,用户可以根据需要定制自己的规则,然后根据自定义的规则可以创建特定的推理机,实际上,Jena自带的推理规则可以在$\etc下的相关文件中找到。自定义推理规则的推理机的创建如代码4-7所示。
代码4-7 自定义规则推理机的创建和使用
//自定义推理规则
String rules=″[r1:(?c eg:concatFirst?p),(?c eg:concatSecond?q)->
″+″[r1b:(?x?c?y)<-(?x?p?z)(?z?q?y)]]″
//根据自定义推理规则创建对应的推理机
Reasoner reasoner=new GenericRuleReasoner(Rule.parseRules(rules))
//根据自定义的推理机创建包含推理关系的数据模型
InfModel inf=ModelFactory.createInfModel(reasoner,rawData)
(3)使用第三方推理机。除了Jena自带的推理机机制之外还有其他可以应用在语义网中的推理机(如Racer),这些推理机可以与Jena进行集成,所以对于Jena而言,称之为第三方推理机。
如果不能对构建好的本体库中的内容(包括推理出的新的内容)进行快捷且细致的查询,构建本体库和进行本体推理就显得毫无意义。Jena API对这两种查询语言都提供了良好的支持。
RDQL从RDFModel(包InfModel和OntModel等)中检索数据,检索的结果存储在一定的数据结构中可供调用,如代码4-8所示,将其与用户的检索界面实现联接和集成,则可解决语义检索应用系统与用户交互的问题。
代码4-8 用RDQL实现信息检索示例
//构建查询语句
String querystring=″Select??″
//创建查询对象
Query queryname=new Query(querystring)
//设定检索目标Model
Queryname.setSource(modelname)
//创建查询执行对象
QueryExecution qename=new QueryEngine(queryname)
//查询执行并存储结果
QueryResults resultsname=qename.exec()
SPARQL协议和RDF查询语言(SPARQL)是W3C规定的本体查询标准。SPARQL构建在以前的RDF查询语言(例如rdfDB、RDQL和SeRQL)之上,拥有一些有价值的新特性。在Jena中使用SPARQL,可以通过调用名为ARQ的模块得以实现。除了实现SPARQL之外,ARQ的查询引擎还可以解析使用RDQL或者它自己内部的查询语言表示的查询。ARQ的开发很活跃,但它还不是标准Jena发行版本中的一部分。但是,可以从Jena的CVS仓库或者自包含的下载文件中获得它。如代码4-9所示,可使用Jena来创建和执行SPARQL查询。
代码4-9 创建和执行SPARQL查询

JenaAPI不仅仅支持RDF格式的本体数据的开发,也支持基于RDF格式的其他本体数据的程序开发。比如像OWL,DAML+OIL和RDFS,它们都是基于RDF格式的本体语言。对于以上的三种语言的本体API都是从RDF API中继承实现的。通用的RDF模型允许获取RDF数据模型中的Statement,而本体模型OntModel扩展了这种方式,可以通过将通用模型中的Resource类对象对应成本体模型中的Class,Property和Individual类对象等,然后调用这些类的方法来获取数据。使用本体模型中最常用的类有OntModel,OntClass,OntResource,OntProperty,Individual。对应OntModel类继承了Model类,OntClass类则继承了Class类,OntResource类则继承了Resource类。本体中的类OntClass,属性OntProperty,还有实例Individual都可以看成是OntResource对象。还有OntProperty类继承了Property类。Individual类是指一个实例,相当于Java中一个类的对象。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。