



6.5.3 基于本体的数字图书馆检索模型——GGHZ—DL的设计与实现
我们所构建的“国共合作”历史领域本体,描述了从五四运动开始一直到连战访问大陆的这段历史时期涉及的概念、术语、关系、个体。其中包括以国共合作为轴线涉及的人物、组织、事件、资源等,以及政治、经济、文化教育、军事等多学科领域知识。领域本体的目标用户可以是普通用户、历史知识爱好者、近现代史研究专家以及党建党史专家。
此外,我们构建的历史领域本体与目前大部分集中在抽象概念层次关系描述和信息组织领域的本体不同,它不仅仅要实现信息的组织(概念分类),更重要的是尝试利用本体进行信息的描述(实例表现),即用本体的语义描述能力来展现历史学科领域错综复杂的人物、组织、事件等个体以及它们之间错综复杂的关系。针对历史领域本体库,我们提出了多种检索模型,从多个角度深层次地挖掘语义知识。
GGHZ—DL检索模型的用户界面如图6-18所示,主要包含三个部分:
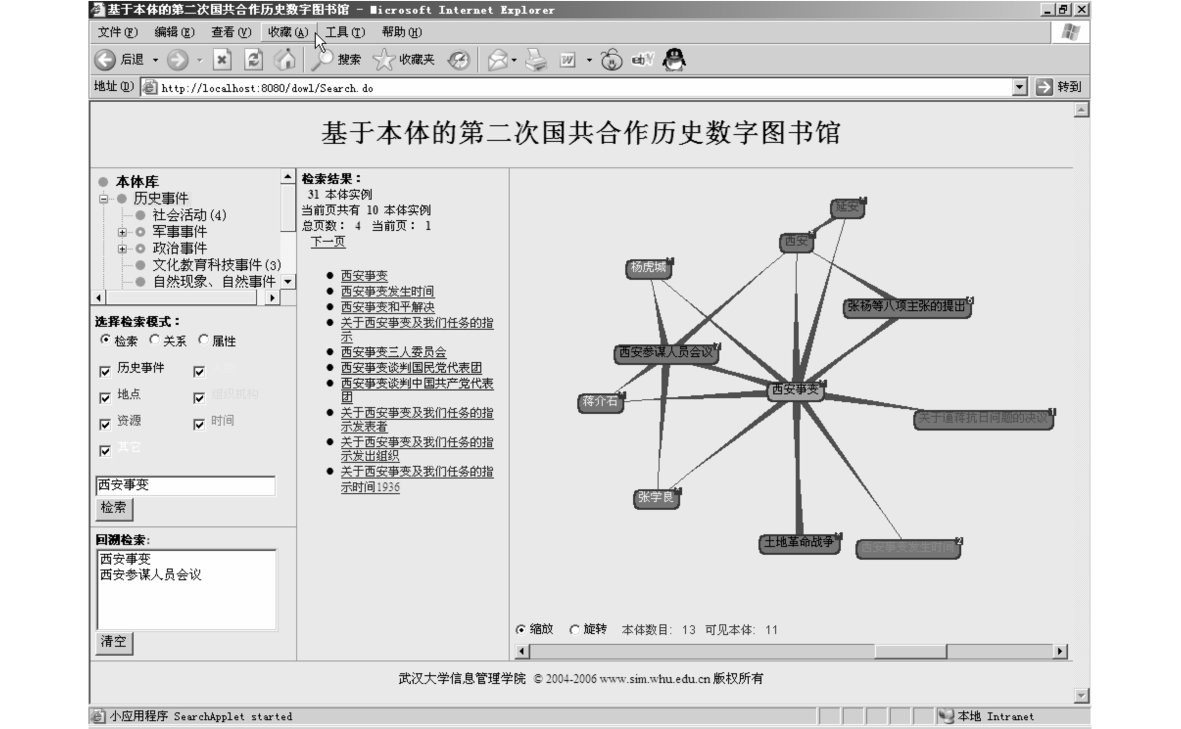
图6-18 基于本体的第二次国共合作历史数字图书馆用户界面图
●左部检索入口:列表检索、关系检索、属性检索和回溯检索等;
●中部本体文字检索结果;
●右部本体动态可视化检索结果。
1.本体实例与属性检索
(1)本体实例检索
本体库中最重要的资源就是本体实例,每一个本体实例表示这段历史领域中的某个语义概念,比如“西安事变”是一个历史事件本体实例,“周恩来”是一个人物本体实例。用户的大部分检索需求事实上就是针对这些本体实例。GGHZ—DL提供非常方便地检索UI接口:
首先在系统左边检索入口部分的“选择检索模式”中选择“检索”,然后在输入框内输入“致东北军将士书”,接着点击“检索”按钮。如图6-19所示,一共检索出4个本体,其中第一个就是“致东北军将士书”。
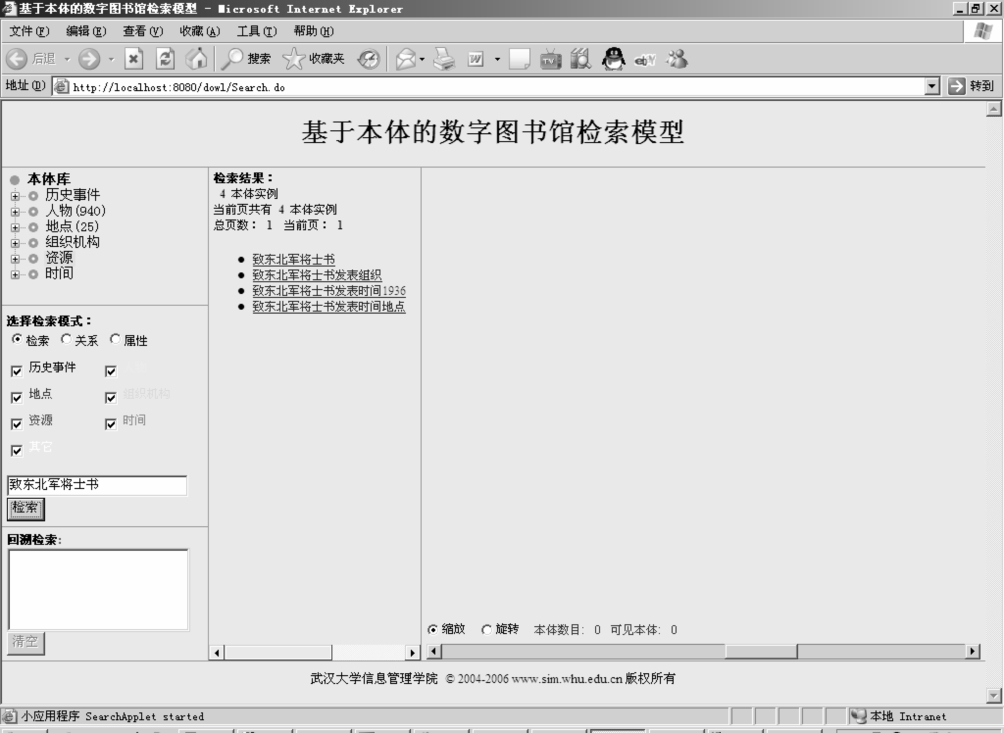
图6-19 通过输入方式的本体检索图
对于不熟悉此领域的用户,系统还提供了一种分类列表的方式进行检索。系统左上角是按照领域本体概念的层次关系组织而成的树形结构列表。每一种概念后面括号里面的数字表明它在本体库中的实例个数。通过这个列表,检索“资源”里面的“电报书信”,也可以找到“致东北军将士书”,如图6-20所示。
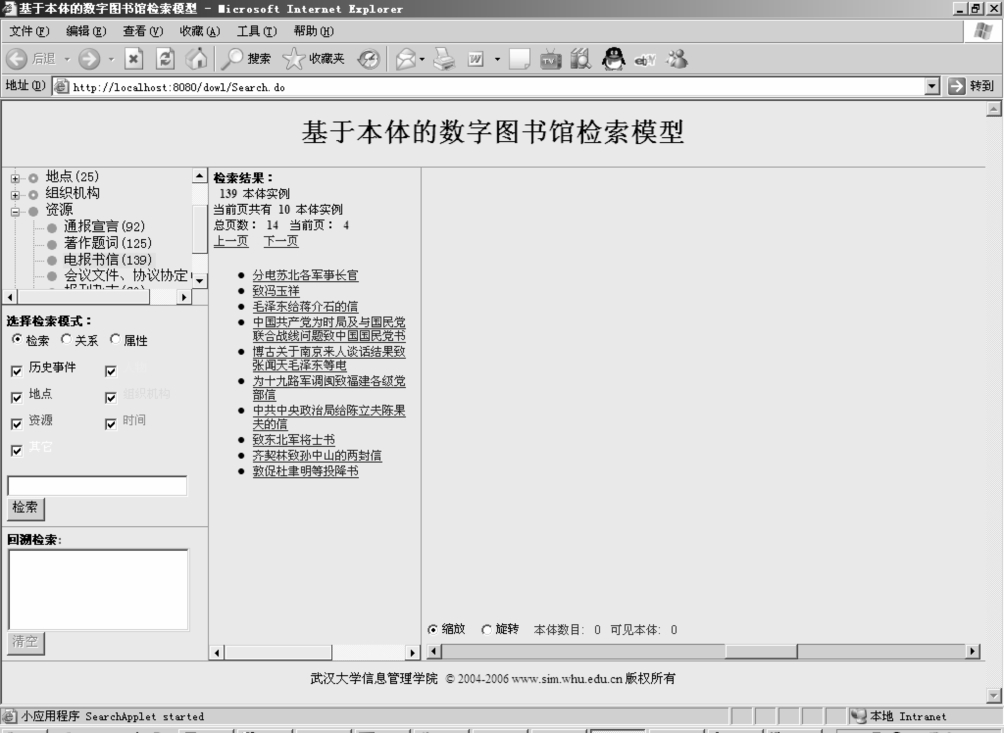
图6-20 通过列表方式的本体检索图
接下来点击“致东北军将士书”这个链接,可以检索与之相关的本体信息。这些本体信息主要包括两类:一类是“致东北军将士书”这个本体的详细信息,比如“资源名称”,“资源描述”;另一类是“致东北军将士书”与其他本体之间的关系。前者在系统的中间以文字列表的方式展现,而后者是在系统的右边以可视化的方式展现。如图6-21所示,本体以“结点”的方式显示(“结点”右上的数字表示与之相关的本体的总数),而本体与本体之间的关系以“边”的方式显示。边上的标签表明关系的类型,比如“致东北军将士书”和“西安事变”是“相关资源”的关系。
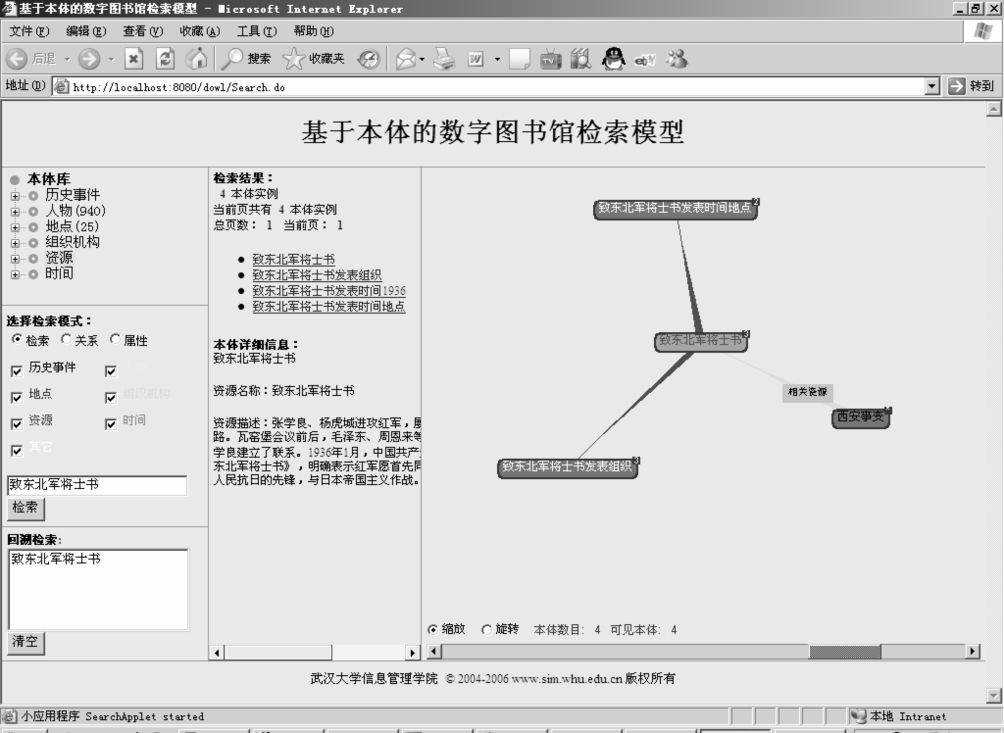
图6-21 本体详细信息图
另外,系统还提供了一种深层次检索的途径。如图6-22所示,

图6-22 展开本体图
对图中的“致东北军将士书发表组织”这个本体点击右键,弹出一个操作菜单。利用这个菜单,可以完成“展开本体”,“收缩本体”,“隐藏本体”,“本体居中”等操作。其中“展开本体”的“单类”菜单中还显示了与“致东北军将士书发表组织”这个本体相关的本体情况。每一类本体名称后面的括号里面的数字表明与之相关的该类本体的剩余数目。所谓剩余数目就是与之相关但是没有显示出来的数目。
点击“组织机构(2)”的结果如图6-23所示。“致东北军将士书发表组织”展开后得“中国共产党”和“红军”这两个类型为“组织机构的结点”。事实上,图6-23还展开了“致东北军将士书发表时间地点”这个本体。
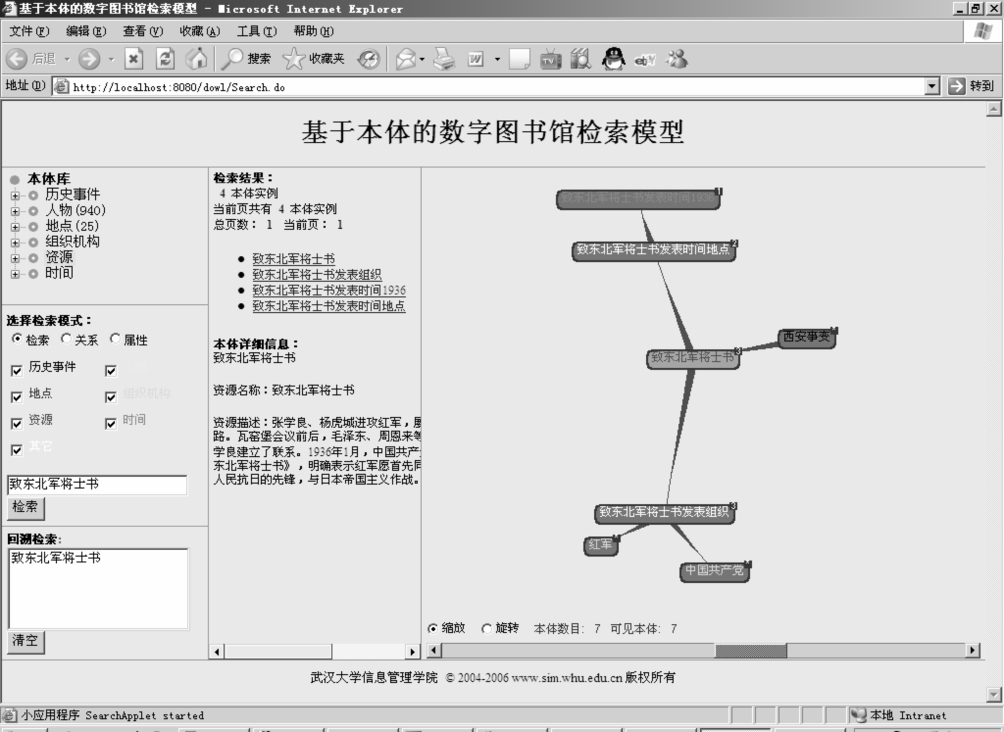
图6-23 展开本体的结果图
系统右边可视化区域并不是静态的。用户可以根据需要对视图进行“旋转”和“缩放”以达到最佳的可视化效果,这对于本体数目多而且本体关系复杂的情况非常有用。
另外,用户对视图中的任何一个本体都可以进行点击,这种点击事实上是进行了一次新的检索。比如用户点击图6-23中的“西安事变”结点,视图动态变换成以“西安事变”为中心的相关本体信息,而中间的本体详细信息列表也变成了“西安事变”的信息,如图6-24所示。同样,用户仍然可以点击图中任何一个结点,从而进行又一次新的检索。这样用户就可以根据自己的兴趣在各个本体之间浏览,而右边的视图就是一种根据本体之间的关系而建立的可视化联想导航系统。
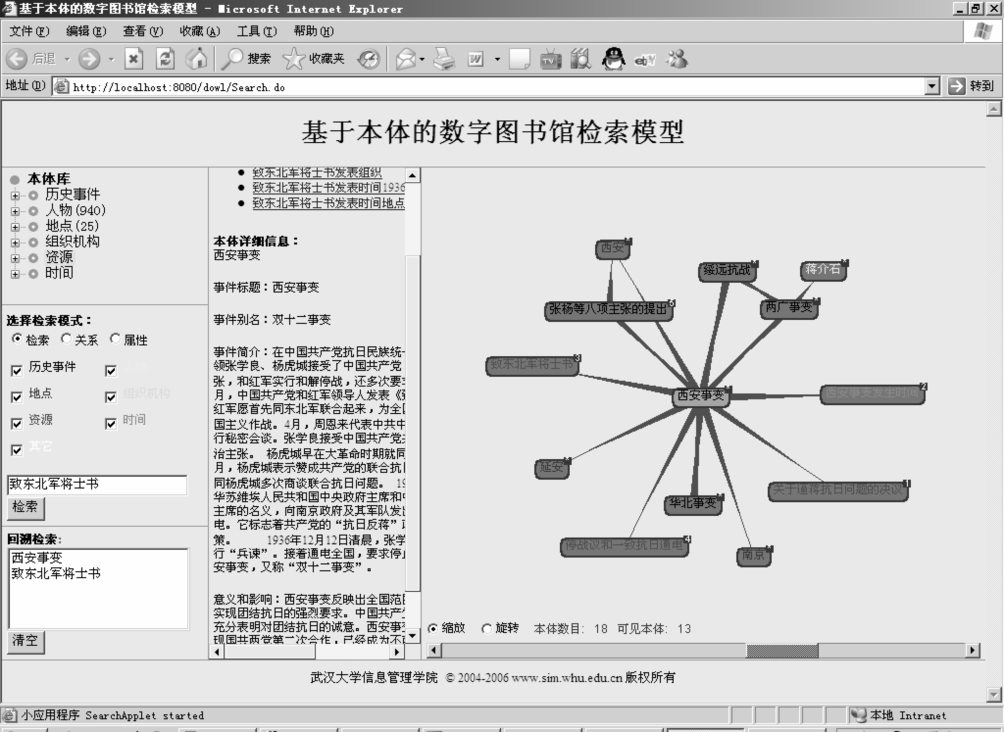
图6-24 点击“西安事变”的结果图
在用户浏览检索的过程中,系统还对视图中的本体个数进行统计。“可见本体”表示视图中可见的本体数目;“本体总数”表示视图中所有(可见和不可见)本体的总数。两者之差表示用户不可见但是缓存在客户端的本体总数。
(2)本体属性检索
本体属性指的是本体实例通过三元组方式表示的语义特征和语义参数。本体实例通常是作为三元组第一元,本体属性是第二元,而本体属性的值是第三元。本体属性通常是描述本体实例细节的语义信息,所以本体属性检索往往是针对用户需要检索本体实例某一方面的知识细节,在检索深度方面要比普通的本体实例检索更具有针对性。这种检索比较适合熟悉该领域的专家来做精确的细节的语义检索。
如检索“周恩来妻子”,传统检索的关键词匹配只能查找到含有这一字符串的信息,当然如果查询的信息空间中只含有“邓颖超”类似的字符串的话,那么用户就无法得到满意的结果。利用关系检索,用户可以在检索输入框中输入“周恩来”,同时选中本体类型为“人物”,从而在相应的关系列表中列出人物本体的相关属性,选中“夫妻关系”属性,那么就能够查找到实例“邓颖超”(如图6-25所示),继续在实例列表中点击“邓颖超”就可查看它的相关信息,对于不同的本体类型,关系列表提供的关系属性也各不相同,如查找事件时,关系属性有:发生地、发生时间、相关事件、起因事件、相关人物等。
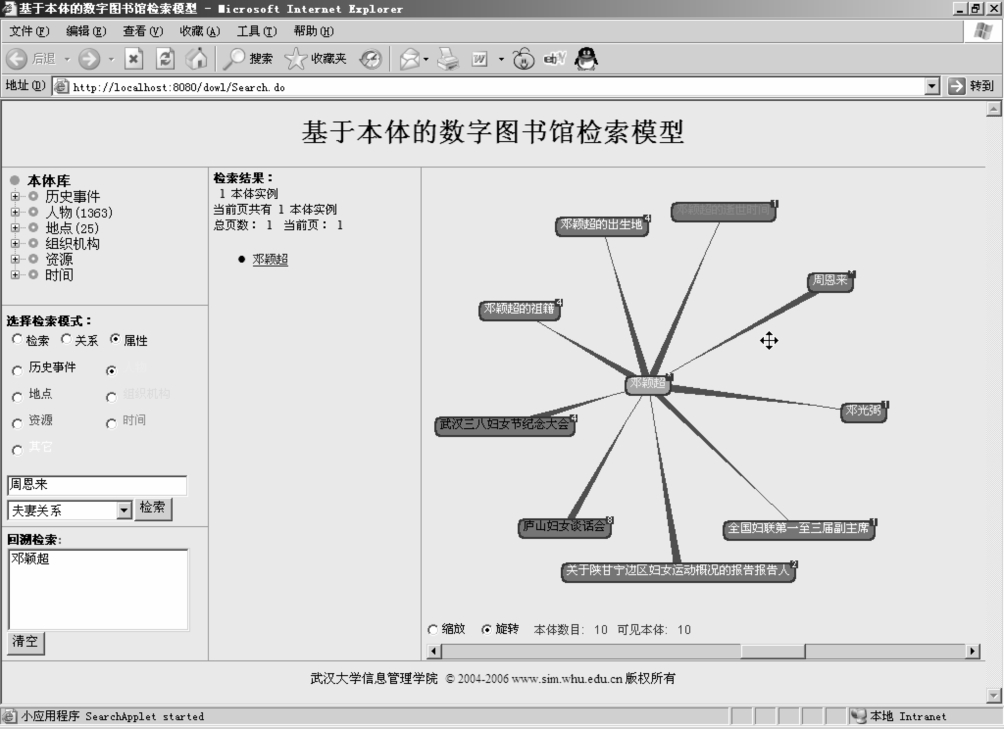
图6-25 本体属性检索图
(3)本体实例与属性检索算法
由于检索效率的原因,我们将本体实例与本体属性检索进行了整合,提供一种通用的检索算法。以下是算法基本思路和步骤:
①通过表单提交的方式,即通过函数public String SearchForOnto(String language,String keyword,String property,HashSet whichOnto,int*curPage,int countPerPage)将要查询的个体名称或者属性名称传入等待处理。
②提交language,keyword,准备得到由查询得到的资源组成的列表。
③如果language:keyword缓存了,直接取得对应的Resource和Score的列表,否则进行④~⑥步。
④我们对lucene分词系统进行修改使之能对中文进行分词。通过对keyword进行分词,得到分词结果。
⑤将分词结果放到索引中查找,得到匹配结果hits对象,hits对象有两个数据,一为匹配实例的uri,一为对应的匹配度分数。
⑥遍历hits对象,得到Resource集合,和相应的匹配度分数Score哈希表,缓存两个集合。
⑦由whichOnto定义的请求目标,过滤Resource集合。
⑧如果property不为空,则进行第⑨步的处理。
⑨由过滤后的Resource集合和property值,得到一个新的Resource集合,这个集合里的Resource对象与原来的集合中的Resource对象之间是property关系,主语或者宾语位置不限定。另外要保存新Resource对象对应的原Resource对象的集合,注意原Resource对象不一定有property属性,多个Resource的property属性可能关联同一个新Resource对象。
⑩由Resource集合的元素个数,curPage,countPerPage生成分页对象。
 由Resource集合和分页对象生成OntoNode集合,注意OntoNode应有区分,如果没有经过步骤⑨的处理,使用OntoNodeForSearch,如果有经过步骤⑨的处理,使用OntoNodeForProp。OntoNodeForProp比OntoNodeForSearch要多一个FromResource域和Property域。(https://www.xing528.com)
由Resource集合和分页对象生成OntoNode集合,注意OntoNode应有区分,如果没有经过步骤⑨的处理,使用OntoNodeForSearch,如果有经过步骤⑨的处理,使用OntoNodeForProp。OntoNodeForProp比OntoNodeForSearch要多一个FromResource域和Property域。(https://www.xing528.com)
 遍历OntoNode集合,查找出所有关系,写成xml元素。
遍历OntoNode集合,查找出所有关系,写成xml元素。
 遍历OntoNode集合,取出所有结点的xml元素,与
遍历OntoNode集合,取出所有结点的xml元素,与 步得到的关系xml元素,一起写入根xml元素中。
步得到的关系xml元素,一起写入根xml元素中。
 将根xml元素转换为String类型,返回。
将根xml元素转换为String类型,返回。
其中由第⑧步判断检索请求是属于本体实例检索还是本体属性检索。
2.本体关系检索
由于我们的本体库是基于复杂的历史领域建立的,各本体实例间存在着复杂的联系。通过本体关系检索,用户可以查找任何两个本体实例是否存在联系,以及这些联系是如何建立起来的。在关系的展现上,是采用连通图的形式,任意两个结点间如果有通路就代表它们之间存在着一定的联系,这些联系不一定是表层的,而可能是通过多层实例相关联建立起来,即非直接相关的实例之间的隐性关系。
(1)本体关系检索用户接口
GGHZ—DL提供一种直接检索两个本体之间的关系的检索模式。比如希望检索出“致东北军将士书”和“红军”这两个本体之间关系。如图6-26所示,在系统左边检索入口部分的“选择检索模式”中选择“关系”,然后在输入框内输入“致东北军将士书”和“红军”并点击“检索”。系统首先在中间部分分别显示它们各自的检索结果,然后提供单选按钮让用户精确选择本体。在检索结果的下方提供了“深度”的选择,基于效率的原因只提供1~3的检索深度,在这里我们选择“深度”为2,然后点击“检索关系按钮”。
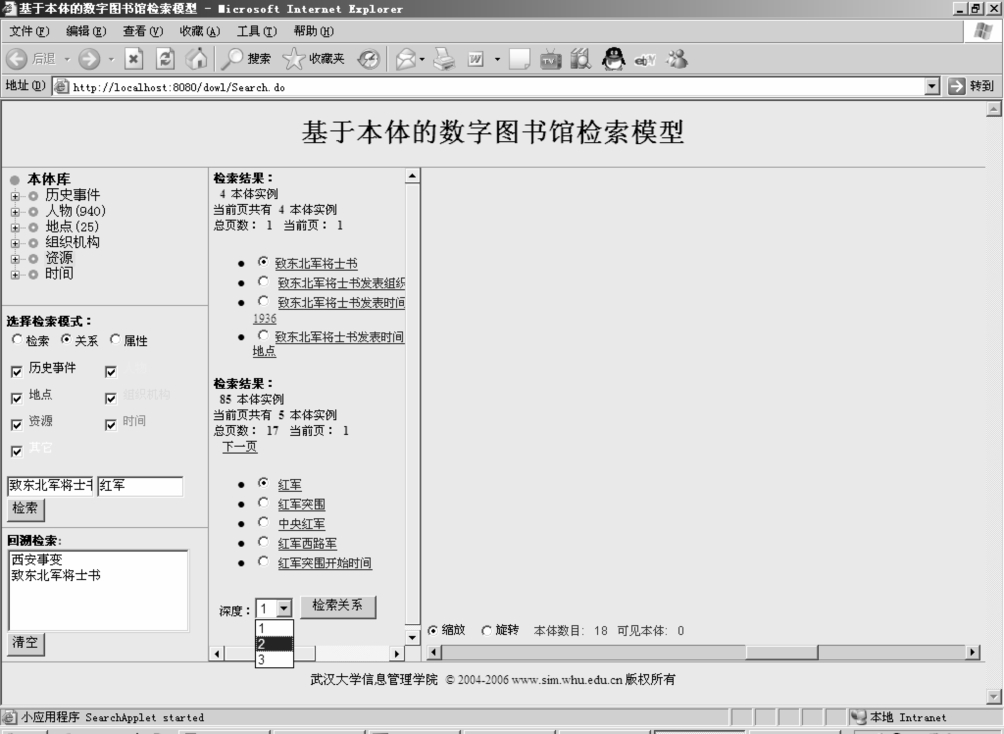
图6-26 本体关系检索图
检索结果如图6-27所示,“红军”和“致东北军将士书”的关系表示为:“致东北军将士书”的“发表组织”是“红军”,而且这两个本体是通过两条边连接在一起,原因是在检索入口选择关系检索的“深度”为2。
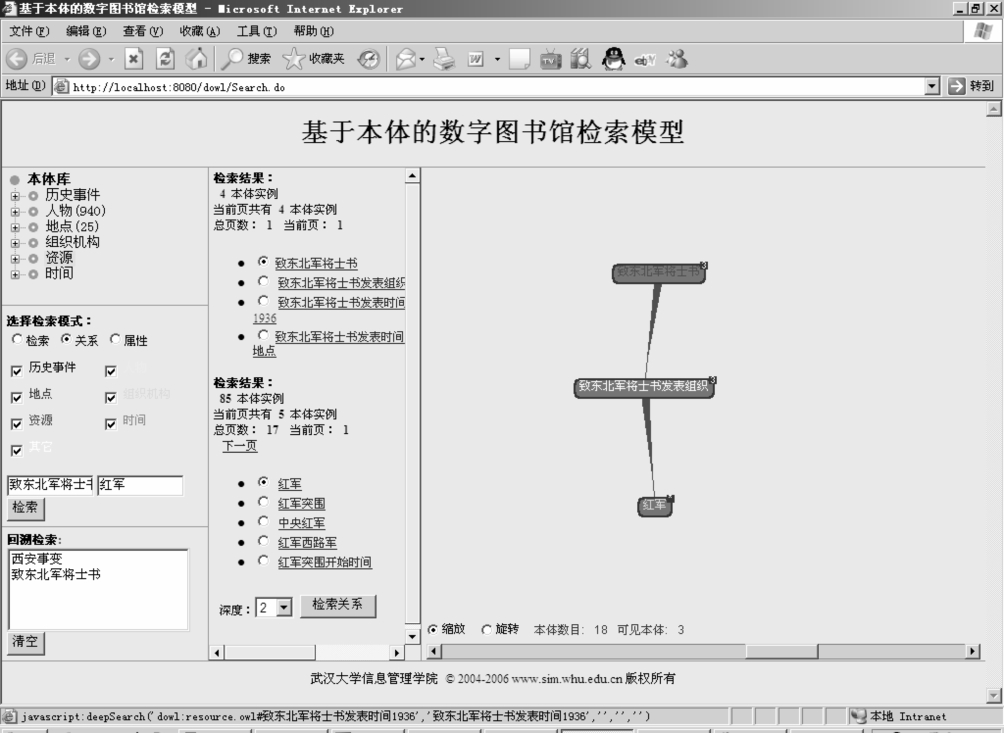
图6-27 本体关系检索图
(2)本体关系检索算法
本体关系检索主要思路是:首先根据用户请求构造RDQL查询字符串组,然后对查询字符串组进行查询,最后将结果返回给用户。
本体关系检索的算法步骤如下:
①通过提交的表单的方式,即通过private String SearchRelation(String language,String Mstr,String Nstr,int depth,String type)参数传进来,接受处理其中String Mstr和String Nstr即为需要检索的两个本体的名称,depth为检索的深度,type为检索的类型。
②通过type判断检索模式,“随机检索”还是“交叉检索”。
③建立相应的RDQL查询字符串数组qsGroup。
④利用qsGroup中的查询字符串进行检索,得到OntoNode集合。
⑤判断OntoNode集合中本体个数是否超过最大限制,如果没有超过继续进行步骤④,如果超过最大限制,则进行步骤⑥。
⑥遍历OntoNode集合,查找出所有关系,写成xml元素。
⑦遍历OntoNode集合,取出所有结点的xml元素,与步骤⑥得到的关系xml元素,一起写入根xml元素中。
⑧将根xml元素转换为String类型,返回到客户端。
3.本体推理检索
基于RDF/OWL的本体由于拥有描述逻辑(Description Logics)的理论支撑,它不仅在知识表示方面有着先天语义优势,而且支持基于规则的本体知识推理。本体推理的本质就是根据本体库中,已经存在的知识和人为定义的规则,推导出库中原来没有的新的本体知识。这些新的本体知识可能是新的本体,也可能是表示本体之间新的关系的三元组。本体推理的结果是生成一个符合推理规则的更大的本体库。而针对这个新的本体库进行的检索就是本体推理检索。
本体推理检索是本系统最有特色的一个检索方式,这种知识层次的推理是以往任何一种信息层次的数据库系统所无法做到的。本系统除了提供本体推理检索的结果之外,还对本体推理路径进行回溯,即利用文本和可视化等方式展现推理过程。
本体推理检索步骤如下:
首先“选择检索模式”为“属性”,然后选择“人物”单选按钮。这样,下拉列表中就列出了“人物”本体的所有属性。我们选择“曾祖母”并且在输入框内输入“毛新宇”,表明我们希望查找“毛新宇”这个人的“曾祖母”是谁。点击“检索”按钮之后,检索出“文七妹”这个人物,继续点击“文七妹”,结果如图6-28(彩图)所示。
这个时候我们发现“毛新宇”和“文七妹”之间的关系是一条橙黄色的边。我们把鼠标放到这条边上,显示的结果是“曾祖母”。这条橙黄色的边表明“曾祖母”关系在原来的本体库中并没有定义,这种关系是通过本体推理而得到的。
如果用户对“曾祖母”这个关系的推理过程感兴趣,可以对这条橙黄色的边点击右键,在弹出对话框里面选择“展开关系”,这样就能得到推理过程,如图6-29(彩图)所示。
原来橙黄色的“曾祖母”关系的边已经变成黄色,表明它已经被展开。展开之后视图中出现了3条粉红色的边,这三条边把“毛新宇”、“毛岸青”、“毛泽东”、“文七妹”这四个本体连接了起来。我们把鼠标放到任何一个粉红色的边上来查看它的标签,显示的结果是“子女有”。通过这种可视化的表现方式,用户能够形象地了解推理的过程:由于“文七妹”的“子女有”“毛泽东”,“毛泽东”的“子女有”“毛岸青”,“毛岸青”的“子女有”“毛新宇”,而且“文七妹”是女性,所以推理出“毛新宇”的“曾祖母”是“文七妹”。另外,在展开推理关系之后,在系统的中间部分还显示出“推理路径回溯”的相关文字说明,主要包括“推理规则”和“推理依据”。
本体推理的核心是推理规则的定义。规则定义的好坏,决定了最终本体推理检索的语义效果。事实上,规则定义和本体建库一样,也还是一个领域问题。本系统的规则库是本体开发人员与领域专家共同努力的结果(我们邀请了华中师范大学近现代史研究所的两位博士生参与本体规则定义。在整个过程中,他们细致而专业的历史理论支持给了我们很大的帮助)。
系统总共定义推理规则96条,本文中“曾祖母”的例子所应用的推理规则如下:
#RULE:曾祖母推理关系
[gradeGrandMaRule:(?x indiv:beParentOf?y),(?y indiv: beParentOf?z),(?z indiv:beParentOf?w),(?x indiv:gender'女')->(?x indiv:beGGM?w)]
4.本体回溯检索
回溯检索是来自于传统情报学检索的概念。用户的检索过程被记录在系统左下角的“回溯检索”列表里面。也就是说列表里面的是用户曾经检索过的本体,用户可以通过这个列表实现回溯检索。事实上用户每次的检索结果都在客户端进行了缓存,执行“回溯检索”并不向服务器发出重复的请求,这样既能提高检索效率又能减轻服务器压力。“回溯检索”列表下面有一个“清空”按钮,它的作用就是清除客户端的缓存,等价于开启一个新的检索会话。
5.关键词检索
GGHZ—DL只提供一种元数据回溯模型,它的基本思路是通过本体实例检索或者关系检索所检索到的本体知识反过来回溯知识所在的原始文档,从而查看更加详细的文字信息。
比如用户在GGHZ—DL中检索到“西安事变”与“张学良”两个本体,也能得到“张学良”是“西安事变”的“参与角色”这样的知识。但是用户也许会希望进一步检索包含“张学良”和“西安事变”的一次文献来更深入了解详细情况。GGHZ—DL提供一种快捷的回溯方法,直接对两个本体之间的关系点击右键,选择“关键词检索”。这样就能在系统界面中部得到一个文献列表,列表中的文献就是满足“张学良”AND“西安事变”这样的关键词检索的PDF格式的文档,如图6-30所示。再点击比如“西安事变与张、杨等八项主张的提出”,就可以直接打开PDF文档,并且PDF文档中的“张学良”和“西安事变”都高亮显示,如图6-31所示。
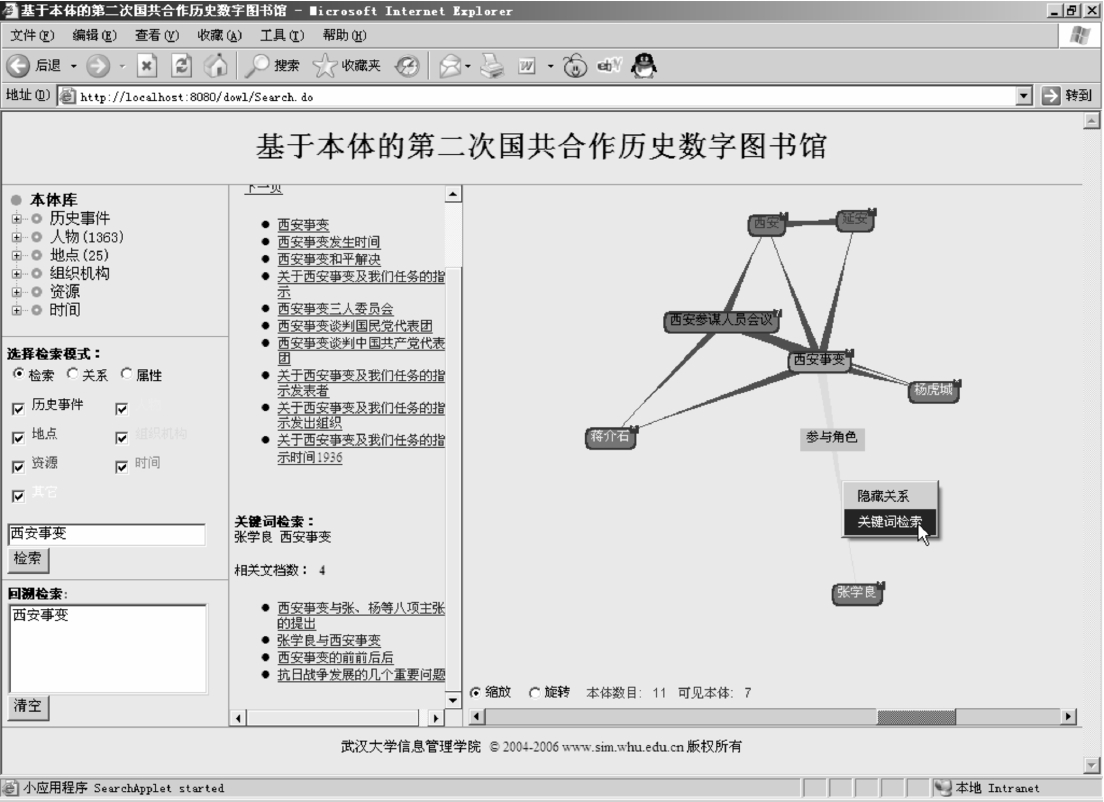
图6-30 关键词检索图
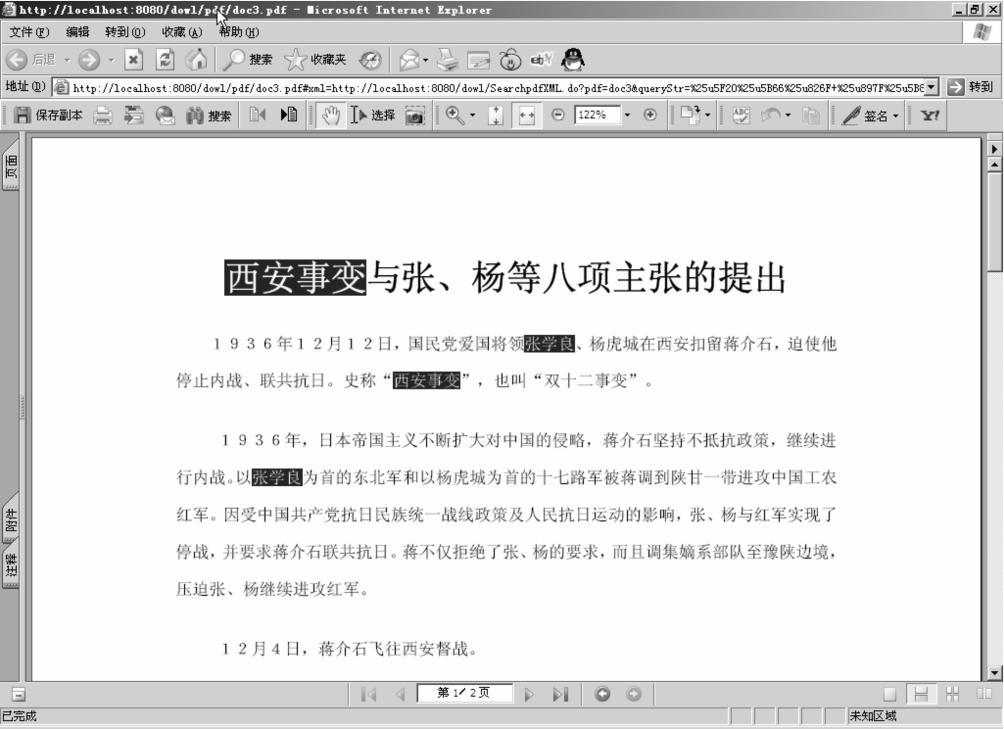
图6-31 PDF原始文档以及关键词高亮显示图
这种模式的元数据回溯可以支持各种元数据属性,比如“标题”,“关键词”,“摘要”,等等。GGHZ—DL采取的方式是索引只关联“标题”字段,而回溯可以到全文。这样做既可以减少索引量又能提供全文,是比较折中的方案。当然如果需要其他的元数据字段,可以稍做修改,技术实现上是一样的。
6.基于本体的检索模型和传统检索模型的区别
从上述介绍中可以看出,GGHZ—DL用户在检索过程中的流程实质上如图6-32所示。用户首先检索到的是本体实例检索或本体关系检索得到的显性形式化的知识,或者是本体推理检索得到的智能推理隐性知识,然后再通过元数据回溯检索具有相关元数据的一次文献或数字资源。简而言之,思路是由知识检索到回溯文档。
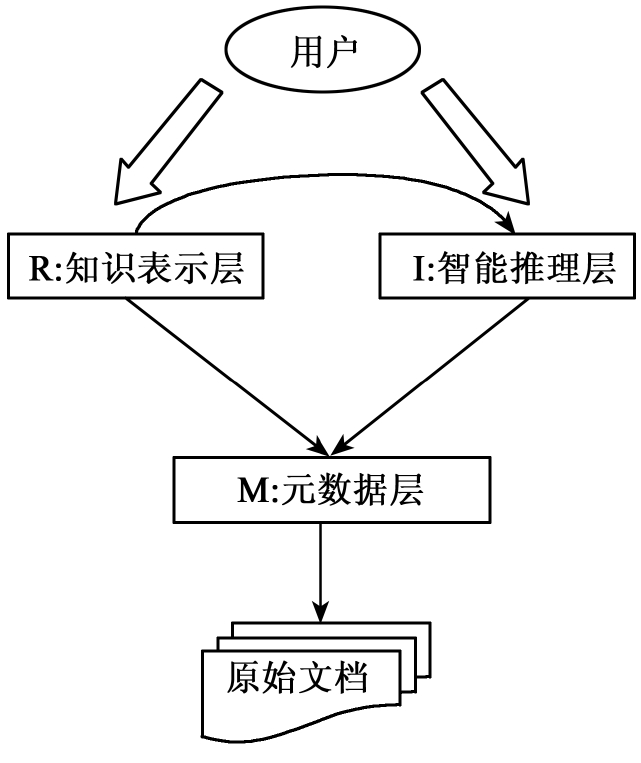
图6-32 GGHZ—DL模型检索流程图
而传统数字图书馆检索通常是以元数据作为检索入口,提供布尔模型或概率模型,检索到一次文献文档,然后让用户去阅读文档的全文(如图6-33所示)。分析文档、理解文档中的显性知识和推理文档中的隐性知识都由用户自己完成,这给用户造成了巨大的负担。由于用户的知识水平差异,一次文献描述知识能力的局限性,用户往往会遇到引言中所说的“忠实表达”、“表达差异”、“词汇孤岛”等问题。
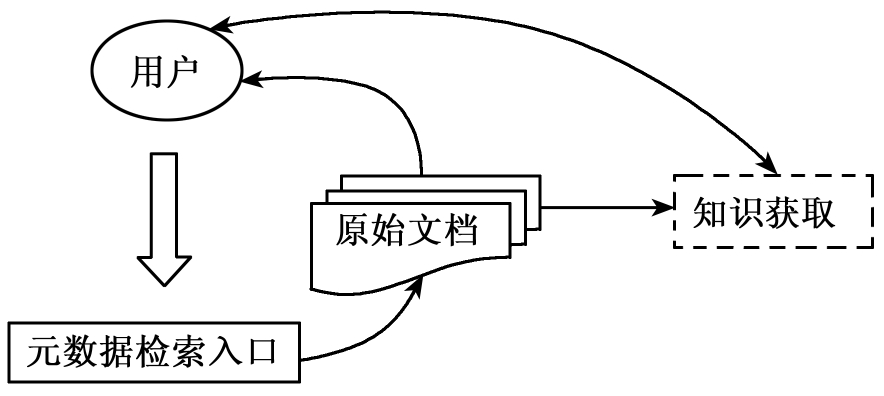
图6-33 传统检索流程图
相比较而言,GGHZ—DL检索模型直接获取知识的这种模式对用户来说非常方便,而且通过提供元数据回溯的方式,使用户也能够检索到原始文档。这种区别于传统检索的逆向回溯方式更符合用户检索思路和习惯。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。