



主成分分析(Principal Component Analysis,PCA)算法是一种经典的统计方法。这种线性变化被广泛地应用在数据压缩和分析中。PCA算法就是用来描述和表征细微差异的有力工具。在语音和图像信号处理时,经常会遇到高维的向量空间的数据处理问题,而这些高维数据往往存在较大程度的相关冗余,所以希望从高维空间的数据中找出具有代表性的低维子空间,从而对数据更容易地进行分析和处理。在最大程度上保持信息量的前提下,从高维数据空间中提取出维数降低的特征分量。在信号处理和模式识别中,PCA算法相当于采用奇异值分解(SVD)和K-L变换。
1.K-L变换的基本原理
在这里,所讨论的面部表情图像是经过大小归一化等预处理后的灰度数据图像。把一幅面部表情图像按行或列排列为一个向量,称为“面部表情向量”;由多个图像所组成的空间称为“原始图像空间”。
然而,由于人脸固有的相似性,在“原始图像空间”中,面部表情向量仅分布在一个较小的范围内,所以“原始图像空间”不是最优的。为了有效地提取面部表情图像特征,人们用K-L变换进行统计特征提取。它是图像压缩中的一种最优正交变换,同时也是子空间法模式识别的基础。若将K-L变换用于表情识别,则需假设面部表情处于低维线性空间,且不同面部表情具有可分性。由于高维图像空间经过K-L变换后可得到一组新的正交基,因此可通过保留部分正交基,以生成低维面部表情空间,而低维空间的正交基则可通过分析面部表情训练样本集的统计特性来获得。K-L变换的生成矩阵可以是训练样本集的总体散布矩阵,也可以是训练样本集的类间散布矩阵,即可采用同一表情的数张图像的平均来进行训练,这样可在一定程度上消除光线等的干扰,且计算量也得到减少,而识别率不会下降。
2.K-L变换的算法
假设训练的每幅面部表情图像的像素数为d,共有k幅训练样本,则所有训练样本的向量集合记为X={Xi∈Rd|i=1,2,…,k},列向量是由面部表情数据按照行首尾连接得到的。这样X对应一个d×k维的人脸空间。K-L变换试图找到一个低维的子空间来表示原来的面部表情空间。记
为集合中训练面部表情数据的平均向量。将X中每一个人脸数据向量减去平均向量,可以得到一个新的向量集合: ,其中
,其中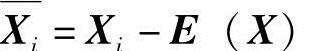
集合X的协方差矩阵可以表示为
式中,C是一个d×d的矩阵。C的特征向量构成了一组Rd空间的正交基。这组基叫做K-L基。我们记这组正交的特征向量为u1,u2,…,ud,其对应的全部特征值分别为λ1,λ2,…,λd,特征向量按列形成的矩阵为U,那么在特征空间,面部表情向量X的投影为
Y=UT(X-E(X)) (6-3)
若通过选用m(m<d)个特征向量作为正交基,记其矩阵为U,则在特征空间的子空间中可得到近似表达式为
Y≈UT(X-E(X)) (6-4)
将子空间的正交基按照图像阵列排列,可以看出这些正交基呈现人脸的形状,因此这些正交基也被称为特征脸(Eigenface),这种表情识别方法也叫特征脸方法。
3.正交基的选取
关于正交基的选择有不同的考虑,即与较大特征值对应的正交基(也称主分量)可用来表达人脸的大体形状,采用主分量作正交基的方法称为主成分分析(PCA)算法。对于集合X中的一个面部表情向量x,PCA就是将向量x投影到与协方差矩阵C的、按降序排列的前m个特征值对应的特征向量所张成的子空间上。投影产生了一个包含m个系数a1,a2,…,am的向量。这样面部表情向量x就表达成特征向量的线性组合,其权值就是a1,a2,…,am。可以证明,主成分分析算法的重构误差等于被忽略的特征向量所对应的特征值(即λm+1,λm+2,…,λd)的和。由此可见,PCA算法具有较好的图像重构功能。
另一种选择是采用m个次分量作为正交基。原因是所有人脸的大体形状和结构相似,真正用来区分不同面部表情的信息是用次分量表达的高频成分;主分量更适用于表达图像的低频成分,具体细节还需要用与小特征值对应的特征向量(也称次分量)来加以描述。因此也可理解为低频成分用主分量表示,而高频成分用次分量表示。(https://www.xing528.com)
4.投影空间的图像分类
由训练得到特征脸后,将待识别面部表情图像投影到新的m维表情空间,即用一系列特征脸的线性加权和来表示它。这样即得到一个投影系数向量来代表待识别的面部表情,这时表情识别问题就转化为m维空间的坐标系数向量分类问题,最简单的分类标准是距离判别法。
假设两个n维向量x=(x1,x2,…,xn)T和y=(y1,y2,…,yn)T之间的距离为S(x,y),常用的距离度量有以下几种方法:
● L1距离(City block Distance)
● L2距离(欧氏距离,Duclidean Distance)
● 向量夹角(Angle)
这些基本的距离还可以结合起来使用。
选择好适当的距离度量以后,就要选择适当的距离分类器。以下是常用的距离分类器:
● 最紧邻(Nearest Neighbor)分类器:是最常用的分类器,即把待识别的样本归为与之最近的已知样本所在的类。
●K近邻(K Nearest Neighbor)分类器:分类器取待识别样本的K个近邻,这K个近邻中属于哪一类的已知样本多,则把待识别样本归为哪一类。
● 近邻中心(Nearest Center)分类器:首先把要求得到的已知样本类平均(类中心),把待识别样本归为与之最近的类中心所在的类。
基于K-L变换的特征脸识别方法用于表情识别的基本原理是:假设人脸处于低维线性空间,且不同面部表情具有可分性,将高维图像空间的面部表情图像经K-L变换后得到一组新的正交基,通过分析面部表情训练样本集的统计特性保留部分正交基,以生成低维面部表情空间。K-L变换的生成矩阵可以是训练样本集的总体散布矩阵,也可以是训练样本集的类间散布矩阵,这样不仅在一定程度上消除光线等的干扰,而且在不降低识别率的前提下有效地减少了计算量。根据总体散布矩阵或类间散布矩阵可求出一组正交的特征向量u1,u2,…,un,其对应的全部特征值分别为λ1,λ2,…,λn,这样在新的正交空间中,面部表情样本X就可以表示为
若通过选用m(m<n)个特征向量作为正交基,则在该正交空间的子空间中,就可得到以下近似表达式:
由训练得到特征脸后,将待识别面部表情投影到新的m维空间,即用一系列特征脸的线性加权和来表示它,这样即得到一个投影系数向量来代表待识别的面部表情。此时,表情识别问题就转化为m低维空间的坐标系数向量分类问题。
PCA算法提供了一种在控制信息损失和简化问题之间取得折中的有效方式。它能够把高维的数据进行有效降维,用能表征数据特征的低维向量来代替原始的高维数据,给数据的处理带来了很大方便。但是,PCA算法在进行计算时,事先需要全部的数据,并且矩阵运算的运算量较大,在存在不良数据时,计算出的主分量和实际值会有较大的误差。目前关于PCA算法研究相当一部分都在进行PCA算法稳健性方面的探索和改进。考虑PCA算法稳健性主要在两个方面:怎么减少计算误差:在输入信号不服从正态分布情况下,如何使输出的主分量相互独立,主要方法就是引入非线性函数。非线性函数的引入可以提高PCA算法的稳健性,这些非线性函数根据输入样本的变化,对变换矩阵的步长做相应的调整,使算法更加稳健。但是如何选择和引入非线性函数,在理论上仍然没有比较完美的解决方案。另外,PCA算法对藏于数据中的独立噪声没有很好的稳健性。这是因为PCA算法把输入数据的方差进行了最大化,从而保留了一些并不想要的变量。因此PCA算法空间中不同类别的数据的投影常常会模糊不清。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。