



人脸识别系统的总体设计框架如图9-2所示。
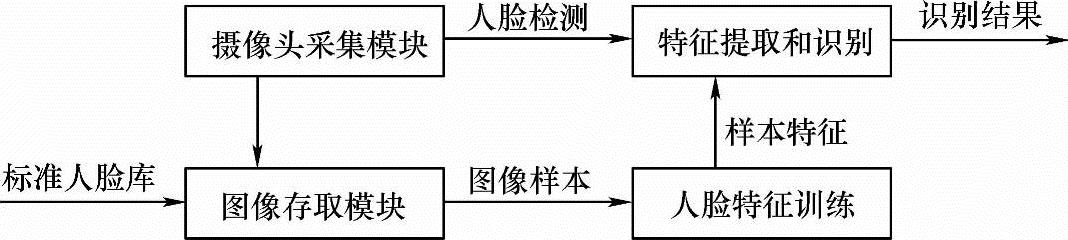
图9-2 人脸识别系统的总体总计框架
1.摄像头采集模块
摄像头采集模块直接采用微软公司提供的VFW SDK。VFW是微软公司1992年推出的关于数字视频的一个软件包,它能使应用程序通过数字化设备从传统的模拟视频源得到数字化的视频剪辑。VFW主要由以下六个模块组成:
(1)AVICAP.DLL 包含执行视频捕获的函数,它给音频视频交错格式(AVI)文件的I/O处理和视频、音频设备驱动程序提供一个高级接口。
(2)MSVIDEO.DLL 包含一套特殊的DrawDib函数,用来处理屏幕上的视频操作。
(3)MCIAVI.DRV 包括对VFW的多媒体控制接口(MCI)命令解释器的驱动程序。
(4)AVIFILE.DLL 包含由标准多媒体I/O(mmio)函数提供的更高的命令,用来访问AVI文件。
(5)压缩管理器(ICM) 用于管理视频压缩/解压缩的编译码器(Codec)。
(6)音频压缩管理器(ACM) 提供与ICM相似的服务,适用于波形音频。
AVICap窗口类支持实时的视频流捕获和单帧捕获,并提供对视频源的控制。它能直接访问视频缓冲区,不需要生成中间文件,实时性很强,效率很高,而且它还可将数字视频捕获到一个文件中。
捕获窗类似于标准控件(如按钮、列表框等),并具有下列功能:
1)将视频流和音频流捕获到一个AVI文件中;
2)动态地同视频和音频输入器件连接或断开;(https://www.xing528.com)
3)以Overlay(叠加)或Preview(预览)模式对输入的视频流进行实时显示;
4)在捕获时,可指定所用的文件名,并能将捕获文件的内容复制到另一个文件中;
5)设置捕获速率;
6)显示控制视频源、视频格式、视频压缩的对话框;
7)创建、保存或载入调色板;
8)将图像和相关的调色板复制到剪贴板上;
9)将捕获的单帧图像保存为与设备无关位图(DIB)格式的文件。
使用捕获窗回调函数,一帧一帧地获得视频数据,或以流的方式获得视频数据,这些数据进一步送到存储模块进行存储,或者送到人脸检测和识别模块去做识别处理。
2.图像存取模块
为了有效地管理大量图像数据,创建了database类和person类。database类中包含数据的两种来源方式:①来自文件夹;②来自SQL Server,只要稍做设置,就能更改这种来源方式。而且database类维护了一个人的链表,保存了所有person类的对象,提供了修改此链表方法(比如增加、删除、查找等)的接口,除了从摄像头采集图像来新建person对象外,还提供了一个方便的功能,就是直接读取标准人脸库中的图像来新建person对象。person类表示一个人,它能够存取数据库,它内部维护一个图像样本链表,提供增加、删除等接口,对文件夹和数据库软件提供不同的读取(Load)图像和保存(Save)图像方法,并且其内部有一个特征类对象,如果这个person类对象的图像样本经过训练,那么这个特征类对象将会保存此样本的特征值,在识别时将会用到。
对于直接的硬盘文件存取,采用OpenCV提供的图像读取和保存函数,这些函数方便地实现了BMP、JPG、GIF等各种图像的读取和保存。对于数据库存取方式,把图像数据块当成二进制数据存储到数据库表中的一个二进制字段中,在读取时,把这些二进制数据从数据库中读取,然后当作一个内存文件使用OpenCV的函数进行装载。
3.人脸检测及特征提取和识别模块
系统要求是实时的人脸识别,所以人脸检测部分需要尽量地节省时间,但是又要保证较高的检测率、尽量小的误识率。对比最常用的两种人脸检测方法:肤色模型法和Haar(哈尔)特征法。肤色建模方法的算法简单、速度快,能够保证较高检测率,但是其致命缺点是有较高的误识率,也就是说如果有人脸,这种方法能保证很高的几率检测出来,但是这种方法无法区分人脸和非人脸肤色部分,经常出现的结果是,脖子和手臂都当成人脸区域,严重影响后续的识别步骤。这个缺点也能够使用一些方法进行修正,比如利用人脸的对称性,再次对类人脸区域进行判别,最终是延长处理时间、降低误识率,对于我们的实时人脸识别系统,这种方法没有很好的评判标准,检测到假人脸区域太多,最终采用了拥有高检测率、低误识率的基于Harr特征的人脸检测方法,结合利用视频图像相关性改进图像待处理区域,减少了处理时间,满足了要求,在下节我们对此将具体阐述。
经过长期研究发现,在众多的人脸识别算法中,HMM人脸识别方法为描述不同的表象之间提供了联系,不但整体描述人脸的数值,而且为不同姿态的人脸之间描述了联系。它提供了描述复杂现象的一种可能机制。按照这种模型,观测到的一列特征(例如描述脸庞的一组数值特征)被看成是另一组不可观测的(因此是隐性的)“状态”产生出的一列实现。状态既然是不可观测的,它的个数是未知的,但可以假定。选择状态个数的多少必须在模型的复杂性和描述复杂现象准确度之间进行折中。一个合理的或好的隐马尔可夫模型应该是这样的:给定一组观测序列,从关于状态的适当的一组初始分布出发,能够产生出一组实现序列,它非常好地逼近给定的观测序列。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。